ランキング学習
この機能はバージョン8.12.0で導入され、特定のサブスクリプションレベルでのみ利用可能です。詳細については、https://www.elastic.co/subscriptionsを参照してください。
ランキング学習(LTR)は、トレーニングされた機械学習(ML)モデルを使用して、検索エンジンのランキング関数を構築します。通常、このモデルは第1段階の取得アルゴリズムによって返される検索結果の関連性を向上させるための第2段階の再ランキングとして使用されます。LTR関数は、文書のリストと検索コンテキストを受け取り、ランキングされた文書を出力します:
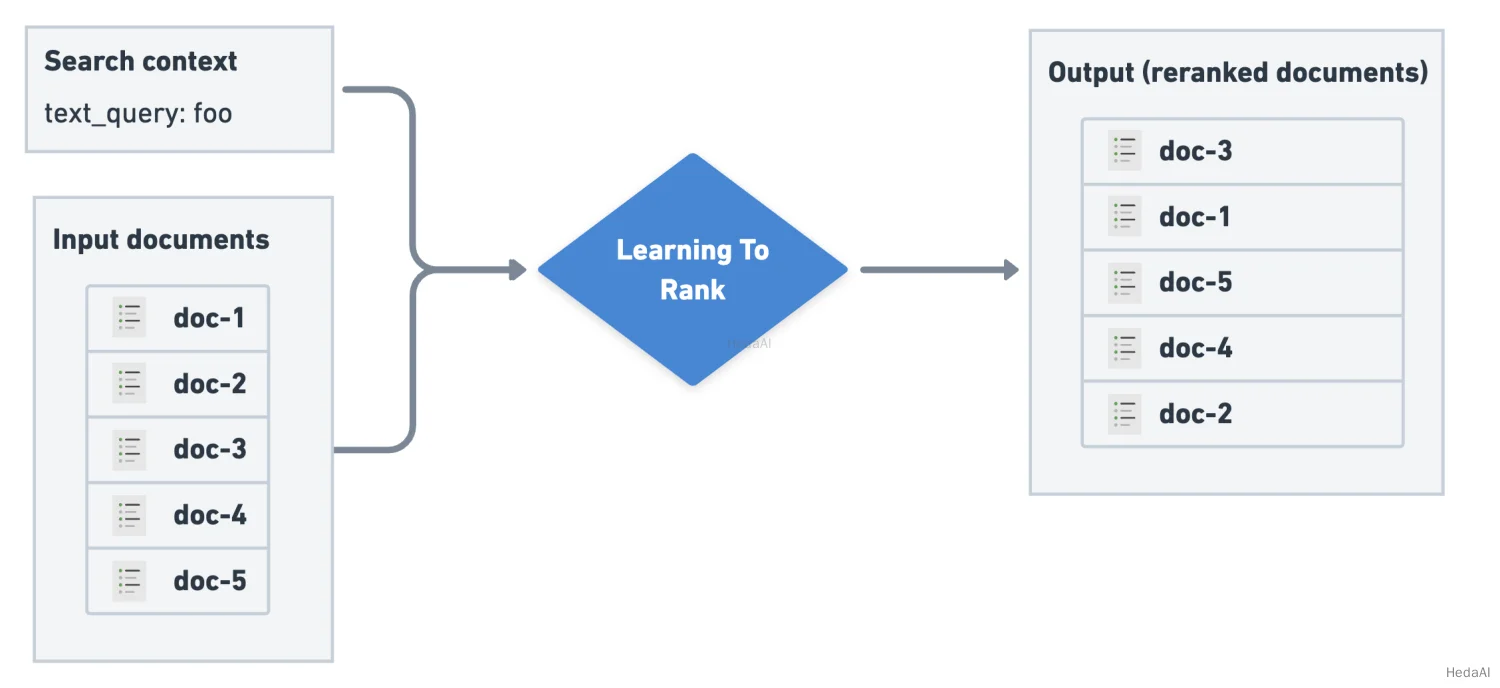
図8. ランキング学習の概要
検索コンテキスト
LTR関数は、ソートする文書のリストに加えて、検索コンテキストも必要です。通常、この検索コンテキストには、ユーザーが提供した検索用語(上記の例ではtext_query)が少なくとも含まれます。検索コンテキストは、ランキングモードで使用される追加情報を提供することもできます。これには、検索を行っているユーザーに関する情報(人口統計データ、地理的位置、年齢など)、クエリに関する情報(クエリの長さなど)、またはクエリの文脈における文書に関する情報(タイトルフィールドのスコアなど)が含まれる可能性があります。
判断リスト
LTRモデルは通常、関連性グレードを持つクエリと文書のセットである判断リストでトレーニングされます。判断リストは人間または機械によって生成されることがあり、行動分析から一般的に収集され、人間のモデレーションが行われることが多いです。判断リストは、特定の検索クエリに対する結果の理想的な順序を決定します。LTRの目標は、新しいクエリと文書に対して判断リストのランキングにできるだけ近づけることです。
判断リストは、モデルをトレーニングするための主な入力です。これは、クエリと文書のペアを含むデータセットであり、それぞれの関連性ラベルが付いています。関連性の判断は通常、バイナリ(関連/非関連)または0(完全に非関連)から4(非常に関連)までのグレードのようなより詳細なラベルのいずれかです。以下の例では、グレード付きの関連性判断を使用しています。
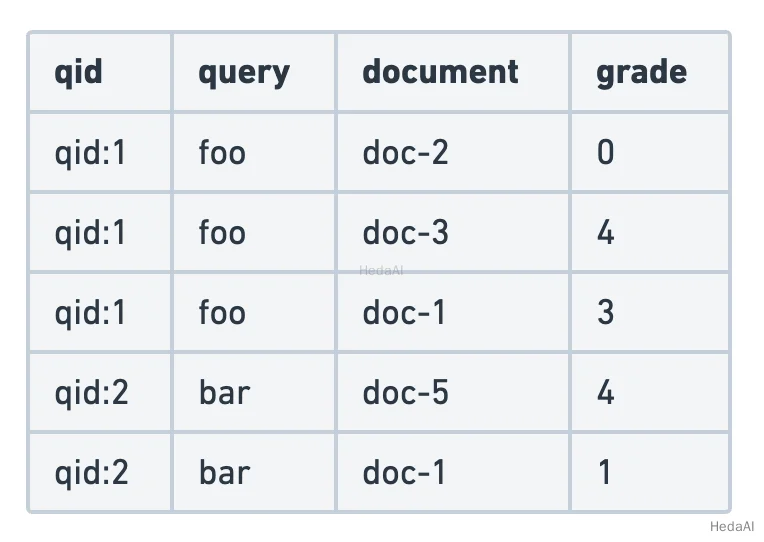
