クロスクラスター複製
クロスクラスター複製を使用すると、次の目的でインデックスをクラスター間で複製できます:
- データセンターの障害が発生した場合でも検索リクエストを処理し続ける
- 検索ボリュームがインデックススループットに影響を与えるのを防ぐ
- ユーザーに地理的に近い場所で検索リクエストを処理することにより、検索レイテンシを削減する
クロスクラスター複製はアクティブ-パッシブモデルを使用します。リーダーインデックスにインデックスを作成し、データは1つ以上の読み取り専用フォロワーインデックスに複製されます。フォロワーインデックスをクラスターに追加する前に、リーダーインデックスを含むリモートクラスターを構成する必要があります。
リーダーインデックスが書き込みを受け取ると、フォロワーインデックスはリモートクラスターのリーダーインデックスから変更を取得します。フォロワーインデックスを手動で作成することも、自動フォローのパターンを構成して新しい時系列インデックスのフォロワーインデックスを自動的に作成することもできます。
クロスクラスター複製クラスターは、一方向または双方向のセットアップで構成します:
- 一方向の構成では、1つのクラスターにはリーダーインデックスのみが含まれ、もう1つのクラスターにはフォロワーインデックスのみが含まれます。
- 双方向の構成では、各クラスターにはリーダーインデックスとフォロワーインデックスの両方が含まれます。
一方向の構成では、フォロワーインデックスを含むクラスターは、リモートクラスターと同じか新しいバージョンのElasticsearchを実行している必要があります。新しい場合、バージョンは次のマトリックスに示すように互換性がある必要があります。
バージョン互換性マトリックス
| ローカルクラスター | |||||||||
| リモートクラスター | 5.0–5.5 | 5.6 | 6.0–6.6 | 6.7 | 6.8 | 7.0 | 7.1–7.16 | 7.17 | 8.0–8.15 |
| 5.0–5.5 |  |
 |
|||||||
| 5.6 | |||||||||
| 6.0–6.6 | |||||||||
| 6.7 | |||||||||
| 6.8 | |||||||||
| 7.0 | |||||||||
| 7.1–7.16 | |||||||||
| 7.17 | |||||||||
| 8.0–8.15 |
マルチクラスターアーキテクチャ
クロスクラスター複製を使用して、Elastic Stack内に複数のマルチクラスターアーキテクチャを構築できます:
- プライマリクラスターが失敗した場合の災害復旧、セカンダリクラスターがホットバックアップとして機能
- データのローカリティを維持し、アプリケーションサーバー(およびユーザー)に近い場所にデータセットの複数のコピーを保持し、高価なレイテンシを削減
- 集中型レポートを使用して、複数の地理的に分散したElasticsearchクラスターをクエリする際のネットワークトラフィックとレイテンシを最小限に抑えたり、検索負荷がインデックスに干渉しないように、検索をセカンダリクラスターにオフロードする
クロスクラスター複製ウェビナーを視聴して、次のユースケースについて詳しく学びます。その後、クロスクラスター複製を設定し、ウェビナーのデモを実行します。
これらのユースケースのすべてにおいて、すべてのクラスターでセキュリティを構成する必要があります。災害復旧のためにクロスクラスター複製を構成する際に、セキュリティ構成は複製されません。Elasticsearch securityの機能状態がバックアップされることを確認するために、スナップショットを取得することを定期的に行ってください。その後、セキュリティ構成からネイティブユーザー、ロール、およびトークンを復元できます。
災害復旧と高可用性
災害復旧は、ミッションクリティカルなアプリケーションにデータセンターや地域の障害に耐える耐性を提供します。このユースケースは、クロスクラスター複製の最も一般的な展開です。災害復旧と高可用性をサポートするために、異なるアーキテクチャでクラスターを構成できます:
単一の災害復旧データセンター
この構成では、データが本番データセンターから災害復旧データセンターに複製されます。フォロワーインデックスがリーダーインデックスを複製するため、本番データセンターが利用できない場合、アプリケーションは災害復旧データセンターを使用できます。

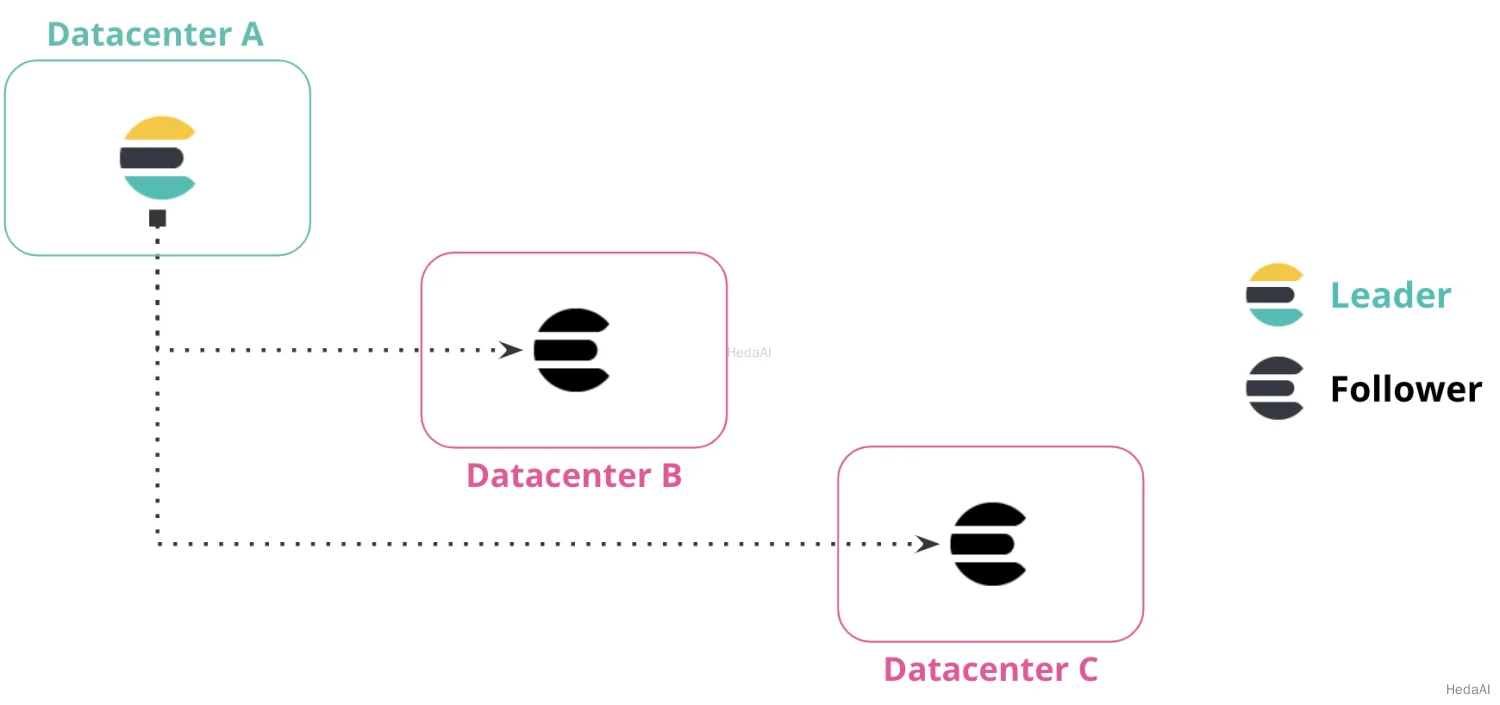
複数の災害復旧データセンター
1つのデータセンターから複数のデータセンターにデータを複製できます。この構成は、災害復旧と高可用性の両方を提供し、プライマリデータセンターがダウンまたは利用できない場合にデータが2つのデータセンターに複製されることを保証します。
次の図では、データセンターAからデータセンターBおよびデータセンターCにデータが複製され、両方のデータセンターにはデータセンターAのリーダーインデックスの読み取り専用コピーがあります。
