データノードのディスク容量を増やす
クラスター内のデータノードのディスク容量を増やすためには:
- 1. Elastic Cloudコンソールにログインします。
- 2. Elasticsearch Serviceパネルで、デプロイメント名に対応する
Manage deployment列の下にあるギアをクリックします。 - 3. 自動スケーリングが利用可能ですが有効になっていない場合は、有効にしてください。以下のようなバナーの
Enable autoscalingボタンをクリックすることで行えます: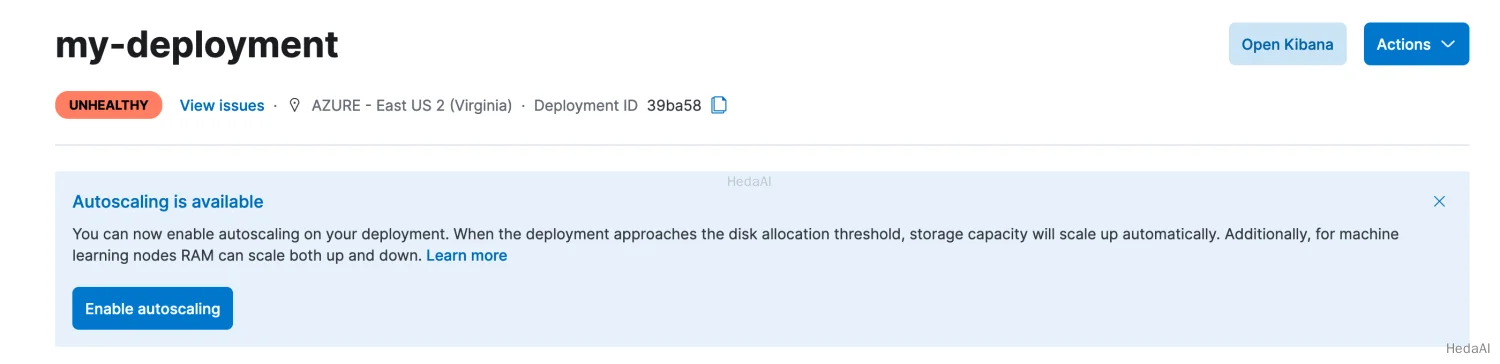
または、Actions > Edit deploymentに移動し、チェックボックスAutoscaleをチェックして、ページの下部にあるsaveをクリックします。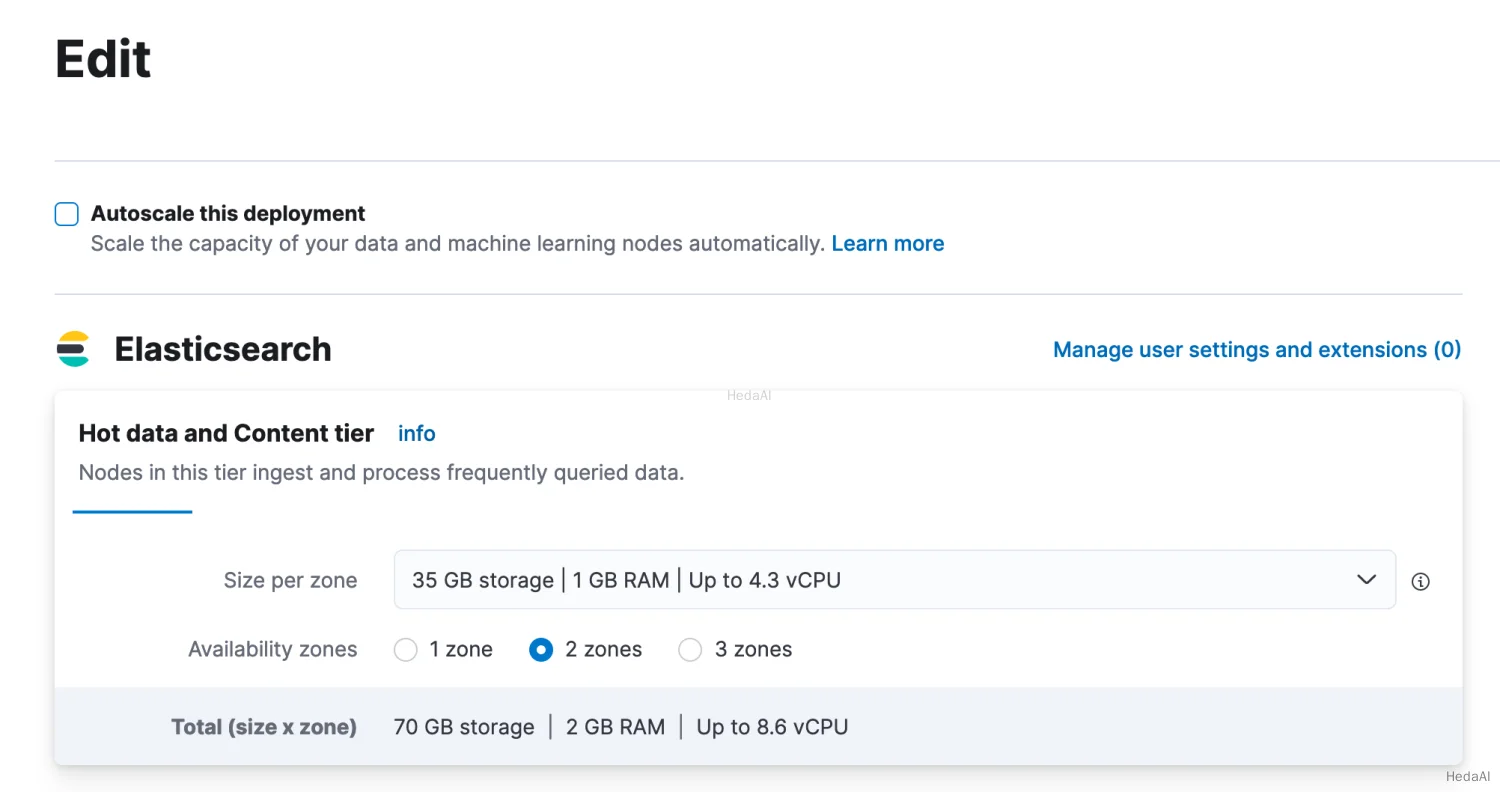
- 4. 自動スケーリングが成功した場合、クラスターは
healthyの状態に戻るはずです。クラスターがまだディスク不足の場合は、自動スケーリングが制限に達しているかどうかを確認してください。これについては、以下のバナーで通知されます: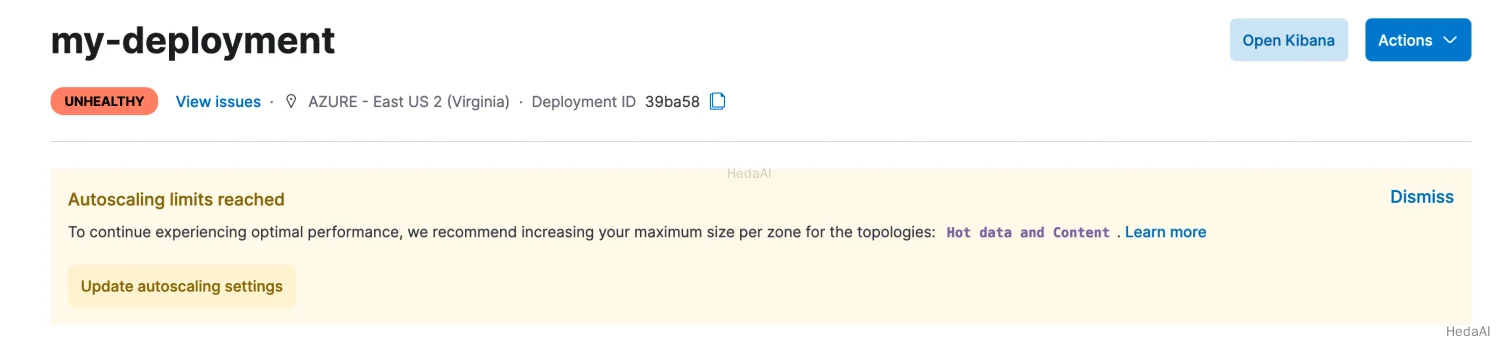
または、Actions > Edit deploymentに移動し、以下のようにLIMIT REACHEDラベルを探します: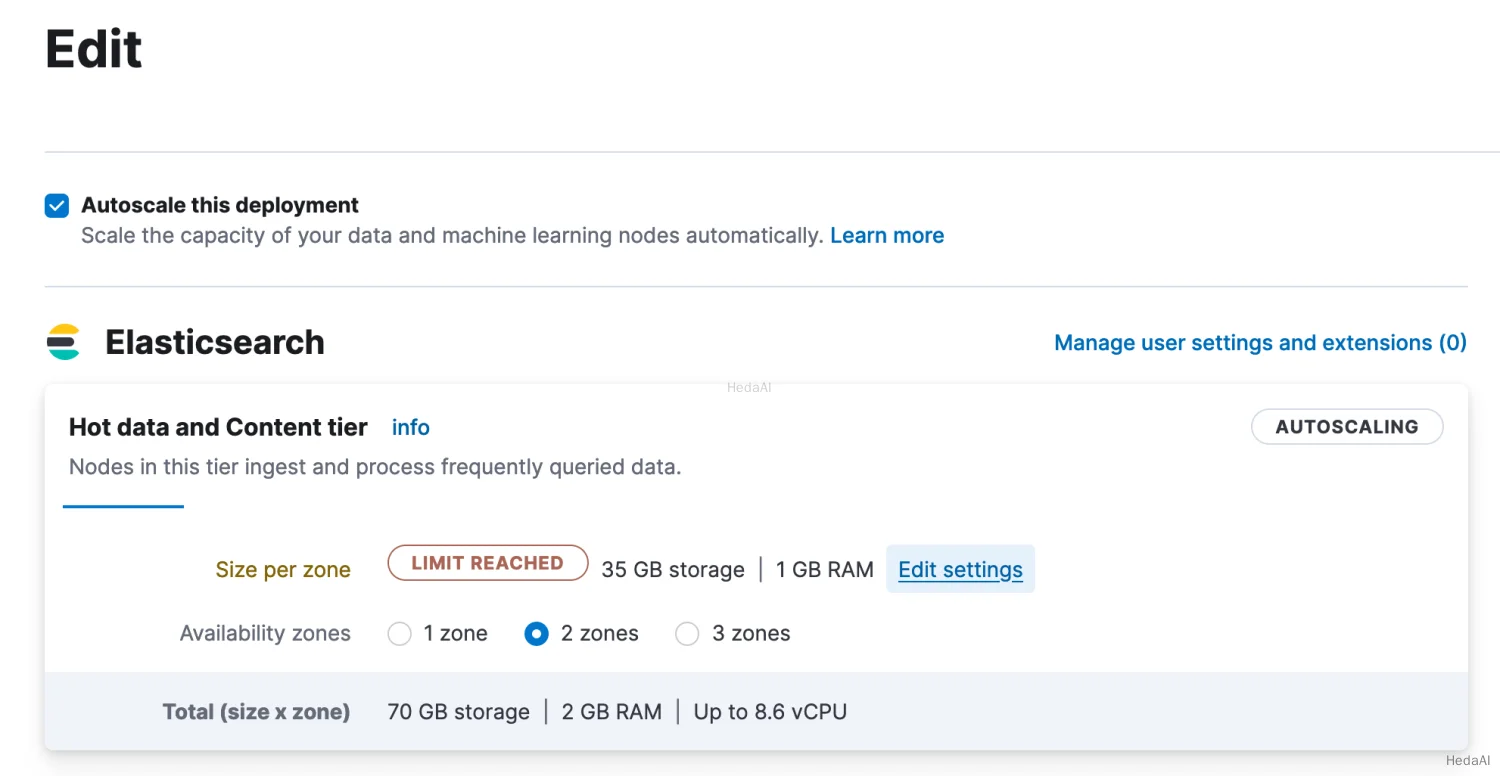
バナーが表示されている場合は、Update autoscaling settingsをクリックしてEditページに移動します。そうでない場合は、すでにEditページにいるので、Edit settingsをクリックして自動スケーリングの制限を増やします。変更を行った後、ページの下部にあるsaveをクリックします。