図9. 判断リストの例
判断リストに関する注意事項
判断リストは人間によって手動で作成できますが、クリックやコンバージョンなどのユーザーエンゲージメントデータを活用して判断リストを自動的に構築するための技術も利用可能です。
判断リストの量と質は、LTRモデルの全体的なパフォーマンスに大きく影響します。判断リストを構築する際には、以下の点を非常に注意深く考慮する必要があります:
- ほとんどの検索エンジンは、異なるクエリタイプを使用して検索できます。たとえば、映画検索エンジンでは、ユーザーはタイトルだけでなく、俳優や監督でも検索します。判断リスト内の各クエリタイプの例の数をバランスよく保つことが重要です。これにより、過剰適合を防ぎ、モデルがすべてのクエリタイプにわたって効果的に一般化できるようになります。
- ユーザーはしばしば、否定的な例よりも肯定的な例を多く提供します。肯定的な例と否定的な例の数をバランスさせることで、モデルが関連性のあるコンテンツと関連性のないコンテンツをより正確に区別できるようになります。
特徴抽出
クエリと文書のペアだけでは、LTRに使用されるMLモデルをトレーニングするための十分な情報を提供しません。判断リストの関連性スコアは、いくつかの特性または特徴に依存します。これらの特徴は、さまざまなコンポーネントが文書の関連性を決定する方法を特定するために抽出する必要があります。判断リストと抽出された特徴がLTRモデルのトレーニングデータセットを構成します。
これらの特徴は、次の3つの主要なカテゴリのいずれかに分類されます:
- 文書特徴:これらの特徴は、文書の特性から直接導出されます。例:eコマースストアの製品価格。
- クエリ特徴:これらの特徴は、ユーザーが提出したクエリから直接計算されます。例:クエリ内の単語数。
- クエリ-文書特徴:クエリの文脈における文書に関する情報を提供するために使用される特徴。例:
titleフィールドのBM25スコア。
トレーニング用のデータセットを準備するために、特徴が判断リストに追加されます:
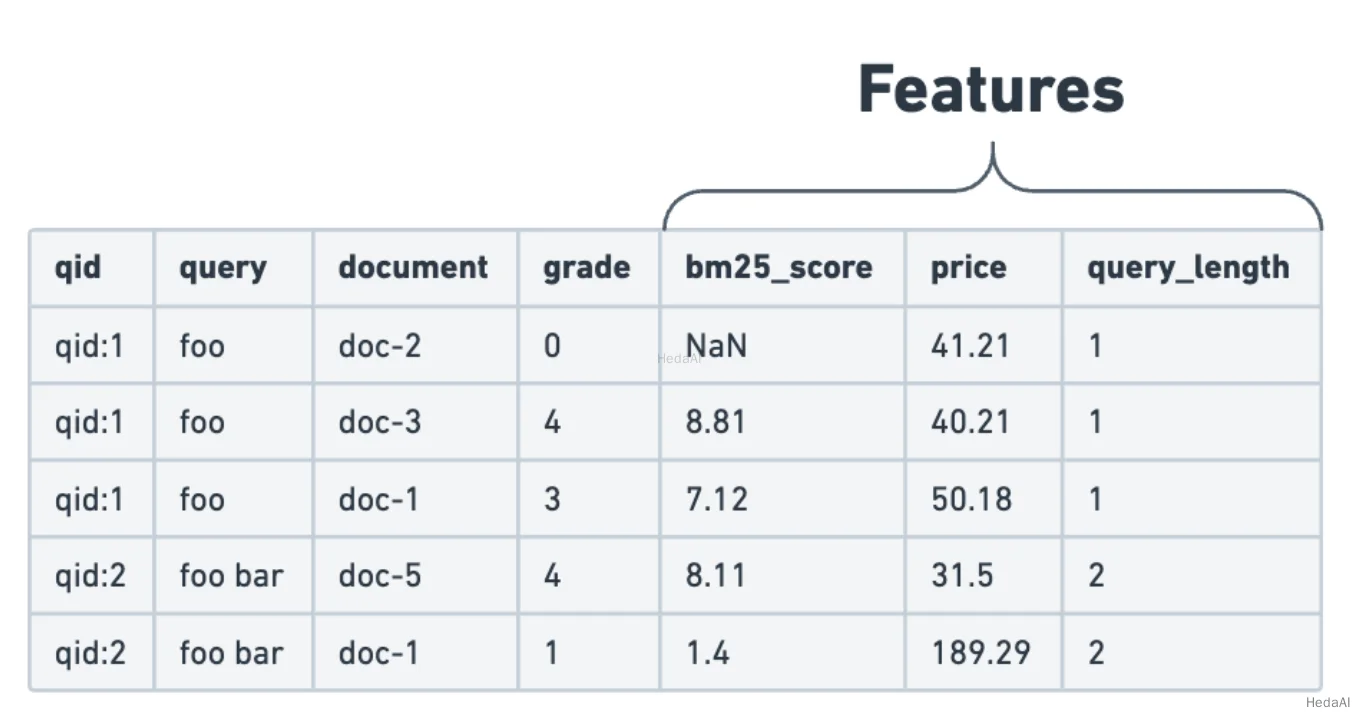
図10. 特徴付き判断リスト
これをElasticsearchで行うには、トレーニングデータセットを構築する際やクエリ時の推論中に特徴を抽出するためにテンプレート化されたクエリを使用します。以下は、テンプレート化されたクエリの例です:
Js
[{"query_extractor": {"feature_name": "title_bm25","query": { "match": { "title": "{{query}}" } }}}]
モデル
LTRの中心はもちろんMLモデルです。モデルは、上記で説明したトレーニングデータと目的を組み合わせてトレーニングされます。LTRの場合、目的は、判断リストに対して最適な方法で結果文書をランク付けすることです。これは、nDCG#Discountedcumulative_gain)や[MAP](https://en.wikipedia.org/wiki/Evaluation_measures(information_retrieval)#Mean_average_precision)などのランキングメトリックに基づいています。モデルは、トレーニングデータからの特徴と関連性ラベルのみに依存します。
LTRの分野は急速に進化しており、多くのアプローチやモデルタイプが試されています。実際、ElasticsearchはLTR推論のために特に勾配ブースト決定木(GBDT)モデルに依存しています。
Elasticsearchはモデル推論をサポートしていますが、トレーニングプロセス自体はElasticsearchの外部で行う必要があり、GBDTモデルを使用します。今日使用されている最も人気のあるLTRモデルの中で、LambdaMARTは、低い推論遅延で強力なランキングパフォーマンスを提供します。これはGBDTモデルに依存しているため、ElasticsearchのLTRに最適です。
XGBoostは、実装を提供するよく知られたライブラリであり、LTRの人気のある選択肢となっています。私たちは、トレーニングされたXBGRankerモデルをElasticsearchのLTRモデルとして統合するためのヘルパーをelandで提供しています。
トレーニングについての詳細は、LTRモデルのトレーニングとデプロイを参照するか、elasticsearch-labsリポジトリで利用可能なインタラクティブLTRノートブックをチェックしてください。
ElasticスタックにおけるLTR
このガイドの次のページでは、次のことを学びます:
