検索におけるインジェストパイプライン
Elasticsearch API または Kibana UI を通じてインジェストパイプラインを管理できます。
検索の下にある コンテンツ UI には、検索ユースケース(非時系列データ)に最適化されたインデックスを作成および管理するためのツールセットがあります。この UI でもインジェストパイプラインを管理できます。
コンテンツ UI でのパイプラインの検索
これらの UI ツールを使用してインジェストパイプラインを操作するには、検索最適化された Elasticsearch インデックスの パイプライン タブを使用します。
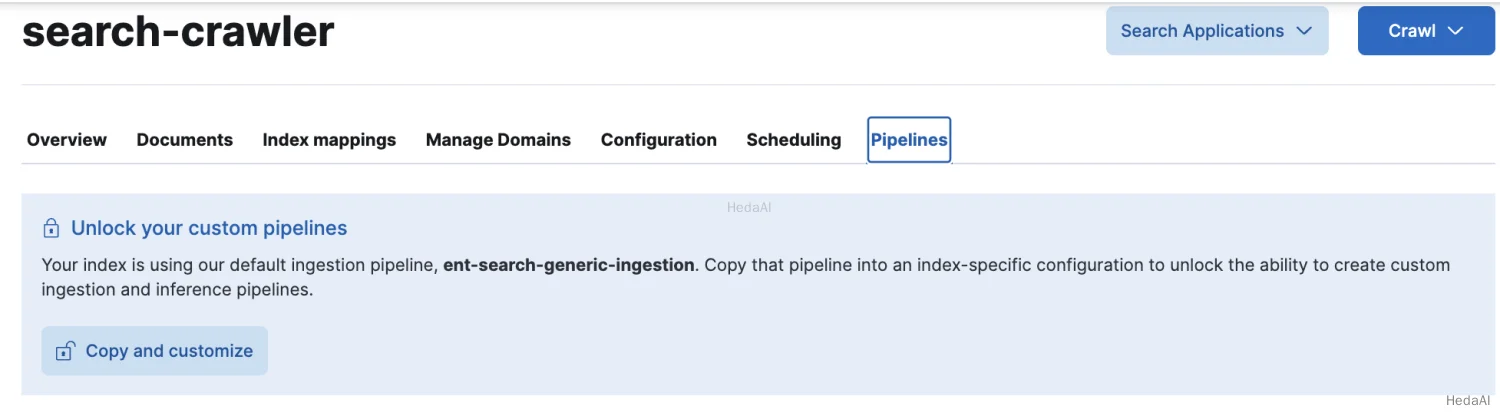
Kibana UI でこのタブを見つけるには:
- 1. 検索 > コンテンツ > Elasticsearch インデックス に移動します。
- 2. 作業したいインデックスを選択します。たとえば、
search-my-index。 - 3. インデックスの概要ページで、パイプライン タブを開きます。
- 4. ここから、カスタムパイプラインを作成し、ML 推論パイプラインを設定する手順に従うことができます。
このタブは、次のスクリーンショットで強調表示されています:
概要
これらのツールは、ドキュメントのカスタマイズと後処理のレイヤーを提供することで特に役立ちます。たとえば:
- バイナリデータタイプからのテキストの一貫した抽出を提供
- 一貫したフォーマットを保証
- 一貫したサニタイズ手順を提供(電話番号や社会保障番号などの PII を削除)
生産準備が整ったパイプラインをゼロから設定および管理するのは多くの作業です。エラーハンドリング、条件付き実行、シーケンシング、バージョニング、モジュール化などの考慮事項をすべて考慮する必要があります。
この目的のために、検索ユースケース用のインデックスを作成する際には、(Elastic web crawler、Elastic connector、および API インデックスを含む)、各インデックスには、検索用にコンテンツを最適化する複数のプロセッサを持つパイプラインがすでに設定されています。
このパイプラインは ent-search-generic-ingestion と呼ばれます。これは「管理された」パイプラインであり(変更すべきではないことを意味します)、Kibana UI または Elasticsearch API を介してその詳細を表示できます。また、その内容についての詳細を以下で読むことができます。
これらのプロセッサのいくつかを実行するかどうかを制御できます。すべての機能はデフォルトで有効になっていますが、オプトアウトが可能です。Elastic crawler および Elastic connectors については、インデックスごとにオプトアウト(または再オプトイン)でき、選択は保存されます。API インデックスについては、ドキュメントに特定のフィールドを含めることでオプトアウト(または再オプトイン)できます。詳細については以下を参照してください。
デプロイメントレベルでは、すべての新しいインデックスのデフォルト設定を変更できます。これは既存のインデックスには影響しません。
各インデックスは、カスタマイズ可能な処理を持つインデックス固有のインジェストパイプラインを簡単に作成する機能も提供します。その追加の柔軟性が必要な場合は、パイプライン設定に移動し、「コピーしてカスタマイズ」を選択することでカスタムパイプラインを作成できます。これにより、インデックスの ent-search-generic-ingestion の使用が次の 3 つの新しく生成されたパイプラインに置き換えられます:
- 1.
