レア用語の集約
分布のロングテールにある「レア」な用語を見つけるためのマルチバケット値ソースベースの集約です。概念的には、これは terms 集約のようなもので、_count 昇順でソートされています。用語集約のドキュメント に記載されているように、実際に terms agg をカウント昇順で並べることには無限の誤差があります。代わりに、rare_terms 集約を使用するべきです。
構文
単独での rare_terms 集約は次のようになります:
Js
{"rare_terms": {"field": "the_field","max_doc_count": 1}}
表 50. rare_terms パラメータ
| パラメータ名 | 説明 | 必須 | デフォルト値 |
field |
レア用語を見つけたいフィールド | 必須 | |
max_doc_count |
用語が出現する最大ドキュメント数。 | オプション | 1 |
precision |
内部 CuckooFilters の精度。精度が小さいほど、 より良い近似が得られますが、メモリ使用量が増加します。 0.00001 より小さくすることはできません |
オプション | 0.001 |
include |
集約に含めるべき用語 | オプション | |
exclude |
集約から除外すべき用語 | オプション | |
missing |
集約されるフィールドがない場合に使用される値 | オプション |
例:
Python
resp = client.search(aggs={"genres": {"rare_terms": {"field": "genre"}}},)print(resp)
Ruby
response = client.search(body: {aggregations: {genres: {rare_terms: {field: 'genre'}}}})puts response
Js
const response = await client.search({aggs: {genres: {rare_terms: {field: "genre",},},},});console.log(response);
コンソール
GET /_search{"aggs": {"genres": {"rare_terms": {"field": "genre"}}}}
コンソール-結果
{..."aggregations": {"genres": {"buckets": [{"key": "swing","doc_count": 1}]}}}
この例では、唯一のバケットは「スイング」バケットです。なぜなら、それが1つのドキュメントにしか出現しない唯一の用語だからです。max_doc_count を 2 に増やすと、さらにいくつかのバケットが表示されます:
Python
resp = client.search(aggs={"genres": {"rare_terms": {"field": "genre","max_doc_count": 2}}},)print(resp)
Ruby
response = client.search(body: {aggregations: {genres: {rare_terms: {field: 'genre',max_doc_count: 2}}}})puts response
Js
const response = await client.search({aggs: {genres: {rare_terms: {field: "genre",max_doc_count: 2,},},},});console.log(response);
コンソール
GET /_search{"aggs": {"genres": {"rare_terms": {"field": "genre","max_doc_count": 2}}}}
これにより、doc_count が 2 の「ジャズ」用語が表示されます:
コンソール-結果
{..."aggregations": {"genres": {"buckets": [{"key": "swing","doc_count": 1},{"key": "jazz","doc_count": 2}]}}}
最大ドキュメント数
max_doc_count パラメータは、用語が持つことができるドキュメント数の上限を制御するために使用されます。rare_terms agg には terms agg のようなサイズ制限はありません。これは、max_doc_count 基準に一致する用語が返されることを意味します。この集約は、terms 集約に影響を与える昇順の順序の問題を回避するためにこのように機能します。
ただし、選択が誤っていると、大量の結果が返される可能性があります。この設定の危険を制限するために、最大 max_doc_count は 100 です。
バケットの最大制限
レア用語の集約は、その動作のために他の集約よりも search.max_buckets ソフトリミットに引っかかりやすいです。max_bucket ソフトリミットは、集約が結果を収集している間にシャードごとに評価されます。用語がシャードでは「レア」であるが、すべてのシャードの結果が統合されると「レアでない」になる可能性があります。これは、個々のシャードが自分のローカルビューしか持たないため、実際にはレアでないバケットを多く収集する傾向があることを意味します。このリストは最終的に、コーディネートノードで正しい小さなレア用語のリストにプルーニングされますが、シャードはすでに max_buckets ソフトリミットに引っかかり、リクエストを中止している可能性があります。
「レア」用語が多く存在するフィールドで集約する場合、max_buckets ソフトリミットを増やす必要があるかもしれません。あるいは、結果をフィルタリングしてレアな値を少なくする方法を見つける必要があるかもしれません(小さな時間範囲、カテゴリでフィルタリングなど)、または「レア」の定義を再評価する必要があるかもしれません(例えば、何かが 100,000 回出現する場合、それは本当に「レア」でしょうか?)
