ディスク不足のマスターノードの修正
Elasticsearchは、クラスターを調整するためにマスターノードを使用しています。マスターノードまたはマスターノードの候補がディスクスペース不足の場合、機能するために十分なディスクスペースがあることを確認する必要があります。ヘルスAPIがマスターノードがディスク不足であると報告した場合、マスターノードのディスク容量を増やす必要があります。
- 1. Elastic Cloudコンソールにログインします。
- 2. Elasticsearchサービスパネルで、デプロイメント名に対応する
Manage deployment列の下にあるギアをクリックします。 - 3.
Actions > Edit deploymentに移動し、次にMaster instancesセクションに移動します: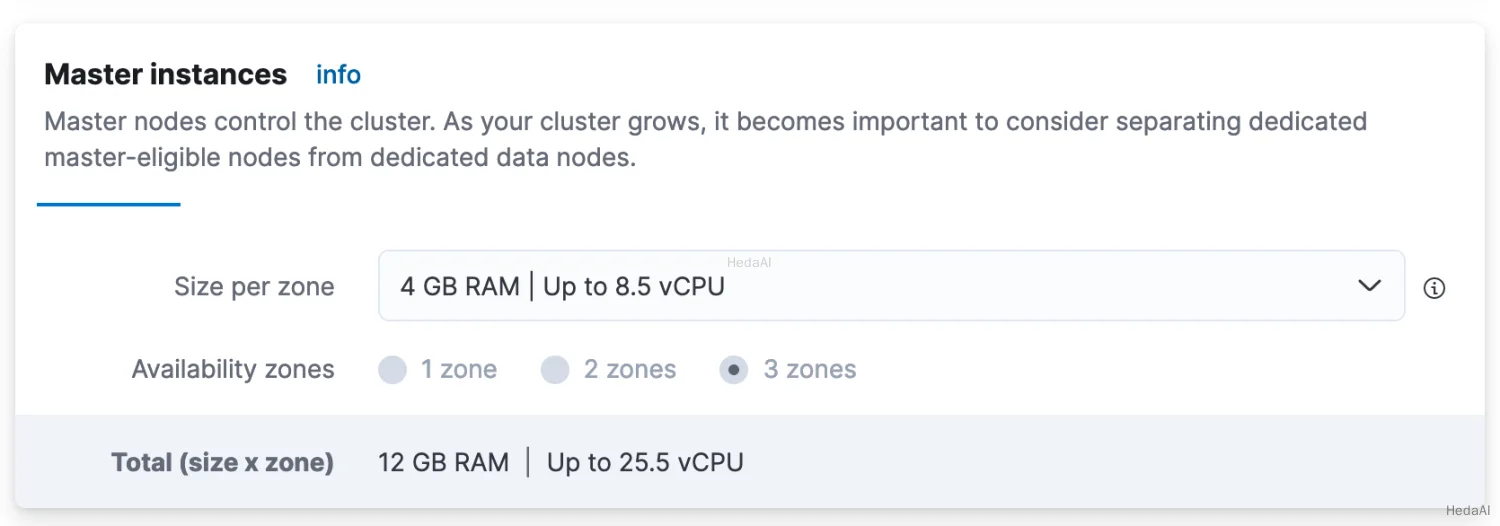
- 4. ドロップダウンメニューから事前選択された容量構成よりも大きいものを選択し、
saveをクリックします。プランが適用されるのを待ち、問題が解決されるはずです。
マスターノードのディスク容量を増やすには、すべてのマスターノードをより高いディスク容量のマスターノードに置き換える必要があります。
- 1. 最初に、どれだけのディスクスペースが必要かを示すディスク閾値を取得します。関連する閾値は高水位線であり、次のコマンドで取得できます:
Python
resp = client.cluster.get_settings(include_defaults=True,filter_path="*.cluster.routing.allocation.disk.watermark.high*",)print(resp)
Ruby
response = client.cluster.get_settings(include_defaults: true,filter_path: '*.cluster.routing.allocation.disk.watermark.high*')puts response
Js
const response = await client.cluster.getSettings({include_defaults: "true",filter_path: "*.cluster.routing.allocation.disk.watermark.high*",});console.log(response);
コンソール
GET _cluster/settings?include_defaults&filter_path=*.cluster.routing.allocation.disk.watermark.high*
コンソール-結果
{"defaults": {"cluster": {"routing": {"allocation": {"disk": {"watermark": {"high": "90%","high.max_headroom": "150GB"}}}}}}
上記は、ディスク不足を解決するためには、ディスク使用量を90%未満にするか、150GB以上の空き容量を確保する必要があることを意味します。この閾値の動作については、こちらを参照してください。
- 2. 次のステップは、現在のディスク使用量を確認することです。これにより、どれだけの追加スペースが必要かを計算できます。以下の例では、可読性のためにマスターノードのみを示します:
Python
resp = client.cat.nodes(v=True,h="name,master,node.role,disk.used_percent,disk.used,disk.avail,disk.total",)print(resp)
Ruby
response = client.cat.nodes(v: true,h: 'name,master,node.role,disk.used_percent,disk.used,disk.avail,disk.total')puts response
Js
const response = await client.cat.nodes({v: "true",h: "name,master,node.role,disk.used_percent,disk.used,disk.avail,disk.total",});console.log(response);
コンソール
GET /_cat/nodes?v&h=name,master,node.role,disk.used_percent,disk.used,disk.avail,disk.total
コンソール-結果
name master node.role disk.used_percent disk.used disk.avail disk.totalinstance-0000000000 * m 85.31 3.4gb 500mb 4gbinstance-0000000001 * m 50.02 2.1gb 1.9gb 4gbinstance-0000000002 * m 50.02 1.9gb 2.1gb 4gb
- 3. 望ましい状況は、ディスク使用量を関連する閾値、私たちの例では90%未満にすることです。すぐに閾値を超えないように、いくつかの余裕を持たせることを検討してください。複数のマスターノードがある場合、すべてのマスターノードがこの容量を持つことを確認する必要があります。新しいノードが準備できていると仮定して、各マスターノードに対して次の3つのステップを実行します。
- 4. マスターノードの1つを停止します。
- 5. 新しいマスターノードの1つを起動し、クラスターに参加するのを待ちます。これを確認するには:
Python
resp = client.cat.nodes(v=True,h="name,master,node.role,disk.used_percent,disk.used,disk.avail,disk.total",)print(resp)
Ruby
response = client.cat.nodes(v: true,h: 'name,master,node.role,disk.used_percent,disk.used,disk.avail,disk.total')puts response
Js
const response = await client.cat.nodes({v: "true",h: "name,master,node.role,disk.used_percent,disk.used,disk.avail,disk.total",});console.log(response);
コンソール
GET /_cat/nodes?v&h=name,master,node.role,disk.used_percent,disk.used,disk.avail,disk.total
- 6. クラスターが初期のマスターノードの数を持っていることを確認した後、すべての初期マスターノードが置き換えられるまで次のノードに進みます。
