変換の例
これらの例は、データから有用な洞察を導き出すために変換を使用する方法を示しています。すべての例は、Kibanaのサンプルデータセットのいずれかを使用しています。より詳細なステップバイステップの例については、チュートリアル:eCommerceサンプルデータの変換を参照してください。
- 最高の顧客を見つける
- 最も遅延の多い航空会社を見つける
- 疑わしいクライアントIPを見つける
- 各IPアドレスの最後のログイベントを見つける
- サーバーに最も多くのバイトを送信したクライアントIPを見つける
- 顧客IDによる顧客名とメールアドレスの取得
最高の顧客を見つける
この例では、eCommerceの注文サンプルデータセットを使用して、仮想のウェブショップで最も多く支出した顧客を見つけます。pivotタイプの変換を使用して、宛先インデックスには、注文数、注文の合計金額、ユニークな商品の数、注文ごとの平均価格、および各顧客の注文された商品の合計が含まれるようにします。
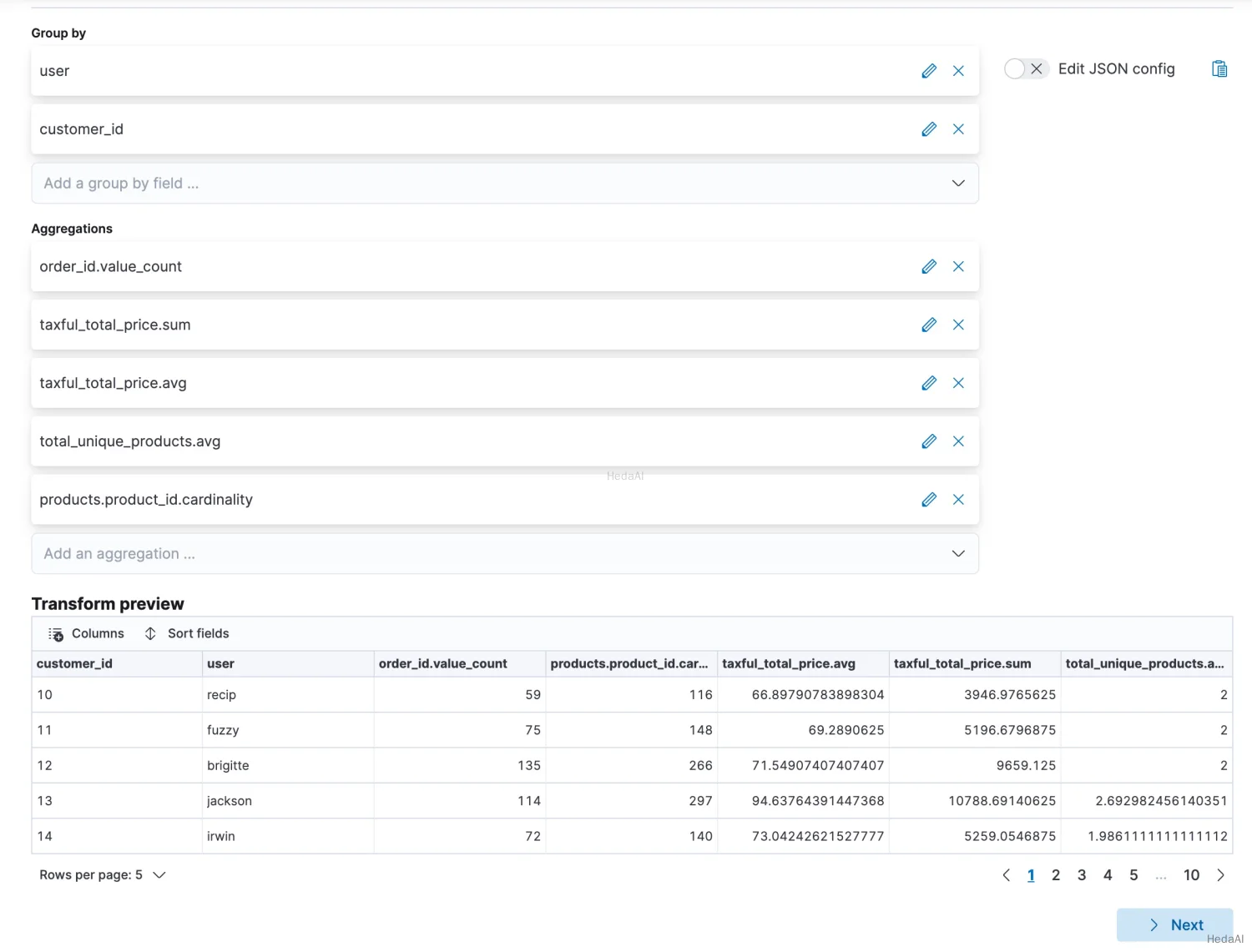
また、プレビュートランスフォームやトランスフォーム作成APIを使用することもできます。
APIの例
Python
resp = client.transform.preview_transform(source={"index": "kibana_sample_data_ecommerce"},dest={"index": "sample_ecommerce_orders_by_customer"},pivot={"group_by": {"user": {"terms": {"field": "user"}},"customer_id": {"terms": {"field": "customer_id"}}},"aggregations": {"order_count": {"value_count": {"field": "order_id"}},"total_order_amt": {"sum": {"field": "taxful_total_price"}},"avg_amt_per_order": {"avg": {"field": "taxful_total_price"}},"avg_unique_products_per_order": {"avg": {"field": "total_unique_products"}},"total_unique_products": {"cardinality": {"field": "products.product_id"}}}},)print(resp)
Js
const response = await client.transform.previewTransform({source: {index: "kibana_sample_data_ecommerce",},dest: {index: "sample_ecommerce_orders_by_customer",},pivot: {group_by: {user: {terms: {field: "user",},},customer_id: {terms: {field: "customer_id",},},},aggregations: {order_count: {value_count: {field: "order_id",},},total_order_amt: {sum: {field: "taxful_total_price",},},avg_amt_per_order: {avg: {field: "taxful_total_price",},},avg_unique_products_per_order: {avg: {field: "total_unique_products",},},total_unique_products: {cardinality: {field: "products.product_id",},},},},});console.log(response);
コンソール
POST _transform/_preview{"source": {"index": "kibana_sample_data_ecommerce"},"dest" : {"index" : "sample_ecommerce_orders_by_customer"},"pivot": {"group_by": {"user": { "terms": { "field": "user" }},"customer_id": { "terms": { "field": "customer_id" }}},"aggregations": {"order_count": { "value_count": { "field": "order_id" }},"total_order_amt": { "sum": { "field": "taxful_total_price" }},"avg_amt_per_order": { "avg": { "field": "taxful_total_price" }},"avg_unique_products_per_order": { "avg": { "field": "total_unique_products" }},"total_unique_products": { "cardinality": { "field": "products.product_id" }}}}}
変換の宛先インデックス。_previewによって無視されます。 |
|
2つのgroup_byフィールドが選択されます。これは、変換がuserとcustomer_idの組み合わせごとにユニークな行を含むことを意味します。このデータセット内では、これらのフィールドはどちらもユニークです。両方を変換に含めることで、最終結果により多くのコンテキストが提供されます。 |
上記の例では、ピボットオブジェクトの可読性を高めるために、圧縮JSONフォーマットが使用されています。
プレビュートランスフォームAPIを使用すると、サンプル値で埋められた変換のレイアウトを事前に確認できます。たとえば:
Js
{"preview" : [{"total_order_amt" : 3946.9765625,"order_count" : 59.0,"total_unique_products" : 116.0,"avg_unique_products_per_order" : 2.0,"customer_id" : "10","user" : "recip","avg_amt_per_order" : 66.89790783898304},...]}
この変換は、次のような質問に答えるのを容易にします:
- どの顧客が最も多く支出していますか?
- どの顧客が注文ごとに最も多く支出していますか?
- どの顧客が最も頻繁に注文していますか?
- どの顧客が最も少ない異なる商品を注文しましたか?