ドキュメント数は概算です
データセット内の「レア」用語を決定するための単純な方法は、すべての値をマップに配置し、各ドキュメントを訪れるたびにカウントを増やし、次に下位 n 行を返すことです。これは、わずかにサイズの大きいデータセットを超えてスケールしません。各シャードから「上位 n」値のみを保持するシャーディングアプローチ(terms 集約のように)は、問題のロングテールの性質により、「上位 n」下位値を見つけることが不可能であるため失敗します。
代わりに、レア用語の集約は異なる近似アルゴリズムを使用します:
- 1. 値は初めて見たときにマップに配置されます。
- 2. 用語の各追加出現は、マップ内のカウンターを増加させます。
- 3. カウンターが
max_doc_count閾値を超える場合、用語はマップから削除され、CuckooFilter に配置されます。 - 4. 各用語に対して CuckooFilter が参照されます。値がフィルター内にある場合、それはすでに閾値を超えていることが知られており、スキップされます。
実行後、値のマップは max_doc_count 閾値未満の「レア」用語のマップです。このマップと CuckooFilter は、他のすべてのシャードとマージされます。閾値を超える用語(または異なるシャードの CuckooFilter に出現する用語)がある場合、その用語はマージされたリストから削除されます。最終的な値のマップがユーザーに「レア」用語として返されます。
CuckooFilters は偽陽性を返す可能性があります(実際には存在しない値がコレクションに存在すると言うことができます)。CuckooFilter が用語が閾値を超えているかどうかを確認するために使用されているため、CuckooFilter からの偽陽性は、値が一般的であると誤って言うことになります(したがって、最終的なバケットリストから除外されます)。実際には、これは集約が偽陰性の動作を示すことを意味します。なぜなら、フィルターが一般的に近似セットメンバーシップスケッチの考え方とは「逆」に使用されているからです。
CuckooFilters の詳細は、次の論文で説明されています:
Fan, Bin, et al. 「Cuckoo filter: Practically better than bloom.」 第10回 ACM 国際会議の議事録、ネットワーキング実験と技術の新興に関する会議。ACM, 2014.
精度
内部 CuckooFilter は近似的な性質を持っていますが、偽陰性率は precision パラメータで制御できます。これにより、ユーザーはより正確な結果のために、より多くのランタイムメモリを取引することができます。
デフォルトの精度は 0.001 で、最小(例えば、最も正確で最大のメモリオーバーヘッド)は 0.00001 です。以下は、精度と異なる用語の数が集約の精度にどのように影響するかを示すいくつかのチャートです。
X軸は集約が見た異なる値の数を示し、Y軸はパーセント誤差を示します。各ラインシリーズは1つの「レア度」条件を表します(1つのレアアイテムから100,000のレアアイテムまで)。例えば、オレンジの「10」ラインは、値のうち10が「レア」であることを意味します(doc_count == 1)、1-20mの異なる値の中で(残りの値は doc_count > 1 を持っている)。
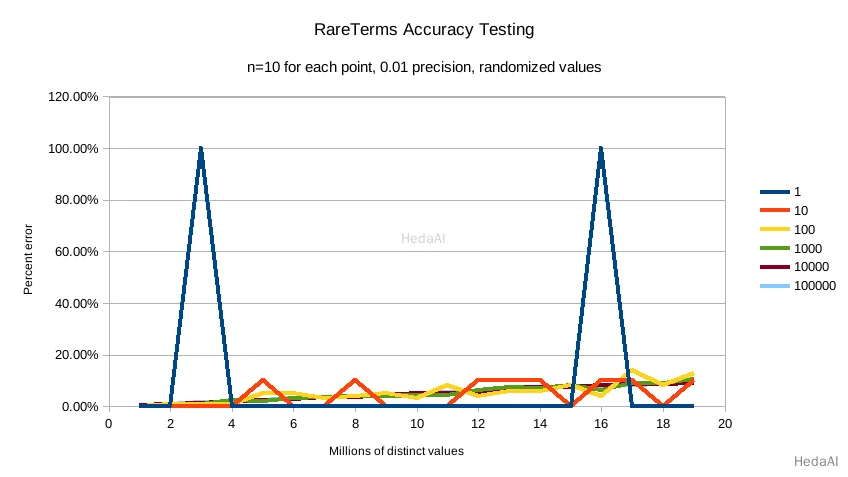
この最初のチャートは精度 0.01 を示しています:
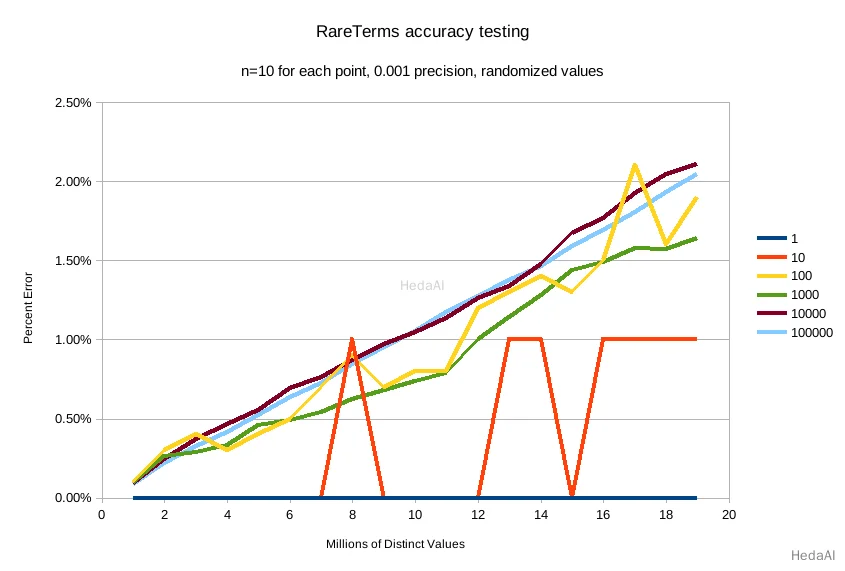