チェーン複製
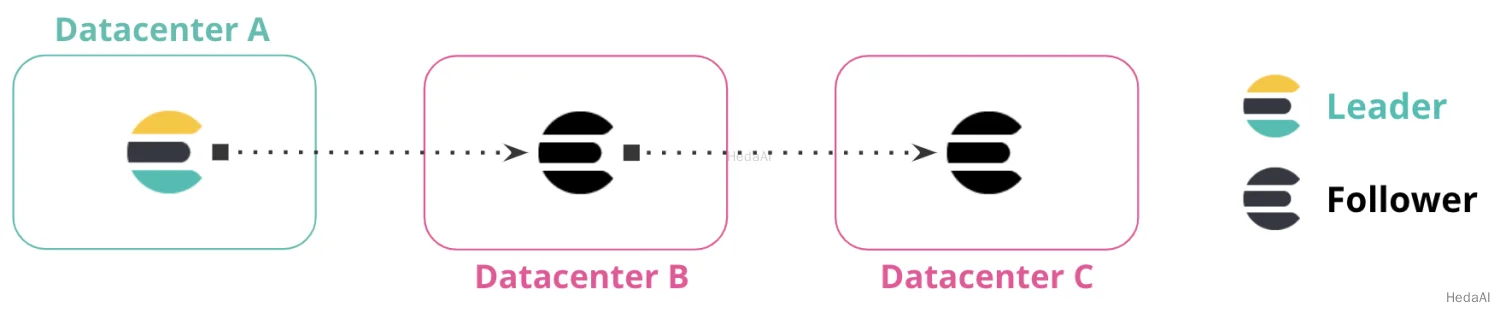
複数のデータセンター間でデータを複製して複製チェーンを形成できます。次の図では、データセンターAにリーダーインデックスが含まれています。データセンターBはデータセンターAからデータを複製し、データセンターCはデータセンターBのフォロワーインデックスから複製します。これらのデータセンター間の接続は、チェーン複製パターンを形成します。
双方向複製
この構成では、クラスターまたはデータセンターが利用できない場合に手動介入は必要ありません。次の図では、データセンターAが利用できない場合、手動フェイルオーバーなしでデータセンターBを引き続き使用できます。データセンターAがオンラインになると、クラスター間の複製が再開されます。
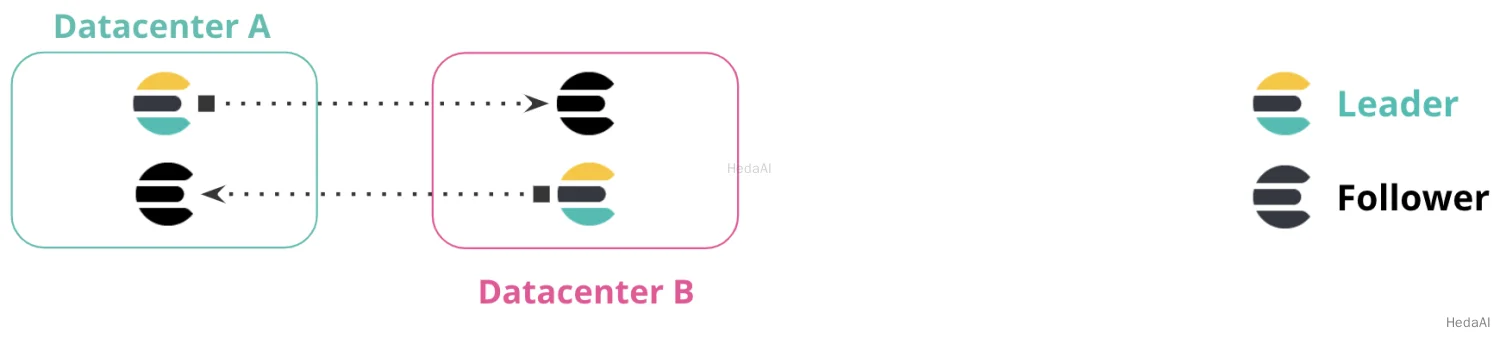
この構成は、ドキュメント値の更新が発生しないインデックス専用のワークロードに特に便利です。この構成では、Elasticsearchによってインデックスされたドキュメントは不変です。クライアントは各データセンターにElasticsearchクラスターとともに配置され、異なるデータセンターのクラスターとは通信しません。
データのローカリティ
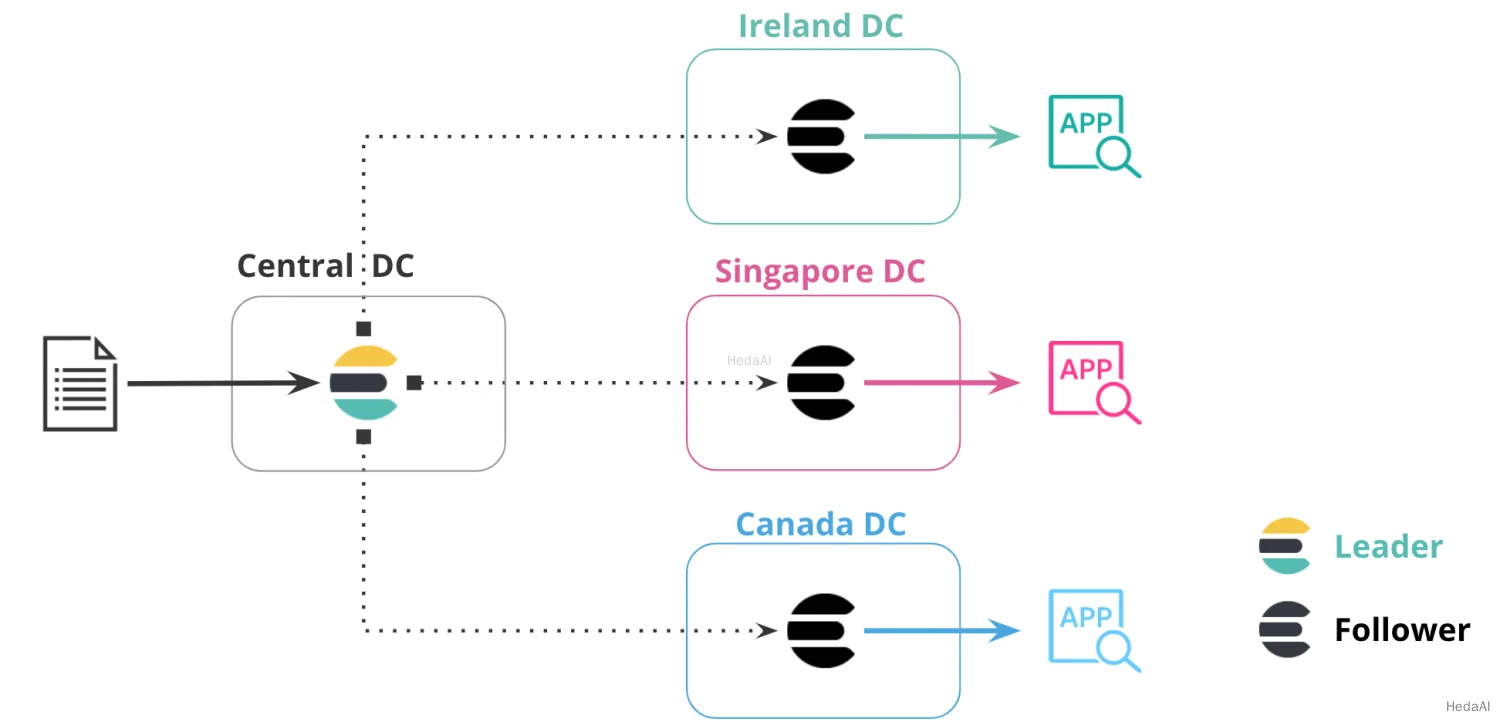
データをユーザーやアプリケーションサーバーに近づけることで、レイテンシと応答時間を削減できます。この方法論は、Elasticsearchでデータを複製する際にも適用されます。たとえば、製品カタログや参照データセットを世界中の20以上のデータセンターに複製して、データとアプリケーションサーバーの距離を最小限に抑えることができます。
次の図では、データが1つのデータセンターから3つの追加データセンターに複製され、それぞれが独自の地域にあります。中央のデータセンターにはリーダーインデックスが含まれ、追加のデータセンターにはその特定の地域でデータを複製するフォロワーインデックスが含まれています。この構成により、データがアクセスするアプリケーションに近づきます。
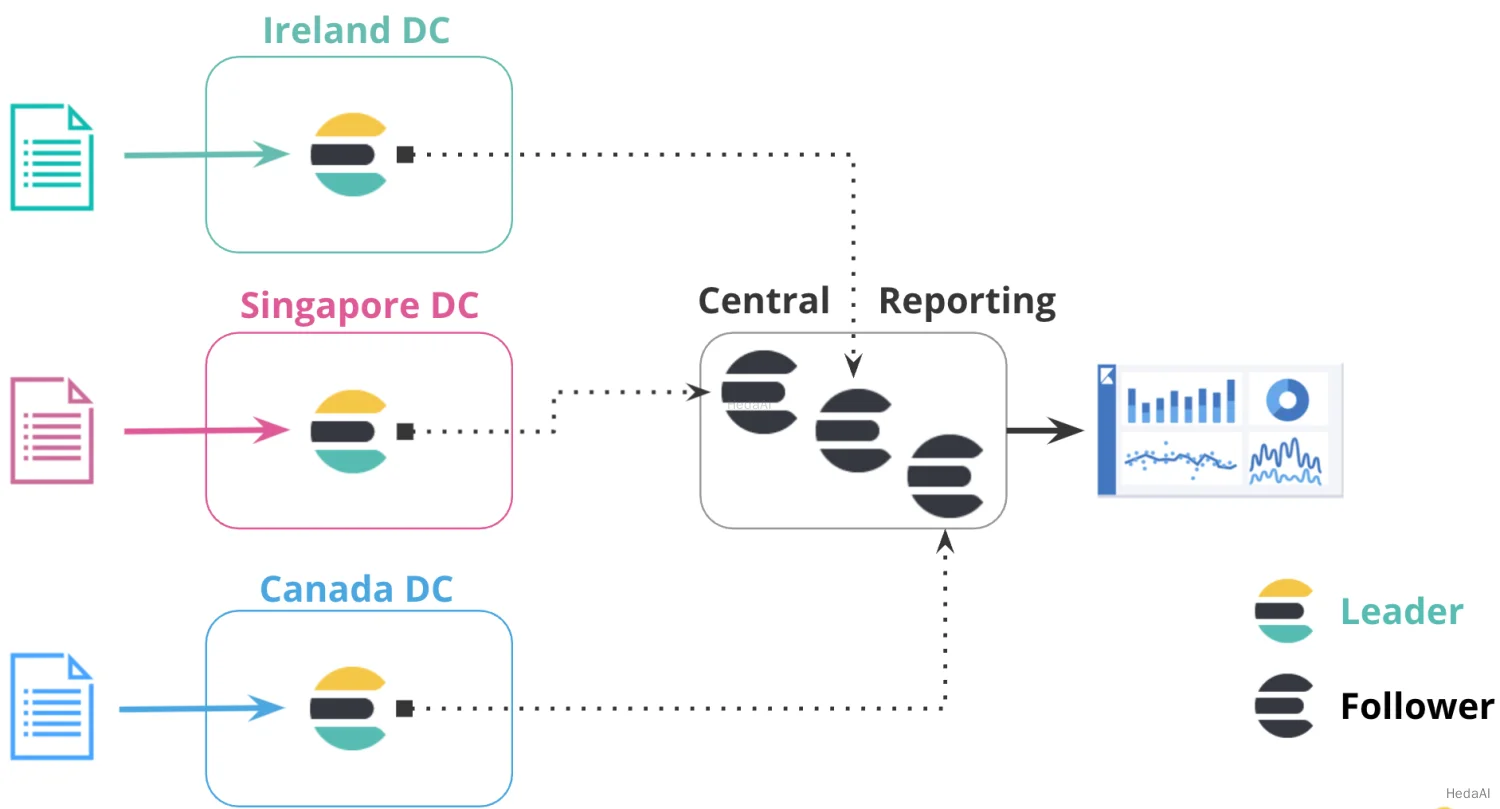
集中型レポート
集中型レポートクラスターを使用すると、大規模なネットワークを横断してクエリする際の非効率性を解消できます。この構成では、多くの小さなクラスターから集中型レポートクラスターにデータを複製します。
