ES|QL コマンド
ソースコマンド
ES|QL ソースコマンドは、通常 Elasticsearch からのデータを持つテーブルを生成します。ES|QL クエリはソースコマンドで始まる必要があります。

ES|QL は以下のソースコマンドをサポートしています:
処理コマンド
ES|QL 処理コマンドは、行や列を追加、削除、または変更することによって入力テーブルを変更します。

ES|QL は以下の処理コマンドをサポートしています:
DISSECTDROPENRICHEVALGROKKEEPLIMIT- [プレビュー] この機能は技術プレビュー中であり、将来のリリースで変更または削除される可能性があります。Elastic は問題を修正するために取り組みますが、技術プレビューの機能は公式 GA 機能のサポート SLA の対象外です。
MV_EXPAND RENAMESORTSTATS ... BYWHERE
FROM
構文
Esql
FROM index_pattern [METADATA fields]
パラメータ
index_pattern- インデックス、データストリーム、またはエイリアスのリスト。ワイルドカードと日付計算をサポートします。
fields- 取得する メタデータフィールド のカンマ区切りリスト。
説明
FROM ソースコマンドは、データストリーム、インデックス、またはエイリアスからのデータを持つテーブルを返します。結果のテーブルの各行はドキュメントを表し、各列はフィールドに対応し、そのフィールドの名前でアクセスできます。
デフォルトでは、明示的な LIMIT なしの ES|QL クエリは、暗黙の制限 1000 を使用します。これは FROM にも適用されます。FROM コマンドは LIMIT なしで:
Esql
FROM employees
は次のように実行されます:
Esql
FROM employees| LIMIT 1000
例
Esql
FROM employees
日付計算 を使用して、インデックス、エイリアス、データストリームを参照できます。これは、たとえば今日のインデックスにアクセスするための時系列データに便利です:
Esql
FROM <logs-{now/d}>
カンマ区切りリストまたはワイルドカードを使用して、複数のデータストリーム、インデックス、またはエイリアスをクエリする:
Esql
FROM employees-00001,other-employees-*
<remote_cluster_name>:<target> 形式を使用して、リモートクラスター上のデータストリームとインデックスをクエリする:
Esql
FROM cluster_one:employees-00001,cluster_two:other-employees-*
オプションの METADATA ディレクティブを使用して、メタデータフィールド を有効にします:
Esql
FROM employees METADATA _id
特殊文字を含むインデックス名をエスケープするには、二重引用符 (") または三重の二重引用符 (""") を使用します:
Esql
FROM "this=that", """this[that"""
ROW
構文
Esql
ROW column1 = value1[, ..., columnN = valueN]
パラメータ
columnX- 列名。重複する列名がある場合、右側の重複のみが列を作成します。
valueX- 列の値。リテラル、式、または 関数 である可能性があります。
説明
ROW ソースコマンドは、指定した値を持つ1つ以上の列を持つ行を生成します。これはテストに便利です。
例
Esql
ROW a = 1, b = "two", c = null
| a:integer | b:keyword | c:null |
|---|---|---|
| 1 | “two” | null |
角括弧を使用して、複数値列を作成します:
Esql
ROW a = [2, 1]
ROW は 関数 の使用をサポートしています:
Esql
ROW a = ROUND(1.23, 0)
SHOW
構文
Esql
SHOW item
パラメータ
itemINFOのみを指定できます。
説明
SHOW ソースコマンドは、デプロイメントとその機能に関する情報を返します:
SHOW INFOを使用して、デプロイメントのバージョン、ビルド日、ハッシュを返します。
例
Esql
SHOW INFO
| version | date | hash |
|---|---|---|
| 8.13.0 | 2024-02-23T10:04:18.123117961Z | 04ba8c8db2507501c88f215e475de7b0798cb3b3 |
DISSECT
構文
Esql
DISSECT input "pattern" [APPEND_SEPARATOR="<separator>"]
パラメータ
input- 構造化したい文字列を含む列。列に複数の値がある場合、
DISSECTは各値を処理します。 pattern- ディセクトパターン。フィールド名が既存の列と衝突する場合、既存の列は削除されます。フィールド名が複数回使用される場合、右側の重複のみが列を作成します。
<separator>- 追加された値の間の区切り文字として使用される文字列、追加修飾子 を使用する場合。
説明
DISSECT は、文字列から構造化データを抽出することを可能にします。DISSECT は、区切り文字ベースのパターンに対して文字列を一致させ、指定されたキーを列として抽出します。
ディセクトパターンの構文については、DISSECT を使用してデータを処理するを参照してください。
例
次の例は、タイムスタンプ、テキスト、および IP アドレスを含む文字列を解析します:
Esql
ROW a = "2023-01-23T12:15:00.000Z - some text - 127.0.0.1"| DISSECT a "%{date} - %{msg} - %{ip}"| KEEP date, msg, ip
| date:keyword | msg:keyword | ip:keyword |
|---|---|---|
| 2023-01-23T12:15:00.000Z | some text | 127.0.0.1 |
デフォルトでは、DISSECT はキーワード文字列列を出力します。他の型に変換するには、型変換関数を使用します:
Esql
ROW a = "2023-01-23T12:15:00.000Z - some text - 127.0.0.1"| DISSECT a "%{date} - %{msg} - %{ip}"| KEEP date, msg, ip| EVAL date = TO_DATETIME(date)
| msg:keyword | ip:keyword | date:date |
|---|---|---|
| some text | 127.0.0.1 | 2023-01-23T12:15:00.000Z |
DROP
構文
Esql
DROP columns
パラメータ
columns- 削除する列のカンマ区切りリスト。ワイルドカードをサポートします。
説明
DROP 処理コマンドは、1つ以上の列を削除します。
例
Esql
FROM employees| DROP height
各列を名前で指定する代わりに、ワイルドカードを使用して、パターンに一致するすべての列を削除できます:
Esql
FROM employees| DROP height*
ENRICH
構文
Esql
ENRICH policy [ON match_field] [WITH [new_name1 = ]field1, [new_name2 = ]field2, ...]