そして、デフォルトの精度 0.001:
最後に precision 0.0001:
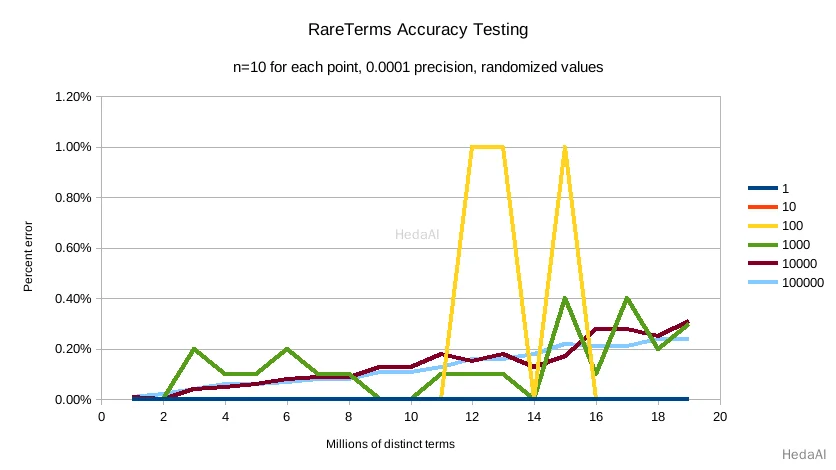
デフォルトの精度 0.001 は、テスト条件での精度を < 2.5% に維持し、異なる値の数が増えるにつれて精度が制御された線形的な方法で徐々に低下します。
デフォルトの精度 0.001 は、n が集約が見た異なる値の数である 1.748⁻⁶ * n バイトのメモリプロファイルを持ちます(おおよそ目視で確認することもできます。例えば、2000万のユニークな値は約30MBのメモリです)。メモリ使用量は、選択された精度に関係なく、異なる値の数に対して線形です。精度は、このチャートで見られるように、メモリプロファイルの傾斜にのみ影響します:
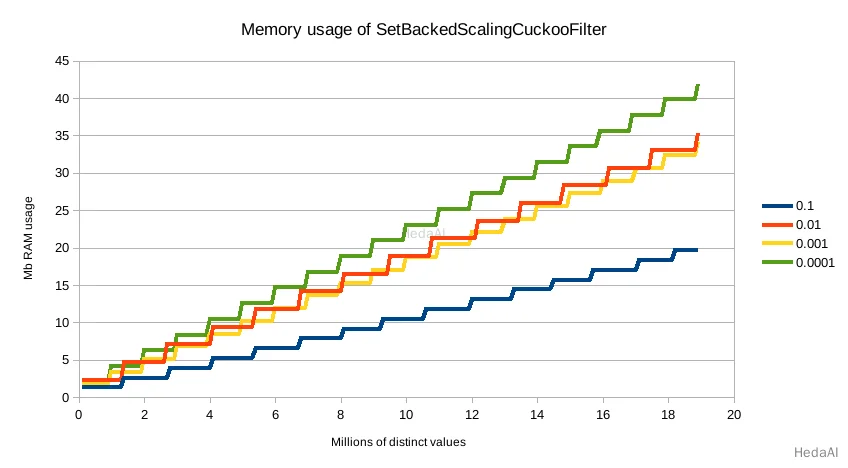
比較のために、20百万バケットの同等の用語集約はおおよそ 20m * 69b == ~1.38gb になります(69バイトは空のバケットコストの非常に楽観的な推定であり、回路ブレーカーが考慮するものよりもはるかに低いです)。したがって、rare_terms agg は比較的重いですが、同等の用語集約よりも依然として桁違いに小さいです。
値のフィルタリング
バケットが作成される値をフィルタリングすることが可能です。これは、正規表現文字列または正確な値の配列に基づく include および exclude パラメータを使用して行うことができます。さらに、include 条項は partition 式を使用してフィルタリングできます。
正規表現による値のフィルタリング
Python
resp = client.search(aggs={"genres": {"rare_terms": {"field": "genre","include": "swi*","exclude": "electro*"}}},)print(resp)
Ruby
response = client.search(body: {aggregations: {genres: {rare_terms: {field: 'genre',include: 'swi*',exclude: 'electro*'}}}})puts response
Js
const response = await client.search({aggs: {genres: {rare_terms: {field: "genre",include: "swi*",exclude: "electro*",},},},});console.log(response);
コンソール
GET /_search{"aggs": {"genres": {"rare_terms": {"field": "genre","include": "swi*","exclude": "electro*"}}}}
上記の例では、swi で始まるすべてのタグのためにバケットが作成されますが、electro で始まるものは除外されます(したがって、タグ swing は集約されますが、electro_swing は集約されません)。include 正規表現は、集約されることが「許可されている」値を決定し、exclude は集約されるべきでない値を決定します。両方が定義されている場合、exclude が優先され、つまり include が最初に評価され、その後 exclude が評価されます。
構文は regexp クエリ と同じです。
正確な値による値のフィルタリング
正確な値に基づいて一致させるために、include および exclude パラメータは、インデックス内で見つかる用語を表す文字列の配列を単純に取ることができます:
Python
resp = client.search(aggs={"genres": {"rare_terms": {"field": "genre","include": ["swing","rock"],"exclude": ["jazz"]}}},)print(resp)
Ruby
response = client.search(body: {aggregations: {genres: {rare_terms: {field: 'genre',include: ['swing','rock'],exclude: ['jazz']}}}})puts response
Js
const response = await client.search({aggs: {genres: {rare_terms: {field: "genre",include: ["swing", "rock"],exclude: ["jazz"],},},},});console.log(response);
コンソール
GET /_search{"aggs": {"genres": {"rare_terms": {"field": "genre","include": [ "swing", "rock" ],"exclude": [ "jazz" ]}}}}
欠損値
missing パラメータは、値が欠損しているドキュメントがどのように扱われるべきかを定義します。デフォルトでは無視されますが、値があるかのように扱うことも可能です。
Python
resp = client.search(aggs={"genres": {"rare_terms": {"field": "genre","missing": "N/A"}}},)print(resp)
Ruby
response = client.search(body: {aggregations: {genres: {rare_terms: {field: 'genre',missing: 'N/A'}}}})puts response
Js
const response = await client.search({aggs: {genres: {rare_terms: {field: "genre",missing: "N/A",},},},});console.log(response);
コンソール
GET /_search{"aggs": {"genres": {"rare_terms": {"field": "genre","missing": "N/A"}}}}
tags フィールドに値がないドキュメントは、N/A の値を持つドキュメントと同じバケットに入ります。 |
ネストされたレア用語とスコアリングサブ集約
レア用語の集約は breadth_first モードで動作する必要があります。なぜなら、ドキュメント数の閾値を超えたときに用語をプルーニングする必要があるからです。この要件により、レア用語の集約は depth_first を必要とする特定の集約の組み合わせと互換性がありません。特に、nested 内のスコアリングサブ集約は、全体の集約ツリーを depth_first モードで実行することを強制します。これにより、レア用語が depth_first を処理できないため、例外がスローされます。
具体的な例として、rare_terms 集約が nested 集約の子であり、rare_terms の子集約の1つがドキュメントスコアを必要とする場合(top_hits 集約のように)、これにより例外がスローされます。