たとえば、大規模なグローバル銀行は、世界中に100のElasticsearchクラスターを持ち、各銀行支店のために異なる地域に分散しています。クロスクラスター複製を使用して、銀行はすべての100の銀行からイベントを中央クラスターに複製し、レポートのためにローカルでイベントを分析および集約できます。ミラークラスターを維持する代わりに、銀行はクロスクラスター複製を使用して特定のインデックスを複製できます。
次の図では、異なる地域の3つのデータセンターからデータが集中型レポートクラスターに複製されます。この構成により、地域のハブから中央クラスターにデータをコピーし、すべてのレポートをローカルで実行できます。
複製メカニクス
クロスクラスター複製を設定する際、インデックスレベルで設定しますが、Elasticsearchはシャードレベルで複製を実現します。フォロワーインデックスが作成されると、そのインデックス内の各シャードはリーダーインデックスの対応するシャードから変更を取得します。つまり、フォロワーインデックスはリーダーインデックスと同じ数のシャードを持ちます。リーダーでのすべての操作は、フォロワーによって複製されます。たとえば、ドキュメントを作成、更新、または削除する操作などです。これらのリクエストは、リーダーシャードの任意のコピー(プライマリまたはレプリカ)から提供できます。
フォロワーシャードが読み取りリクエストを送信すると、リーダーシャードは、フォロワーインデックスを構成する際に設定した読み取りパラメータによって制限された新しい操作で応答します。新しい操作が利用できない場合、リーダーシャードは新しい操作を待つために設定されたタイムアウトまで待機します。タイムアウトが経過すると、リーダーシャードはフォロワーシャードに新しい操作がないことを応答します。フォロワーシャードはシャード統計を更新し、すぐにリーダーシャードに別の読み取りリクエストを送信します。この通信モデルは、リモートクラスターとローカルクラスター間のネットワーク接続が常に使用されることを保証し、ファイアウォールなどの外部ソースによる強制的な切断を回避します。
読み取りリクエストが失敗した場合、失敗の原因が調査されます。失敗の原因が回復可能(ネットワーク障害など)と見なされる場合、フォロワーシャードは再試行ループに入ります。それ以外の場合、フォロワーシャードは再開するまで一時停止します。
更新の処理