これらの質問には集計だけで答えることも可能ですが、変換を使用することで、顧客中心のインデックスとしてこのデータを永続化できます。これにより、スケールでデータを分析し、顧客中心の視点からデータを探索しナビゲートする柔軟性が向上します。場合によっては、視覚化の作成がはるかに簡単になることもあります。
最も遅延の多い航空会社を見つける
この例では、フライトのサンプルデータセットを使用して、どの航空会社が最も遅延が多かったかを調べます。まず、クエリフィルターを使用して、すべてのキャンセルされたフライトを除外するようにソースデータをフィルタリングします。次に、データを変換して、航空会社ごとのフライトの数、遅延時間の合計、およびフライト時間の合計を含むようにします。最後に、bucket_scriptを使用して、実際の遅延時間の割合を決定します。
Python
resp = client.transform.preview_transform(source={"index": "kibana_sample_data_flights","query": {"bool": {"filter": [{"term": {"Cancelled": False}}]}}},dest={"index": "sample_flight_delays_by_carrier"},pivot={"group_by": {"carrier": {"terms": {"field": "Carrier"}}},"aggregations": {"flights_count": {"value_count": {"field": "FlightNum"}},"delay_mins_total": {"sum": {"field": "FlightDelayMin"}},"flight_mins_total": {"sum": {"field": "FlightTimeMin"}},"delay_time_percentage": {"bucket_script": {"buckets_path": {"delay_time": "delay_mins_total.value","flight_time": "flight_mins_total.value"},"script": "(params.delay_time / params.flight_time) * 100"}}}},)print(resp)
Js
const response = await client.transform.previewTransform({source: {index: "kibana_sample_data_flights",query: {bool: {filter: [{term: {Cancelled: false,},},],},},},dest: {index: "sample_flight_delays_by_carrier",},pivot: {group_by: {carrier: {terms: {field: "Carrier",},},},aggregations: {flights_count: {value_count: {field: "FlightNum",},},delay_mins_total: {sum: {field: "FlightDelayMin",},},flight_mins_total: {sum: {field: "FlightTimeMin",},},delay_time_percentage: {bucket_script: {buckets_path: {delay_time: "delay_mins_total.value",flight_time: "flight_mins_total.value",},script: "(params.delay_time / params.flight_time) * 100",},},},},});console.log(response);
コンソール
POST _transform/_preview{"source": {"index": "kibana_sample_data_flights","query": {"bool": {"filter": [{ "term": { "Cancelled": false } }]}}},"dest" : {"index" : "sample_flight_delays_by_carrier"},"pivot": {"group_by": {"carrier": { "terms": { "field": "Carrier" }}},"aggregations": {"flights_count": { "value_count": { "field": "FlightNum" }},"delay_mins_total": { "sum": { "field": "FlightDelayMin" }},"flight_mins_total": { "sum": { "field": "FlightTimeMin" }},"delay_time_percentage": {"bucket_script": {"buckets_path": {"delay_time": "delay_mins_total.value","flight_time": "flight_mins_total.value"},"script": "(params.delay_time / params.flight_time) * 100"}}}}}
| キャンセルされていないフライトのみを選択するようにソースデータをフィルタリングします。 | |
変換の宛先インデックス。_previewによって無視されます。 |
|
データは航空会社名を含むCarrierフィールドでグループ化されます。 |
|
このbucket_scriptは、集計によって返される結果に対して計算を行います。この特定の例では、旅行時間のうちどのくらいが遅延に費やされたかを計算します。 |
プレビューでは、新しいインデックスが各キャリアに対してこのようなデータを含むことを示しています:
Js
{"preview" : [{"carrier" : "ES-Air","flights_count" : 2802.0,"flight_mins_total" : 1436927.5130677223,"delay_time_percentage" : 9.335543983955839,"delay_mins_total" : 134145.0},...]}
この変換は、次のような質問に答えるのを容易にします:
- どの航空会社がフライト時間の割合として最も多くの遅延を持っていますか?
このデータは架空のものであり、特定の目的地または出発空港の実際の遅延やフライト統計を反映していません。
疑わしいクライアントIPを見つける
この例では、ウェブログのサンプルデータセットを使用して疑わしいクライアントIPを特定します。データを変換して、新しいインデックスには、バイトの合計と異なるURL、エージェント、場所ごとの受信リクエストの数、および各クライアントIPの地理的な宛先が含まれるようにします。また、各クライアントIPが受け取る特定のHTTPレスポンスの種類をカウントするためにフィルター集計を使用します。最終的に、以下の例は、ウェブログデータをclientipというエンティティ中心のインデックスに変換します。
Python
resp = client.transform.put_transform(transform_id="suspicious_client_ips",source={"index": "kibana_sample_data_logs"},dest={"index": "sample_weblogs_by_clientip"},sync={"time": {"field": "timestamp","delay": "60s"}},pivot={"group_by": {"clientip": {"terms": {"field": "clientip"}}},"aggregations": {"url_dc": {"cardinality": {"field": "url.keyword"}},"bytes_sum": {"sum": {"field": "bytes"}},"geo.src_dc": {"cardinality": {"field": "geo.src"}},"agent_dc": {"cardinality": {"field": "agent.keyword"}},"geo.dest_dc": {"cardinality": {"field": "geo.dest"}},"responses.total": {"value_count": {"field": "timestamp"}},"success": {"filter": {"term": {"response": "200"}}},"error404": {"filter": {"term": {"response": "404"}}},"error5xx": {"filter": {"range": {"response": {"gte": 500,"lt": 600}}}},"timestamp.min": {"min": {"field": "timestamp"}},"timestamp.max": {"max": {"field": "timestamp"}},"timestamp.duration_ms": {"bucket_script": {"buckets_path": {"min_time": "timestamp.min.value","max_time": "timestamp.max.value"},"script": "(params.max_time - params.min_time)"}}}},)print(resp)
Js
const response = await client.transform.putTransform({transform_id: "suspicious_client_ips",source: {index: "kibana_sample_data_logs",},dest: {index: "sample_weblogs_by_clientip",},sync: {time: {field: "timestamp",delay: "60s",},},pivot: {group_by: {clientip: {terms: {field: "clientip",},},},aggregations: {url_dc: {cardinality: {field: "url.keyword",},},bytes_sum: {sum: {field: "bytes",},},"geo.src_dc": {cardinality: {field: "geo.src",},},agent_dc: {cardinality: {field: "agent.keyword",},},"geo.dest_dc": {cardinality: {field: "geo.dest",},},"responses.total": {value_count: {field: "timestamp",},},success: {filter: {term: {response: "200",},},},error404: {filter: {term: {response: "404",},},},error5xx: {filter: {range: {response: {gte: 500,lt: 600,},},},},"timestamp.min": {min: {field: "timestamp",},},"timestamp.max": {max: {field: "timestamp",},},"timestamp.duration_ms": {bucket_script: {buckets_path: {min_time: "timestamp.min.value",max_time: "timestamp.max.value",},script: "(params.max_time - params.min_time)",},},},},});console.log(response);
コンソール
PUT _transform/suspicious_client_ips{"source": {"index": "kibana_sample_data_logs"},"dest" : {"index" : "sample_weblogs_by_clientip"},"sync" : {"time": {"field": "timestamp","delay": "60s"}},"pivot": {"group_by": {"clientip": { "terms": { "field": "clientip" } }},"aggregations": {"url_dc": { "cardinality": { "field": "url.keyword" }},"bytes_sum": { "sum": { "field": "bytes" }},"geo.src_dc": { "cardinality": { "field": "geo.src" }},"agent_dc": { "cardinality": { "field": "agent.keyword" }},"geo.dest_dc": { "cardinality": { "field": "geo.dest" }},"responses.total": { "value_count": { "field": "timestamp" }},"success" : {"filter": {"term": { "response" : "200"}}},"error404" : {"filter": {"term": { "response" : "404"}}},"error5xx" : {"filter": {"range": { "response" : { "gte": 