シャードの容量の健康問題のトラブルシューティング
Elasticsearchは、cluster.max_shards_per_nodeおよびcluster.max_shards_per_node.frozen設定を使用して、ノードごとに保持される最大シャード数を制限します。クラスターの現在のシャード容量は、ヘルスAPIのシャード容量セクションで確認できます。
クラスターはデータノードのために設定された最大シャード数に近づいています。
cluster.max_shards_per_nodeクラスター設定は、フローズンティアに属さないデータノードのみをカウントして、クラスターのオープンシャードの最大数を制限します。
この症状は、何らかのアクションを取る必要があることを示しています。そうしないと、新しいインデックスの作成やクラスターのアップグレードがブロックされる可能性があります。
変更がクラスターを不安定にしないと確信している場合は、クラスター更新設定APIを使用して、一時的に制限を増やすことができます:
Kibanaを使用する
- 1. Elastic Cloudコンソールにログインします。
- 2. Elasticsearchサービスパネルで、デプロイメントの名前をクリックします。
デプロイメントの名前が無効になっている場合、Kibanaインスタンスが正常でない可能性があります。その場合は、Elasticサポートに連絡してください。デプロイメントにKibanaが含まれていない場合は、最初にそれを有効にするだけで済みます。 - 3. デプロイメントのサイドナビゲーションメニュー(左上隅のElasticロゴの下に配置)を開き、Dev Tools > Consoleに移動します。
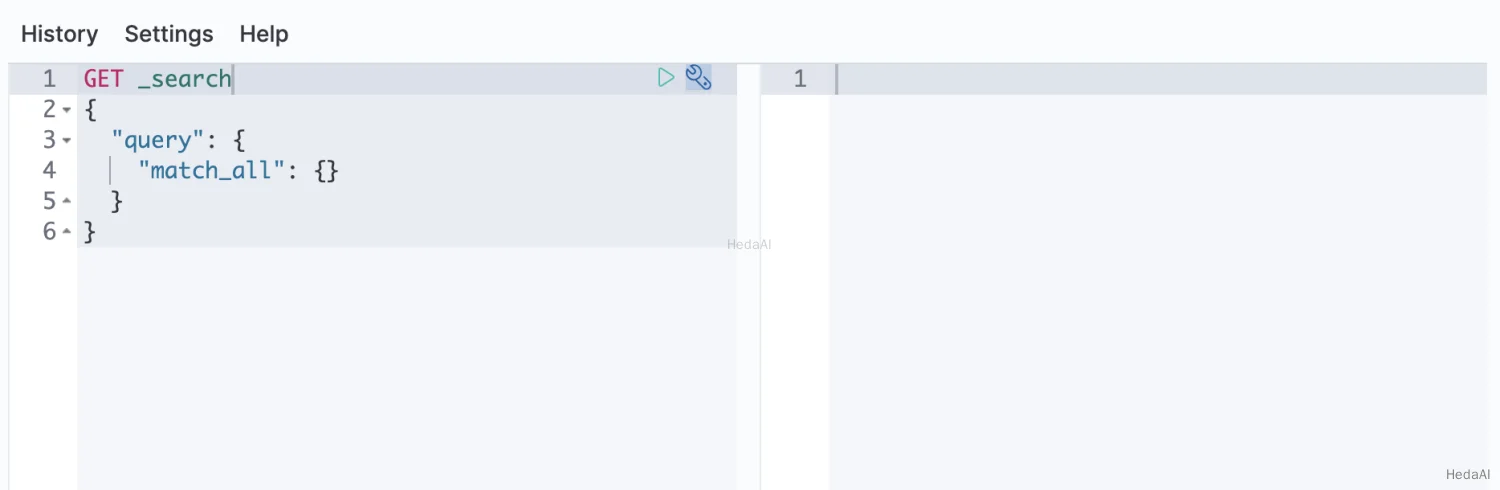
- 4. シャード容量インジケーターに従って、クラスターの現在の状態を確認します:
Python
resp = client.health_report(feature="shards_capacity",)print(resp)
Ruby
response = client.health_report(feature: 'shards_capacity')puts response
Js
const response = await client.healthReport({feature: "shards_capacity",});console.log(response);
Console
GET _health_report/shards_capacity
Console-Result
{"cluster_name": "...","indicators": {"shards_capacity": {"status": "yellow","symptom": "Cluster is close to reaching the configured maximum number of shards for data nodes.","details": {"data": {"max_shards_in_cluster": 1000,"current_used_shards": 988},"frozen": {"max_shards_in_cluster": 3000,"current_used_shards": 0}},"impacts": [...],"diagnosis": [...}}}
設定の現在の値 cluster.max_shards_per_node |
|
| クラスター全体のオープンシャードの現在の数 |
- 5. 適切な値で
cluster.max_shards_per_node設定を更新します:
Python
resp = client.cluster.put_settings(persistent={"cluster.max_shards_per_node": 1200},)print(resp)
Ruby
response = client.cluster.put_settings(body: {persistent: {'cluster.max_shards_per_node' => 1200}})puts response
Js
const response = await client.cluster.putSettings({persistent: {"cluster.max_shards_per_node": 1200,},});console.log(response);
Console
PUT _cluster/settings{"persistent" : {"cluster.max_shards_per_node": 1200}}
この増加は一時的なものであるべきです。長期的な解決策として、オーバーシャードされたデータティアにノードを追加するか、クラスターのシャード数を減らすことをお勧めします。
- 6. 変更が問題を解決したかどうかを確認するには、[
shards_capacity]インジケーターの現在の状態を取得するために、ヘルスAPIの[data]セクションを確認できます:
Python
resp = client.health_report(feature="shards_capacity",)print(resp)
Ruby
response = client.health_report(feature: 'shards_capacity')puts response