フォロワーインデックスのマッピングやエイリアスを手動で変更することはできません。変更を行うには、リーダーインデックスを更新する必要があります。フォロワーインデックスは読み取り専用であるため、すべての構成で書き込みを拒否します。
リーダーインデックスのエイリアスに対する変更はフォロワーインデックスに複製されますが、書き込みインデックスは無視されます。フォロワーインデックスは直接の書き込みを受け入れられないため、リーダーエイリアスにis_write_indexがtrueに設定されている場合、その値はfalseに強制されます。
たとえば、データセンターAにdoc_1という名前のドキュメントをインデックスし、それがデータセンターBに複製されます。クライアントがデータセンターBに接続し、doc_1を更新しようとすると、リクエストは失敗します。doc_1を更新するには、クライアントはデータセンターAに接続し、リーダーインデックスのドキュメントを更新する必要があります。
フォロワーシャードがリーダーシャードから操作を受け取ると、それらの操作をライティングバッファに配置します。フォロワーシャードは、ライティングバッファからの操作を使用してバルク書き込みリクエストを送信します。ライティングバッファが設定された制限を超えると、追加の読み取りリクエストは送信されません。この構成は、読み取りリクエストに対するバックプレッシャーを提供し、ライティングバッファが満杯でなくなったときにフォロワーシャードが読み取りリクエストを再送信できるようにします。
リーダーインデックスからの操作がどのように複製されるかを管理するには、フォロワーインデックスを作成する際に設定を構成できます。
リーダーインデックスのインデックスマッピングの変更は、できるだけ早くフォロワーインデックスに複製されます。この動作はインデックス設定にも当てはまりますが、リーダーインデックスにローカルな設定がいくつかある場合を除きます。たとえば、リーダーインデックスのレプリカの数を変更しても、フォロワーインデックスには複製されないため、その設定は取得できない場合があります。
フォロワーインデックスがリーダーインデックスに必要な非動的設定変更を適用すると、フォロワーインデックスは自らを閉じ、設定の更新を適用し、その後再オープンします。このサイクル中、フォロワーインデックスは読み取り不可であり、書き込みを複製することはできません。
リモートリカバリを使用したフォロワーの初期化
フォロワーインデックスを作成すると、完全に初期化されるまで使用できません。リモートリカバリプロセスは、リーダークラスターのプライマリシャードからデータをコピーすることによって、フォロワーノード上にシャードの新しいコピーを構築します。
Elasticsearchは、このリモートリカバリプロセスを使用して、リーダーインデックスのデータを使用してフォロワーインデックスをブートストラップします。このプロセスにより、リーダーインデックスの現在の状態のコピーがフォロワーに提供されます。リーダーで変更の完全な履歴が利用できない場合でも、Luceneセグメントのマージのために、フォロワーはリーダーインデックスの現在の状態のコピーを取得できます。
リモートリカバリは、リーダークラスターからフォロワークラスターにすべてのLuceneセグメントファイルを転送するネットワーク集約型プロセスです。フォロワーは、リーダークラスターのプライマリシャードでリカバリセッションを開始するよう要求します。フォロワーは、その後、リーダーからファイルチャンクを同時に要求します。デフォルトでは、プロセスは5つの1MBファイルチャンクを同時に要求します。このデフォルトの動作は、リーダーとフォロワークラスター間の高いネットワークレイテンシをサポートするように設計されています。
動的なリモートリカバリ設定を変更して、転送されるデータのレート制限を行い、リモートリカバリによって消費されるリソースを管理できます。
フォロワーインデックスを含むクラスターでリカバリアピを使用して、進行中のリモートリカバリに関する情報を取得します。Elasticsearchは、スナップショットと復元のインフラストラクチャを使用してリモートリカバリを実装しているため、実行中のリモートリカバリはリカバリアピでタイプsnapshotとしてラベル付けされます。
リーダーの複製にはソフト削除が必要
クロスクラスター複製は、リーダーインデックスのシャードで実行された個々の書き込み操作の履歴を再生することによって機能します。Elasticsearchは、フォロワーシャードタスクがこれらの操作を取得できるように、リーダーシャードでこれらの操作の履歴を保持する必要があります。これらの操作を保持するために使用される基本的なメカニズムはソフト削除です。
ソフト削除は、既存のドキュメントが削除または更新されるたびに発生します。これらのソフト削除を設定可能な制限まで保持することにより、操作の履歴をリーダーシャードに保持し、フォロワーシャードタスクが操作の履歴を再生できるようにします。