500, "lt": 600}}}},"timestamp.min": { "min": { "field": "timestamp" }},"timestamp.max": { "max": { "field": "timestamp" }},"timestamp.duration_ms": {"bucket_script": {"buckets_path": {"min_time": "timestamp.min.value","max_time": "timestamp.max.value"},"script": "(params.max_time - params.min_time)"}}}}}
| 変換の宛先インデックス。 | |
変換を継続的に実行するように設定します。timestampフィールドを使用して、ソースインデックスと宛先インデックスを同期します。最悪の場合の取り込み遅延は60秒です。 |
|
データはclientipフィールドでグループ化されます。 |
|
フィルター集計は、200レスポンスの発生回数をカウントします。次の2つの集計(error404とerror5xx)は、エラーコードによるエラーレスポンスをカウントし、正確な値またはレスポンスコードの範囲に一致します。 |
|
このbucket_scriptは、集計の結果に基づいてclientipアクセスの期間を計算します。 |
変換を作成した後は、それを開始する必要があります:
Python
resp = client.transform.start_transform(transform_id="suspicious_client_ips",)print(resp)
Ruby
response = client.transform.start_transform(transform_id: 'suspicious_client_ips')puts response
Js
const response = await client.transform.startTransform({transform_id: "suspicious_client_ips",});console.log(response);
コンソール
POST _transform/suspicious_client_ips/_start
短時間後、最初の結果が宛先インデックスに表示されるはずです:
Python
resp = client.search(index="sample_weblogs_by_clientip",)print(resp)
Ruby
response = client.search(index: 'sample_weblogs_by_clientip')puts response
Js
const response = await client.search({index: "sample_weblogs_by_clientip",});console.log(response);
コンソール
GET sample_weblogs_by_clientip/_search
検索結果は、各クライアントIPに対してこのようなデータを示します:
Js
"hits" : [{"_index" : "sample_weblogs_by_clientip","_id" : "MOeHH_cUL5urmartKj-b5UQAAAAAAAAA","_score" : 1.0,"_source" : {"geo" : {"src_dc" : 2.0,"dest_dc" : 2.0},"success" : 2,"error404" : 0,"error503" : 0,"clientip" : "0.72.176.46","agent_dc" : 2.0,"bytes_sum" : 4422.0,"responses" : {"total" : 2.0},"url_dc" : 2.0,"timestamp" : {"duration_ms" : 5.2191698E8,"min" : "2020-03-16T07:51:57.333Z","max" : "2020-03-22T08:50:34.313Z"}}}]
他のKibanaサンプルデータセットと同様に、ウェブログのサンプルデータセットには、インストール時のタイムスタンプが含まれており、将来のタイムスタンプも含まれています。継続的な変換は、データポイントが過去に入るとそれを取得します。ウェブログのサンプルデータセットをしばらく前にインストールした場合は、アンインストールして再インストールすると、タイムスタンプが変更されます。
この変換は、次のような質問に答えるのを容易にします:
- どのクライアントIPが最も多くのデータを転送していますか?
- どのクライアントIPが多くの異なるURLと対話していますか?
- どのクライアントIPが高いエラー率を持っていますか?
- どのクライアントIPが多くの宛先国と対話していますか?
各IPアドレスの最後のログイベントを見つける
この例では、ウェブログのサンプルデータセットを使用して、IPアドレスからの最後のログを見つけます。latestタイプの変換を継続モードで使用します。これは、ソースインデックスから宛先インデックスに各ユニークキーの最新のドキュメントをコピーし、新しいデータがソースインデックスに入ると宛先インデックスを更新します。
最近ログに表示されたIPアドレスのドキュメントのみを保持することに興味があると仮定しましょう。保持ポリシーを定義し、ドキュメントの年齢を計算するために使用される日付フィールドを指定できます。この例では、データをソートするために使用されるのと同じ日付フィールドを使用します。次に、ドキュメントの最大年齢を設定します。設定した値より古いドキュメントは宛先インデックスから削除されます。この変換は、各クライアントIPの最新のログイン日を含む宛先インデックスを作成します。変換が継続モードで実行されるため、宛先インデックスはソースインデックスに新しいデータが入ると更新されます。最後に、30日以上古いすべてのドキュメントは、適用された保持ポリシーにより宛先インデックスから削除されます。APIの例#### Python``````pythonresp = client.transform.put_transform(transform_id="last-log-from-clientip",source={"index": ["kibana_sample_data_logs"]},latest={"unique_key": ["clientip"],"sort": "timestamp"},frequency="1m",dest={"index": "last-log-from-clientip"},sync={"time": {"field": "timestamp","delay": "60s"}},retention_policy={"time": {"field": "timestamp","max_age": "30d"}},settings={"max_page_search_size": 500},)print(resp)`