クラスター内のデータノードの容量を増やすためには、必要な追加ディスクスペースの量を計算する必要があります。
- 1. まず、どれだけのスペースが必要かを示す関連するディスクのしきい値を取得します。関連するしきい値は、凍結されたものを除くすべての層の高水位と、凍結層の凍結洪水段階の水位です。以下の例は、ホット層でのディスク不足を示しているため、高水位のみを取得します:
Python
resp = client.cluster.get_settings(include_defaults=True,filter_path="*.cluster.routing.allocation.disk.watermark.high*",)print(resp)
Ruby
response = client.cluster.get_settings(include_defaults: true,filter_path: '*.cluster.routing.allocation.disk.watermark.high*')puts response
Js
const response = await client.cluster.getSettings({include_defaults: "true",filter_path: "*.cluster.routing.allocation.disk.watermark.high*",});console.log(response);
Console
GET _cluster/settings?include_defaults&filter_path=*.cluster.routing.allocation.disk.watermark.high*
Console-Result
{"defaults": {"cluster": {"routing": {"allocation": {"disk": {"watermark": {"high": "90%","high.max_headroom": "150GB"}}}}}}}
上記は、ディスク不足を解決するためには、ディスク使用量を90%未満にするか、150GB以上の空き容量を確保する必要があることを意味します。このしきい値の動作については、こちらで詳しく読むことができます。
- 2. 次のステップは、現在のディスク使用量を確認することです。これにより、どれだけの追加スペースが必要かがわかります。簡単のために、私たちの例では1つのノードがありますが、関連するしきい値を超えるすべてのノードに同じことを適用できます。
Python
resp = client.cat.allocation(v=True,s="disk.avail",h="node,disk.percent,disk.avail,disk.total,disk.used,disk.indices,shards",)print(resp)
Ruby
response = client.cat.allocation(v: true,s: 'disk.avail',h: 'node,disk.percent,disk.avail,disk.total,disk.used,disk.indices,shards')puts response
Js
const response = await client.cat.allocation({v: "true",s: "disk.avail",h: "node,disk.percent,disk.avail,disk.total,disk.used,disk.indices,shards",});console.log(response);
Console
GET _cat/allocation?v&s=disk.avail&h=node,disk.percent,disk.avail,disk.total,disk.used,disk.indices,shards
Console-Result