index.soft_deletes.retention_lease.period設定は、シャード履歴保持リースを保持する最大時間を定義します。この設定は、フォロワーインデックスを含むクラスターがオフラインであることができる時間を決定します。デフォルトでは12時間です。リースが期限切れた後にシャードコピーが回復した場合でも、リーダーインデックスで欠落している操作がまだ利用可能な場合、Elasticsearchは新しいリースを確立し、欠落している操作をコピーします。ただし、Elasticsearchはリースされていない操作を保持することを保証しないため、欠落している操作の一部がリーダーによって破棄され、完全に利用できなくなる可能性もあります。この場合、フォロワーは自動的に回復できないため、再作成する必要があります。
ソフト削除は、リーダーインデックスとして使用するインデックスで有効にする必要があります。ソフト削除は、Elasticsearch 7.0.0以降に作成された新しいインデックスでデフォルトで有効になっています。
クロスクラスター複製は、ソフト削除が無効になっているElasticsearch 7.0.0以前に作成された既存のインデックスでは使用できません。ソフト削除が有効な新しいインデックスにデータを再インデックス化する必要があります。
クロスクラスター複製を使用する
以下のセクションでは、クロスクラスター複製を構成および使用する方法についての詳細情報を提供します:
クロスクラスター複製の制限
クロスクラスター複製は、ユーザー生成インデックスのみを複製するように設計されており、現在次のいずれかを複製することはありません:
- システムインデックス
- 機械学習ジョブ
- インデックステンプレート
- インデックスライフサイクル管理およびスナップショットライフサイクル管理ポリシー
- ユーザー権限とロールマッピング
- スナップショットリポジトリ設定
- クラスター設定
- 検索可能スナップショット
これらのデータを複製したい場合は、リモートクラスターに手動で複製する必要があります。
検索可能スナップショットインデックスのデータは、スナップショットリポジトリに保存されます。クロスクラスター複製は、これらのインデックスを完全に複製しません。たとえそれらがElasticsearchノード上で部分的または完全にキャッシュされていてもです。リモートクラスターで検索可能なスナップショットを実現するには、リモートクラスターにスナップショットリポジトリを構成し、ローカルクラスターから同じインデックスライフサイクル管理ポリシーを使用して、データをリモートクラスターのコールドまたはフローズン層に移動します。