Js
const response = await client.transform.putTransform({transform_id: "last-log-from-clientip",source: {index: ["kibana_sample_data_logs"],},latest: {unique_key: ["clientip"],sort: "timestamp",},frequency: "1m",dest: {index: "last-log-from-clientip",},sync: {time: {field: "timestamp",delay: "60s",},},retention_policy: {time: {field: "timestamp",max_age: "30d",},},settings: {max_page_search_size: 500,},});console.log(response);
コンソール
PUT _transform/last-log-from-clientip{"source": {"index": ["kibana_sample_data_logs"]},"latest": {"unique_key": ["clientip"],"sort": "timestamp"},"frequency": "1m","dest": {"index": "last-log-from-clientip"},"sync": {"time": {"field": "timestamp","delay": "60s"}},"retention_policy": {"time": {"field": "timestamp","max_age": "30d"}},"settings": {"max_page_search_size": 500}}
| データをグループ化するためのフィールドを指定します。 | |
| データをソートするために使用される日付フィールドを指定します。 | |
| ソースインデックスの変更をチェックするための変換の間隔を設定します。 | |
| ソースインデックスと宛先インデックスを同期するために使用される時間フィールドと遅延設定を含みます。 | |
| 変換の保持ポリシーを指定します。設定された値より古いドキュメントは宛先インデックスから削除されます。 |
変換を作成した後は、それを開始します:
Python
resp = client.transform.start_transform(transform_id="last-log-from-clientip",)print(resp)
Ruby
response = client.transform.start_transform(transform_id: 'last-log-from-clientip')puts response
Js
const response = await client.transform.startTransform({transform_id: "last-log-from-clientip",});console.log(response);
コンソール
POST _transform/last-log-from-clientip/_start
変換がデータを処理した後、宛先インデックスを検索します:
Python
resp = client.search(index="last-log-from-clientip",)print(resp)
Ruby
response = client.search(index: 'last-log-from-clientip')puts response
Js
const response = await client.search({index: "last-log-from-clientip",});console.log(response);
コンソール
GET last-log-from-clientip/_search
検索結果は、各クライアントIPに対してこのようなデータを示します:
Js
{"_index" : "last-log-from-clientip","_id" : "MOeHH_cUL5urmartKj-b5UQAAAAAAAAA","_score" : 1.0,"_source" : {"referer" : "http://twitter.com/error/don-lind","request" : "/elasticsearch","agent" : "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322)","extension" : "","memory" : null,"ip" : "0.72.176.46","index" : "kibana_sample_data_logs","message" : "0.72.176.46 - - [2018-09-18T06:31:00.572Z] \"GET /elasticsearch HTTP/1.1\" 200 7065 \"-\" \"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322)\"","url" : "https://www.elastic.co/downloads/elasticsearch","tags" : ["success","info"],"geo" : {"srcdest" : "IN:PH","src" : "IN","coordinates" : {"lon" : -124.1127917,"lat" : 40.80338889},"dest" : "PH"},"utc_time" : "2021-05-04T06:31:00.572Z","bytes" : 7065,"machine" : {"os" : "ios","ram" : 12884901888},"response" : 200,"clientip" : "0.72.176.46","host" : "www.elastic.co","event" : {"dataset" : "sample_web_logs"},"phpmemory" : null,"timestamp" : "2021-05-04T06:31:00.572Z"}}
この変換は、次のような質問に答えるのを容易にします:
- 特定のIPアドレスに関連付けられた最も最近のログイベントは何でしたか?