node disk.percent disk.avail disk.total disk.used disk.indices shardsinstance-0000000000 91 4.6gb 35gb 31.1gb 29.9gb 111
- 3. 高水位の設定は、ディスク使用量が90%未満に下がる必要があることを示しています。これを達成するためには、2つのことが可能です:
- クラスターに追加のデータノードを追加する(これには、クラスター内に1つ以上のシャードが必要です)、または
- 現在のノードのディスクスペースを約20%拡張して、このノードが70%に下がるようにします。これにより、このノードがすぐにスペース不足にならないための十分なスペースが確保されます。
- 4. 追加のデータノードを追加する場合、クラスターはすぐには回復しません。新しいノードにいくつかのシャードを移動するのに時間がかかる場合があります。進捗状況はここで確認できます:
Python
resp = client.cat.shards(v=True,h="state,node",s="state",)print(resp)
Ruby
response = client.cat.shards(v: true,h: 'state,node',s: 'state')puts response
Js
const response = await client.cat.shards({v: "true",h: "state,node",s: "state",});console.log(response);
Console
GET /_cat/shards?v&h=state,node&s=state
応答でシャードの状態がRELOCATINGの場合、シャードがまだ移動中であることを意味します。すべてのシャードがSTARTEDに変わるまで、またはヘルスディスクインジケーターがgreenに変わるまで待ってください。