Js
const response = await client.healthReport({feature: "shards_capacity",});console.log(response);
Console
GET _health_report/shards_capacity
Console-Result
{"cluster_name": "...","indicators": {"shards_capacity": {"status": "green","symptom": "The cluster has enough room to add new shards.","details": {"data": {"max_shards_in_cluster": 1000},"frozen": {"max_shards_in_cluster": 3000}}}}}
- 7. 長期的な解決策が整ったら、[
cluster.max_shards_per_node]制限をリセットすることをお勧めします。
Python
resp = client.cluster.put_settings(persistent={"cluster.max_shards_per_node": None},)print(resp)
Ruby
response = client.cluster.put_settings(body: {persistent: {'cluster.max_shards_per_node' => nil}})puts response
Js
const response = await client.cluster.putSettings({persistent: {"cluster.max_shards_per_node": null,},});console.log(response);
Console
PUT _cluster/settings{"persistent" : {"cluster.max_shards_per_node": null}}
シャード容量インジケーターに従って、クラスターの現在の状態を確認します:
Python
resp = client.health_report(feature="shards_capacity",)print(resp)
Ruby
response = client.health_report(feature: 'shards_capacity')puts response
Js
const response = await client.healthReport({feature: "shards_capacity",});console.log(response);
Console
GET _health_report/shards_capacity
Console-Result
{"cluster_name": "...","indicators": {"shards_capacity": {"status": "yellow","symptom": "Cluster is close to reaching the configured maximum number of shards for data nodes.","details": {"data": {"max_shards_in_cluster": 1000,"current_used_shards": 988},"frozen": {"max_shards_in_cluster": 3000}},"impacts": [...],"diagnosis": [...}}}
設定の現在の値 cluster.max_shards_per_node |
|
| クラスター全体のオープンシャードの現在の数 |
cluster settings APIを使用して、cluster.max_shards_per_node設定を更新します:
Python
resp = client.cluster.put_settings(persistent={"cluster.max_shards_per_node": 1200},)print(resp)
Ruby
response = client.cluster.put_settings(body: {persistent: {'cluster.max_shards_per_node' => 1200}})puts response
Js
const response = await client.cluster.putSettings({persistent: {"cluster.max_shards_per_node": 1200,},});console.log(response);
Console
PUT _cluster/settings{"persistent" : {"cluster.max_shards_per_node": 1200}}
この増加は一時的なものであるべきです。長期的な解決策として、オーバーシャードされたデータティアにノードを追加するか、クラスターのシャード数を減らすことをお勧めします。変更が問題を解決したかどうかを確認するには、[shards_capacity]インジケーターの現在の状態を取得するために、ヘルスAPIの[data]セクションを確認できます:
Python
resp = client.health_report(feature="shards_capacity",)print(resp)