変換の例
これらの例は、データから有用な洞察を導き出すために変換を使用する方法を示しています。すべての例は、Kibanaのサンプルデータセットのいずれかを使用しています。より詳細なステップバイステップの例については、チュートリアル:eCommerceサンプルデータの変換を参照してください。
- 最高の顧客を見つける
- 最も遅延の多い航空会社を見つける
- 疑わしいクライアントIPを見つける
- 各IPアドレスの最後のログイベントを見つける
- サーバーに最も多くのバイトを送信したクライアントIPを見つける
- 顧客IDによる顧客名とメールアドレスの取得
Python
resp = client.transform.preview_transform(source={"index": "kibana_sample_data_logs"},pivot={"group_by": {"timestamp": {"date_histogram": {"field": "timestamp","fixed_interval": "1h"}}},"aggregations": {"bytes.max": {"max": {"field": "bytes"}},"top": {"top_metrics": {"metrics": [{"field": "clientip"},{"field": "geo.src"}],"sort": {"bytes": "desc"}}}}},)print(resp)
Js
const response = await client.transform.previewTransform({source: {index: "kibana_sample_data_logs",},pivot: {group_by: {timestamp: {date_histogram: {field: "timestamp",fixed_interval: "1h",},},},aggregations: {"bytes.max": {max: {field: "bytes",},},top: {top_metrics: {metrics: [{field: "clientip",},{field: "geo.src",},],sort: {bytes: "desc",},},},},},});console.log(response);
コンソール
POST _transform/_preview{"source": {"index": "kibana_sample_data_logs"},"pivot": {"group_by": {"timestamp": {"date_histogram": {"field": "timestamp","fixed_interval": "1h"}}},"aggregations": {"bytes.max": {"max": {"field": "bytes"}},"top": {"top_metrics": {"metrics": [{"field": "clientip"},{"field": "geo.src"}],"sort": {"bytes": "desc"}}}}}}
データは、1時間の間隔で時間フィールドの[bytes]のデータでグループ化されます。 |
|
bytesフィールドの最大値を計算します。 |
|
トップドキュメントを返すフィールド(clientipとgeo.src)とソート方法(最高のbytes値を持つドキュメント)を指定します。 |
上記のAPI呼び出しは、次のようなレスポンスを返します:
Js
{"preview" : [{"top" : {"clientip" : "223.87.60.27","geo.src" : "IN"},"bytes" : {"max" : 6219},"timestamp" : "2021-04-25T00:00:00.000Z"},{"top" : {"clientip" : "99.74.118.237","geo.src" : "LK"},"bytes" : {"max" : 14113},"timestamp" : "2021-04-25T03:00:00.000Z"},{"top" : {"clientip" : "218.148.135.12","geo.src" : "BR"},"bytes" : {"max" : 4531},"timestamp" : "2021-04-25T04:00:00.000Z"},...]}
顧客IDによる顧客名とメールアドレスの取得
この例では、ecommerceサンプルデータセットを使用して、顧客IDに基づくエンティティ中心のインデックスを作成し、top_metrics集計を使用して顧客名とメールアドレスを取得します。
データをcustomer_idでグループ化し、top_metrics集計を追加します。ここで、metricsはemail、customer_first_name.keyword、customer_last_name.keywordフィールドです。top_metricsをorder_dateで降順にソートします。API呼び出しは次のようになります:
Python
resp = client.transform.preview_transform(source={"index": "kibana_sample_data_ecommerce"},pivot={"group_by": {"customer_id": {"terms": {"field": "customer_id"}}},"aggregations": {"last": {"top_metrics": {"metrics": [{"field": "email"},{"field": "customer_first_name.keyword"},{"field": "customer_last_name.keyword"}],"sort": {"order_date": "desc"}}}}},)print(resp)
Js
const response = await client.transform.previewTransform({source: {index: "kibana_sample_data_ecommerce",},pivot: {group_by: {customer_id: {terms: {field: "customer_id",},},},aggregations: {last: {top_metrics: {metrics: [{field: "email",},{field: "customer_first_name.keyword",},{field: "customer_last_name.keyword",},],sort: {order_date: "desc",},},},},},});console.log(response);
コンソール
POST _transform/_preview{"source": {"index": "kibana_sample_data_ecommerce"},"pivot": {"group_by": {"customer_id": {"terms": {"field": "customer_id"}}},"aggregations": {"last": {"top_metrics": {"metrics": [{"field": "email"},{"field": "customer_first_name.keyword"},{"field": "customer_last_name.keyword"}],"sort": {"order_date": "desc"}}}}}}
データはterms集計でcustomer_idフィールドでグループ化されます。 |
|
| 返すフィールド(メールと名前フィールド)を指定し、注文日で降順にソートします。 |
APIは、次のようなレスポンスを返します:
Js
{"preview" : [{"last" : {"customer_last_name.keyword" : "Long","customer_first_name.keyword" : "Recip","email" : "[email protected]"},"customer_id" : "10"},{"last" : {"customer_last_name.keyword" : "Jackson","customer_first_name.keyword" : "Fitzgerald","email" : "[email protected]"},"customer_id" : "11"},{"last" : {"customer_last_name.keyword" : "Cross","customer_first_name.keyword" : "Brigitte","email" : "[email protected]"},"customer_id" : "12"},...]}
