Cardinality aggregation
single-value メトリクス集約は、異なる値の近似カウントを計算します。
ストアの売上をインデックス化しており、クエリに一致する販売された製品のユニークな数をカウントしたいと仮定します:
Python
resp = client.search(index="sales",size="0",aggs={"type_count": {"cardinality": {"field": "type"}}},)print(resp)
Ruby
response = client.search(index: 'sales',size: 0,body: {aggregations: {type_count: {cardinality: {field: 'type'}}}})puts response
Js
const response = await client.search({index: "sales",size: 0,aggs: {type_count: {cardinality: {field: "type",},},},});console.log(response);
Console
POST /sales/_search?size=0{"aggs": {"type_count": {"cardinality": {"field": "type"}}}}
Console-Result
{..."aggregations": {"type_count": {"value": 3}}}
Precision control
この集約は、precision_threshold オプションもサポートしています:
Python
resp = client.search(index="sales",size="0",aggs={"type_count": {"cardinality": {"field": "type","precision_threshold": 100}}},)print(resp)
Ruby
response = client.search(index: 'sales',size: 0,body: {aggregations: {type_count: {cardinality: {field: 'type',precision_threshold: 100}}}})puts response
Js
const response = await client.search({index: "sales",size: 0,aggs: {type_count: {cardinality: {field: "type",precision_threshold: 100,},},},});console.log(response);
Console
POST /sales/_search?size=0{"aggs": {"type_count": {"cardinality": {"field": "type","precision_threshold": 100}}}}
precision_threshold オプションは、精度のためにメモリを取引することを可能にし、定義されたユニークカウントの下でカウントが正確に近いことが期待されます。 この値を超えると、カウントは少し曖昧になる可能性があります。サポートされている最大値は 40000 であり、この数値を超えるしきい値は 40000 のしきい値と同じ効果を持ちます。デフォルト値は 3000 です。 |
Counts are approximate
正確なカウントを計算するには、値をハッシュセットにロードし、そのサイズを返す必要があります。これは、高カーディナリティセットや大きな値で作業する際にはスケールしません。必要なメモリ使用量と、ノード間でそれらのシャードごとのセットを通信する必要がリソースを過剰に使用します。
この cardinality 集約は、HyperLogLog++ アルゴリズムに基づいており、いくつかの興味深い特性を持つ値のハッシュに基づいてカウントします:
- 設定可能な精度、メモリと精度のトレードオフを決定します。
- 低カーディナリティセットに対する優れた精度。
- 固定メモリ使用量: ユニークな値が数十または数十億あっても、メモリ使用量は設定された精度にのみ依存します。
c の精度しきい値の場合、私たちが使用している実装は約 c * 8 バイトを必要とします。
以下のチャートは、しきい値の前後でエラーがどのように変化するかを示しています:
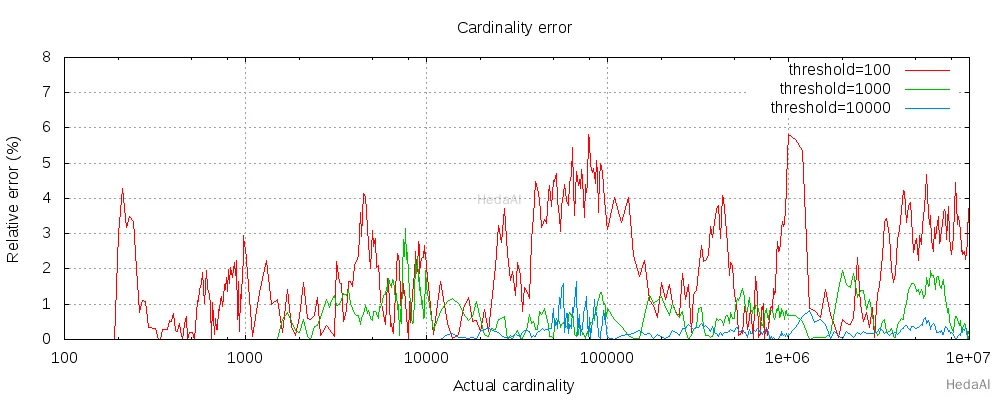
すべての 3 つのしきい値に対して、カウントは設定されたしきい値まで正確でした。保証はされていませんが、これはその可能性が高いです。実際の精度は、問題のデータセットに依存します。一般的に、ほとんどのデータセットは一貫して良好な精度を示します。また、しきい値が 100 の場合でも、エラーは非常に低く(上記のグラフで見られるように 1-6%)、数百万のアイテムをカウントしても同様です。
HyperLogLog++ アルゴリズムは、ハッシュ値の先頭のゼロに依存しており、データセット内のハッシュの正確な分布はカーディナリティの精度に影響を与える可能性があります。
Pre-computed hashes
高カーディナリティの文字列フィールドでは、フィールド値のハッシュをインデックスに保存し、そのフィールドでカーディナリティ集約を実行する方が速い場合があります。これは、クライアント側からハッシュ値を提供するか、mapper-murmur3 プラグインを使用して Elasticsearch にハッシュ値を計算させることで行うことができます。