Ruby
response = client.health_report(feature: 'shards_capacity')puts response
Js
const response = await client.healthReport({feature: "shards_capacity",});console.log(response);
Console
GET _health_report/shards_capacity
Console-Result
{"cluster_name": "...","indicators": {"shards_capacity": {"status": "green","symptom": "The cluster has enough room to add new shards.","details": {"data": {"max_shards_in_cluster": 1200},"frozen": {"max_shards_in_cluster": 3000}}}}}
長期的な解決策が整ったら、[cluster.max_shards_per_node]制限をリセットすることをお勧めします。
Python
resp = client.cluster.put_settings(persistent={"cluster.max_shards_per_node": None},)print(resp)
Ruby
response = client.cluster.put_settings(body: {persistent: {'cluster.max_shards_per_node' => nil}})puts response
Js
const response = await client.cluster.putSettings({persistent: {"cluster.max_shards_per_node": null,},});console.log(response);
Console
PUT _cluster/settings{"persistent" : {"cluster.max_shards_per_node": null}}
クラスターはフローズンノードのために設定された最大シャード数に近づいています。
cluster.max_shards_per_node.frozenクラスター設定は、フローズンティアに属するデータノードのみをカウントして、クラスターのオープンシャードの最大数を制限します。
この症状は、何らかのアクションを取る必要があることを示しています。そうしないと、新しいインデックスの作成やクラスターのアップグレードがブロックされる可能性があります。
変更がクラスターを不安定にしないと確信している場合は、クラスター更新設定APIを使用して、一時的に制限を増やすことができます:
Kibanaを使用する
- 1. Elastic Cloudコンソールにログインします。
- 2. Elasticsearchサービスパネルで、デプロイメントの名前をクリックします。
デプロイメントの名前が無効になっている場合、Kibanaインスタンスが正常でない可能性があります。その場合は、Elasticサポートに連絡してください。デプロイメントにKibanaが含まれていない場合は、最初にそれを有効にするだけで済みます。 - 3. デプロイメントのサイドナビゲーションメニュー(左上隅のElasticロゴの下に配置)を開き、Dev Tools > Consoleに移動します。
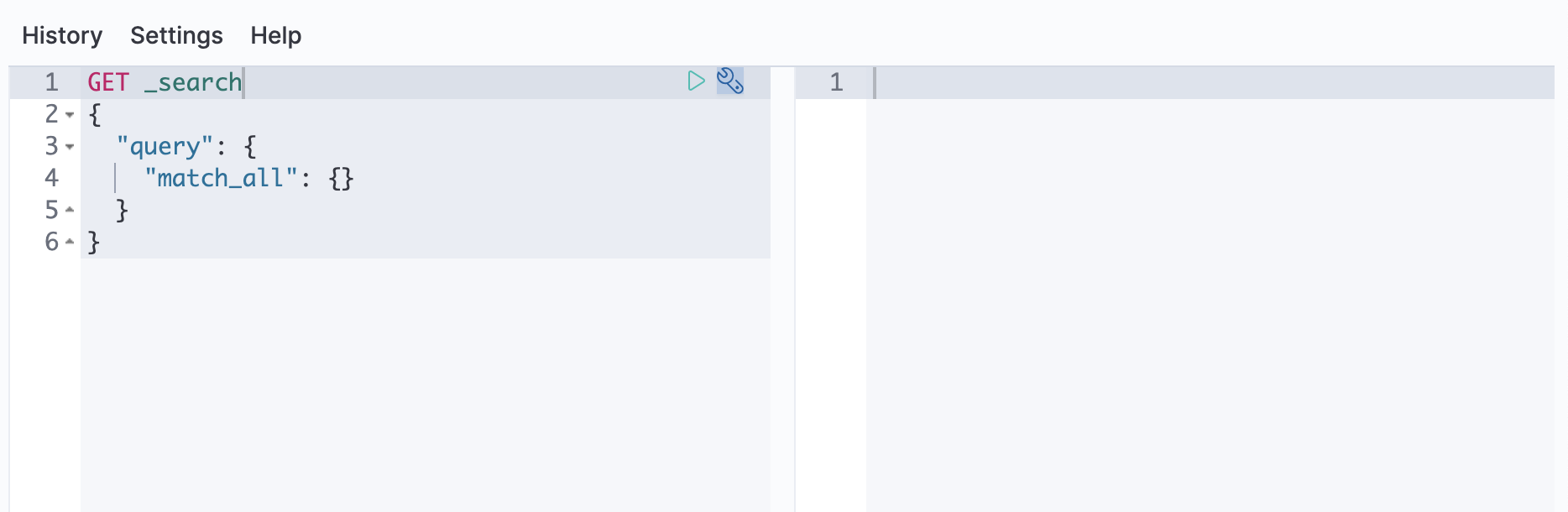
- 4. シャード容量インジケーターに従って、クラスターの現在の状態を確認します:
Python
resp = client.health_report(feature="shards_capacity",)print(resp)
Ruby
response = client.health_report(feature: 'shards_capacity')puts response
Js
const response = await client.healthReport({feature: "shards_capacity",});console.log(response);
Console
GET _health_report/shards_capacity
Console-Result
{"cluster_name": "...","indicators": {"shards_capacity": {"status": "yellow","symptom": "Cluster is close to reaching the configured maximum number of shards for frozen nodes.","details": {"data": {"max_shards_in_cluster": 1000},"frozen": {"max_shards_in_cluster": 3000,"current_used_shards": 2998}},"impacts": [...],"diagnosis": [...}}}
| フローズンノード全体で使用されているオープンシャードの現在の数 | |
設定の現在の値 cluster.max_shards_per_node.frozen |
- 5.