<index-name> - 2.
<index-name>@custom - 3.
<index-name>@ml-inference
ent-search-generic-ingestion と同様に、これらの最初のものは「管理された」ものであり、他の 2 つはニーズに合わせて変更することができ、変更すべきです。これらのパイプラインはプラットフォームツール(Kibana UI、Elasticsearch API)を使用して表示でき、その内容についての詳細を以下で読むことができます。
パイプライン設定
パイプライン自体とは別に、パイプラインの個々の機能を制御するいくつかの構成オプションがあります。
- バイナリコンテンツの抽出 - これは、バイナリドキュメントを処理し、テキストコンテンツを抽出するかどうかを制御します。
- 空白の削減 - これは、連続した空白、先頭の空白、および末尾の空白を削除するかどうかを制御します。これにより、一部の検索体験でより多くのコンテンツを表示できるようになります。
- ML 推論の実行 - インデックス固有のパイプラインでのみ利用可能です。これは、オプションの
<index-name>@ml-inferenceパイプラインを実行するかどうかを制御します。デフォルトで有効です。
Elastic web crawler およびコネクタについては、インデックスごとにオプトインまたはオプトアウトできます。これらの設定は、特定のインデックスに対応するドキュメントの .elastic-connectors インデックスに Elasticsearch に保存されます。これらの設定は、直接変更するか、Kibana UI の 検索 > コンテンツ > インデックス > <あなたのインデックス> > パイプライン > 設定 から変更できます。
デプロイメント全体のデフォルトを変更することもできます。これらの設定は、.elastic-connectors の Elasticsearch マッピングの _meta セクションに保存されます。これらの設定は、直接変更するか、Kibana UI の 検索 > コンテンツ > 設定 タブから変更できます。デプロイメント全体のデフォルトを変更しても、既存のインデックスには影響せず、新しく作成されたインデックスのデフォルトにのみ影響します。これらのデフォルトは、インデックス固有の設定によって上書き可能です。
API の使用
これらの設定は「API を使用する」インデックスには永続化されません。代わりに、これらの設定を変更すると、リアルタイムで表示される例の cURL リクエストが変更されます。cURL リクエストの例のドキュメントには、3 つのアンダースコア接頭辞フィールドが含まれていることに注意してください:
Js
{..."_extract_binary_content": true,"_reduce_whitespace": true,"_run_ml_inference": true}
これらの特別なフィールドのいずれかを省略することは、false の値を指定するのと同じです。
インデックスリクエストでパイプラインも指定する必要があります。これは、例の cURL リクエストにも示されています。
パイプラインが指定されていない場合、アンダースコア接頭辞のフィールドは実際にインデックスされ、処理の動作には影響しません。
詳細
ent-search-generic-ingestion リファレンス
このパイプラインには、Elasticsearch Ingest Pipelines API または Kibana の Stack Management > Ingest Pipelines UI を介してアクセスできます。
このパイプラインは「管理された」パイプラインです。つまり、編集することを意図していません。このパイプラインを手動で編集または更新すると、意図しない動作や将来のアップグレードの難しさが生じる可能性があります。カスタマイズを行いたい場合は、インデックス固有のパイプライン(以下を参照)を利用することをお勧めします。特に <index-name>@custom パイプライン を利用してください。
プロセッサ
- 1.
attachment- これは、Attachment プロセッサを使用して、ドキュメントの_attachmentフィールドに保存されているバイナリデータをプレーンテキストとメタデータのネストされたオブジェクトに変換します。 - 2.