ハッシュを事前計算することは、通常、非常に大きいおよび/または高カーディナリティのフィールドでのみ有用です。これは CPU とメモリを節約します。ただし、数値フィールドでは、ハッシュ化は非常に速く、元の値を保存するのに必要なメモリはハッシュを保存するのと同じかそれ以下です。これは、特にユニークな値ごとにセグメントごとにハッシュが最大 1 回計算されるように最適化されている低カーディナリティの文字列フィールドでも同様です。
Script
2 つのフィールドの組み合わせのカーディナリティが必要な場合は、それらを組み合わせた ランタイムフィールド を作成し、集約します。
Python
resp = client.search(index="sales",size="0",runtime_mappings={"type_and_promoted": {"type": "keyword","script": "emit(doc['type'].value + ' ' + doc['promoted'].value)"}},aggs={"type_promoted_count": {"cardinality": {"field": "type_and_promoted"}}},)print(resp)
Ruby
response = client.search(index: 'sales',size: 0,body: {runtime_mappings: {type_and_promoted: {type: 'keyword',script: "emit(doc['type'].value + ' ' + doc['promoted'].value)"}},aggregations: {type_promoted_count: {cardinality: {field: 'type_and_promoted'}}}})puts response
Js
const response = await client.search({index: "sales",size: 0,runtime_mappings: {type_and_promoted: {type: "keyword",script: "emit(doc['type'].value + ' ' + doc['promoted'].value)",},},aggs: {type_promoted_count: {cardinality: {field: "type_and_promoted",},},},});console.log(response);
Console
POST /sales/_search?size=0{"runtime_mappings": {"type_and_promoted": {"type": "keyword","script": "emit(doc['type'].value + ' ' + doc['promoted'].value)"}},"aggs": {"type_promoted_count": {"cardinality": {"field": "type_and_promoted"}}}}
Missing value
missing パラメータは、値が欠落しているドキュメントがどのように扱われるべきかを定義します。デフォルトでは無視されますが、値があるかのように扱うことも可能です。
Python
resp = client.search(index="sales",size="0",aggs={"tag_cardinality": {"cardinality": {"field": "tag","missing": "N/A"}}},)print(resp)
Ruby
response = client.search(index: 'sales',size: 0,body: {aggregations: {tag_cardinality: {cardinality: {field: 'tag',missing: 'N/A'}}}})puts response
Js
const response = await client.search({index: "sales",size: 0,aggs: {tag_cardinality: {cardinality: {field: "tag",missing: "N/A",},},},});console.log(response);
Console
POST /sales/_search?size=0{"aggs": {"tag_cardinality": {"cardinality": {"field": "tag","missing": "N/A"}}}}
tag フィールドに値がないドキュメントは、値が N/A のドキュメントと同じバケットに入ります。 |
Execution hint
異なるメカニズムを使用してカーディナリティ集約を実行できます:
- フィールド値を直接使用する (
direct) - フィールドのグローバルオーディナルを使用し、シャードの処理が完了した後にそれらの値を解決する (
global_ordinals) - セグメントオーディナル値を使用し、各セグメントの後にそれらの値を解決する (
segment_ordinals)
さらに、2 つの「ヒューリスティックベース」のモードがあります。これらのモードは、Elasticsearch がインデックスの状態に関するデータを使用して適切な実行方法を選択する原因となります。2 つのヒューリスティックは:
save_time_heuristic- これは Elasticsearch 8.4 以降のデフォルトです。save_memory_heuristic- これは Elasticsearch 8.3 以前のデフォルトです
指定されていない場合、Elasticsearch は適切なモードを選択するためにヒューリスティックを適用します。また、一部のデータ(非オーディナルフィールド)では、direct が唯一のオプションであり、この場合ヒントは無視されます。一般的に、この値を設定する必要はありません。