cluster.max_shards_per_node.frozen設定を更新します:
Python
resp = client.cluster.put_settings(persistent={"cluster.max_shards_per_node.frozen": 3200},)print(resp)
Ruby
response = client.cluster.put_settings(body: {persistent: {'cluster.max_shards_per_node.frozen' => 3200}})puts response
Js
const response = await client.cluster.putSettings({persistent: {"cluster.max_shards_per_node.frozen": 3200,},});console.log(response);
Console
PUT _cluster/settings{"persistent" : {"cluster.max_shards_per_node.frozen": 3200}}
この増加は一時的なものであるべきです。長期的な解決策として、フローズンティアにノードを追加するか、クラスターのシャード数を減らすことをお勧めします。
- 6. 変更が問題を解決したかどうかを確認するには、[
shards_capacity]インジケーターの現在の状態を取得するために、ヘルスAPIの[data]セクションを確認できます:
Python
resp = client.health_report(feature="shards_capacity",)print(resp)
Ruby
response = client.health_report(feature: 'shards_capacity')puts response
Js
const response = await client.healthReport({feature: "shards_capacity",});console.log(response);
Console
GET _health_report/shards_capacity
Console-Result
{"cluster_name": "...","indicators": {"shards_capacity": {"status": "green","symptom": "The cluster has enough room to add new shards.","details": {"data": {"max_shards_in_cluster": 1000},"frozen": {"max_shards_in_cluster": 3200}}}}}
- 7. 長期的な解決策が整ったら、[
cluster.max_shards_per_node.frozen]制限をリセットすることをお勧めします。
Python
resp = client.cluster.put_settings(persistent={"cluster.max_shards_per_node.frozen": None},)print(resp)
Ruby
response = client.cluster.put_settings(body: {persistent: {'cluster.max_shards_per_node.frozen' => nil}})puts response
Js
const response = await client.cluster.putSettings({persistent: {"cluster.max_shards_per_node.frozen": null,},});console.log(response);
Console
PUT _cluster/settings{"persistent" : {"cluster.max_shards_per_node.frozen": null}}
シャード容量インジケーターに従って、クラスターの現在の状態を確認します:
Python
resp = client.health_report(feature="shards_capacity",)print(resp)
Ruby
response = client.health_report(feature: 'shards_capacity')puts response
Js
const response = await client.healthReport({feature: "shards_capacity",});console.log(response);
Console
GET _health_report/shards_capacity
Console-Result
{"cluster_name": "...","indicators": {"shards_capacity": {"status": "yellow","symptom": "Cluster is close to reaching the configured maximum number of shards for frozen nodes.","details": {"data": {"max_shards_in_cluster": 1000},"frozen": {"max_shards_in_cluster": 3000,"current_used_shards": 2998}},"impacts": [...],"diagnosis": [...}}}
| フローズンノード全体で使用されているオープンシャードの現在の数 | |
設定の現在の値 cluster.max_shards_per_node.frozen |
cluster settings APIを使用して、cluster.max_shards_per_node.frozen設定を更新します:
Python
resp = client.cluster.put_settings(persistent={"cluster.max_shards_per_node.frozen": 3200},)print(resp)
Ruby
response = client.cluster.put_settings(body: {persistent: {'cluster.max_shards_per_node.frozen' => 3200}})puts response
Js
const response = await client.cluster.putSettings({persistent: {"cluster.max_shards_per_node.frozen": 3200,},});console.log(response);
Console
PUT _cluster/settings{"persistent" : {"cluster.max_shards_per_node.frozen": 3200}}
この増加は一時的なものであるべきです。長期的な解決策として、フローズンティアにノードを追加するか、クラスターのシャード数を減らすことをお勧めします。変更が問題を解決したかどうかを確認するには、[shards_capacity]インジケーターの現在の状態を取得するために、ヘルスAPIの[data]セクションを確認できます:
Python
resp = client.health_report(feature="shards_capacity",)print(resp)
Ruby
response = client.health_report(feature: 'shards_capacity')puts response
Js
const response = await client.healthReport({feature: "shards_capacity",});console.log(response);
Console
GET _health_report/shards_capacity
Console-Result
{"cluster_name": "...","indicators": {"shards_capacity": {"status": "green","symptom": "The cluster has enough room to add new shards.","details": {"data": {"max_shards_in_cluster": 1000},"frozen": {"max_shards_in_cluster": 3200}}}}}
長期的な解決策が整ったら、[cluster.max_shards_per_node.frozen]制限をリセットすることをお勧めします。
Python
resp = client.cluster.put_settings(persistent={"cluster.max_shards_per_node.frozen": None},)print(resp)
Ruby
response = client.cluster.put_settings(body: {persistent: {'cluster.max_shards_per_node.frozen' => nil}})puts response
Js
const response = await client.cluster.putSettings({persistent: {"cluster.max_shards_per_node.frozen": null,},});console.log(response);
Console
PUT _cluster/settings{"persistent" : {"cluster.max_shards_per_node.frozen": null}}