set_body- これは、Set プロセッサを使用して、前のステップから抽出されたプレーンテキストをコピーし、bodyフィールドのドキュメントに永続化します。 - 3.
remove_replacement_chars- これは、Gsub プロセッサを使用して、bodyフィールドから「�」のような文字を削除します。 - 4.
remove_extra_whitespace- これは、Gsub プロセッサを使用して、bodyフィールド内の連続する空白文字を単一のスペースに置き換えます。すべてのユースケースに完璧ではありませんが(以下で無効にする方法を参照)、これにより検索体験でより多くのコンテンツとハイライトが表示され、検索結果の空白が少なくなります。 - 5.
trim- これは、Trim プロセッサを使用して、bodyフィールドから残りの先頭または末尾の空白を削除します。 - 6.
remove_meta_fields- このパイプラインの最終ステップでは、Remove プロセッサを使用して、パイプライン内の他の場所で一時的なストレージや制御フローパラメータとして使用される可能性のある特別なフィールドを削除します。
制御フローパラメータ
ent-search-generic-ingestion パイプラインは、常にすべてのプロセッサを実行するわけではありません。各ドキュメントの内容に基づいてプロセッサを条件付きで実行する機能を利用します。
_extract_binary_content- このフィールドが存在し、ソースドキュメントでtrueの値を持つ場合、パイプラインはattachment、set_body、およびremove_replacement_charsプロセッサを実行しようとします。_attachmentフィールドに base64 エンコードされたバイナリデータが入力されている必要があります。attachmentプロセッサが出力を持つためには、_extract_binary_contentフィールドが欠落しているか、ソースドキュメントでfalseの場合、これらのプロセッサはスキップされます。_reduce_whitespace- このフィールドが存在し、ソースドキュメントでtrueの値を持つ場合、パイプラインはremove_extra_whitespaceおよびtrimプロセッサを実行しようとします。これらのプロセッサはbodyフィールドにのみ適用されます。_reduce_whitespaceフィールドが欠落しているか、ソースドキュメントでfalseの場合、これらのプロセッサはスキップされます。
クローラー、ネイティブコネクタ、およびコネクタクライアントは、インデックスのパイプラインタブの設定に基づいてこれらの制御フローパラメータを自動的に追加します。新しいインデックスが作成される際の設定を制御するには、デプロイメント全体のコンテンツ設定を参照してください。パイプライン設定を参照してください。
インデックス固有のインジェストパイプライン
インデックスの Kibana UI で、パイプラインタブをクリックし、次に 設定 > コピーしてカスタマイズ を選択すると、インデックス固有の 3 つのパイプラインをすぐに生成できます。これらの 3 つのパイプラインは、インデックスの ent-search-generic-ingestion を置き換えます。この操作で失われるものはなく、<index-name> パイプラインは ent-search-generic-ingestion パイプラインの機能のスーパーセットです。
「コピーしてカスタマイズ」ボタンは、すべての Elastic サブスクリプションレベルで利用できるわけではありません。Elastic サブスクリプションページを参照して、Elastic Cloud および 自己管理 デプロイメントを確認してください。
リファレンス
このパイプラインは、ent-search-generic-ingestion パイプライン に非常に似ており、2 つの追加プロセッサがあります。
このパイプラインの名前を変更しないでください。
このパイプラインは「管理された」パイプラインです。つまり、編集することを意図していません。このパイプラインを手動で編集または更新すると、意図しない動作や将来のアップグレードの難しさが生じる可能性があります。カスタマイズを行いたい場合は、<index-name>@custom パイプラインを利用することをお勧めします。
プロセッサ
ent-search-generic-ingestion パイプライン から継承されたプロセッサに加えて、インデックス固有のパイプラインは次のことも定義します:
index_ml_inference_pipeline- これは、@Pipeline プロセッサを使用して<index-name>@ml-inferenceパイプラインを実行します。このプロセッサは、ソースドキュメントに_run_ml_inferenceフィールドがtrueの値を持つ場合にのみ実行されます。index_custom_pipeline- これは、@Pipeline プロセッサを使用して<index-name>@customパイプラインを実行します。
制御フローパラメータ
ent-search-generic-ingestion パイプラインと同様に、<index-name> パイプラインは常にすべてのプロセッサを実行するわけではありません。_extract_binary_content および _reduce_whitespace 制御フローパラメータに加えて、<index-name> パイプラインは次のこともサポートします:
_run_ml_inference- このフィールドが存在し、ソースドキュメントでtrueの値を持つ場合、パイプラインはindex_ml_inference_pipelineプロセッサを実行しようとします。_run_ml_inferenceフィールドが欠落しているか、ソースドキュメントでfalseの場合、このプロセッサはスキップされます。
クローラー、ネイティブコネクタ、およびコネクタクライアントは、インデックスのパイプラインタブの設定に基づいてこれらの制御フローパラメータを自動的に追加します。新しいインデックスが作成される際の設定を制御するには、デプロイメント全体のコンテンツ設定を参照してください。パイプライン設定を参照してください。
@ml-inference リファレンス
このパイプラインは最初は空です(プロセッサなし)が、Kibana UI を介してインデックスのパイプラインタブまたは Stack Management > Ingest Pipelines ページから追加できます。ent-search-generic-ingestion パイプラインおよび <index-name> パイプラインとは異なり、このパイプラインは「管理された」ものではありません。
コンテンツ UI でインデックスに 1 つ以上の ML 推論パイプラインを追加することができます。このパイプラインは、インデックスに構成されたすべての ML 推論パイプラインのコンテナとして機能します。インデックスに追加された各 ML 推論パイプラインは、<index-name>@ml-inference 内で pipeline プロセッサを使用して参照されます。
このパイプラインの名前を変更しないでください。
ML モデルとそれらのモデルを使用する ML 推論パイプラインを管理するには、monitor_ml Elasticsearch クラスターの権限が必要です。
@custom リファレンス
このパイプラインは最初は空です(プロセッサなし)が、Kibana UI を介してインデックスのパイプラインタブまたは Stack Management > Ingest Pipelines ページから追加できます。ent-search-generic-ingestion パイプラインおよび <index-name> パイプラインとは異なり、このパイプラインは「管理された」ものではありません。
このパイプラインに追加や編集を行うことが奨励されますが、名前はそのままにしておく必要があります。これにより、データのカスタム処理や変換を追加するための便利なフックが提供されます。利用可能なオプションを確認するには、インジェストパイプラインのドキュメントを必ずお読みください。
このパイプラインの名前を変更しないでください。
アップグレードノート
アップグレードノートを表示するには展開してください
app_search_crawler- 8.3 以降、App Search web crawler はこのパイプラインを使用してバイナリコンテンツの抽出を行っています。このパイプラインとその使用法については、App Search ガイドで詳しく読むことができます。8.3 から 8.5 以上にアップグレードする際は、app_search_crawlerパイプラインに対して行った変更に注意してください。これらの変更は、各インデックスの<index-name>@customパイプラインに再適用する必要があります。これにより、一貫したデータ処理体験が保証されます。8.5 以降では、バイナリコンテンツを有効にするためのインデックス設定が、App Search ガイドで言及されている構成に加えて必要です。ent_search_crawler- 8.4 以降、Elastic web crawler はこのパイプラインを使用してバイナリコンテンツの抽出を行っています。このパイプラインとその使用法については、Elastic web crawler ガイドで詳しく読むことができます。8.4 から 8.5 以上にアップグレードする際は、ent_search_crawlerパイプラインに対して行った変更に注意してください。これらの変更は、各インデックスの<index-name>@customパイプラインに再適用する必要があります。これにより、一貫したデータ処理体験が保証されます。8.5 以降では、バイナリコンテンツを有効にするためのインデックス設定が、Elastic web crawler ガイドで言及されている構成に加えて必要です。ent-search-generic-ingestion- 8.5 以降、ネイティブコネクタ、コネクタクライアント、および新しい(>8.4)Elastic web crawler インデックスは、デフォルトでこのパイプラインを使用します。このパイプラインについては、上記の詳細を読むことができます。このパイプラインは「管理された」ものであり、app_search_crawlerおよび/またはent_search_crawlerに対して行った変更はent-search-generic-ingestionに対して行うべきではありません。したがって、そのようなカスタマイズが必要な場合は、インデックス固有のインジェストパイプラインを利用し、すべての変更を<index-name>@customパイプラインに配置する必要があります。