パラメータ
policy- エンリッチポリシーの名前。最初に 作成 し、実行 する必要があります。
mode- クロスクラスター ES|QL におけるエンリッチコマンドのモード。クラスター間のエンリッチ を参照してください。
match_field- 一致フィールド。
ENRICHはその値を使用してエンリッチインデックス内のレコードを検索します。指定しない場合、一致は エンリッチポリシー で定義されたmatch_fieldと同じ名前の列で行われます。 fieldX- 結果に新しい列として追加されるエンリッチインデックスからのエンリッチフィールド。エンリッチフィールドと同じ名前の列がすでに存在する場合、既存の列は新しい列に置き換えられます。指定しない場合、ポリシーで定義された各エンリッチフィールドが追加されます。エンリッチフィールドと同じ名前の列は、エンリッチフィールドがリネームされない限り削除されます。
new_nameX- 各エンリッチフィールドに追加される列の名前を変更できます。デフォルトはエンリッチフィールド名です。列が新しい名前と同じ名前を持つ場合、それは破棄されます。名前(新しいまたは元の)が複数回発生する場合、右側の重複のみが新しい列を作成します。
説明
ENRICH は、エンリッチポリシーを使用して既存のインデックスからデータを新しい列として追加することを可能にします。ポリシーの設定については、データエンリッチメント を参照してください。
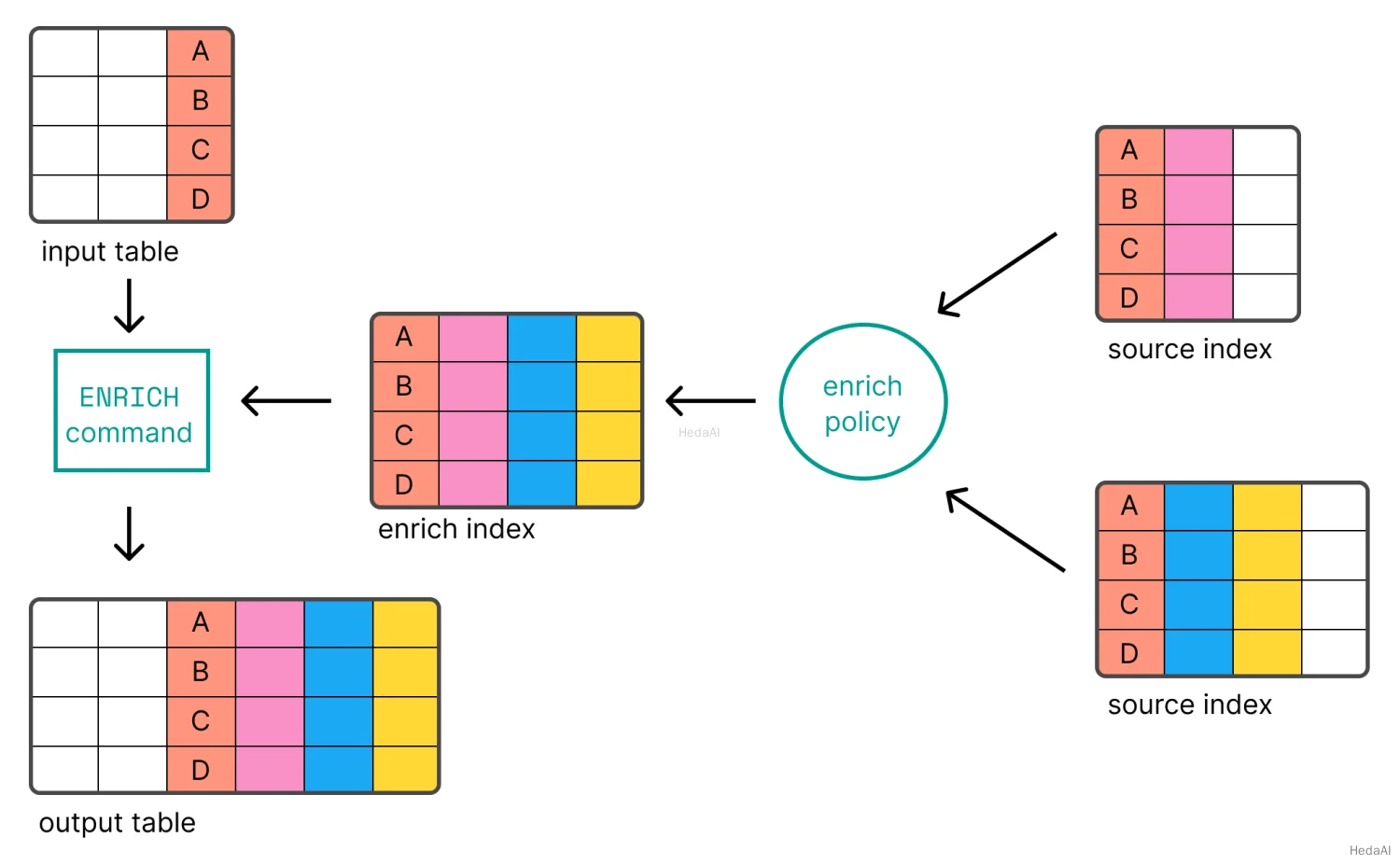
ENRICH を使用する前に、エンリッチポリシーを作成して実行する必要があります。
例
次の例は、languages_policy エンリッチポリシーを使用して、ポリシーで定義された各エンリッチフィールドの新しい列を追加します。一致は エンリッチポリシー で定義された match_field を使用して行われ、入力テーブルには同じ名前の列が必要です(この例では language_code)。ENRICH は、一致フィールドの値に基づいて エンリッチインデックス 内のレコードを検索します。
Esql
ROW language_code = "1"| ENRICH languages_policy
| language_code:keyword | language_name:keyword |
|---|---|
| 1 | 英語 |
ポリシーで定義された match_field と異なる名前の列を一致フィールドとして使用するには、ON <column-name> を使用します:
Esql
ROW a = "1"| ENRICH languages_policy ON a
| a:keyword | language_name:keyword |
|---|---|
| 1 | 英語 |
デフォルトでは、ポリシーで定義された各エンリッチフィールドが列として追加されます。追加されるエンリッチフィールドを明示的に選択するには、WITH <field1>, <field2>, ... を使用します:
Esql
ROW a = "1"| ENRICH languages_policy ON a WITH language_name
| a:keyword | language_name:keyword |
|---|---|
| 1 | 英語 |
WITH new_name=<field1> を使用して追加される列の名前を変更できます:
Esql
ROW a = "1"| ENRICH languages_policy ON a WITH name = language_name
| a:keyword | name:keyword |
|---|---|
| 1 | 英語 |
名前の衝突がある場合、新しく作成された列が既存の列を上書きします。
EVAL
構文
Esql
EVAL [column1 =] value1[, ..., [columnN =] valueN]
パラメータ
columnX- 列名。同じ名前の列がすでに存在する場合、既存の列は削除されます。同じ列名が複数回使用される場合、右側の重複のみが列を作成します。
valueX- 列の値。リテラル、式、または 関数 である可能性があります。この列の左側で定義された列を使用できます。
説明
EVAL 処理コマンドは、計算された値を持つ新しい列を追加することを可能にします。EVAL は、値を計算するためのさまざまな関数をサポートしています。詳細については、関数 を参照してください。
例
Esql
FROM employees| SORT emp_no| KEEP first_name, last_name, height| EVAL height_feet = height * 3.281, height_cm = height * 100
| first_name:keyword | last_name:keyword | height:double | height_feet:double | height_cm:double |
|---|---|---|---|---|
| Georgi | Facello | 2.03 | 6.66043 | 202.99999999999997 |
| Bezalel | Simmel | 2.08 | 6.82448 | 208.0 |
| Parto | Bamford | 1.83 | 6.004230000000001 | 183.0 |
指定された列がすでに存在する場合、既存の列は削除され、新しい列がテーブルに追加されます:
Esql
FROM employees| SORT emp_no| KEEP first_name, last_name, height| EVAL height = height * 3.281
| first_name:keyword | last_name:keyword | height:double |
|---|---|---|
| Georgi | Facello | 6.66043 |
| Bezalel | Simmel | 6.82448 |
| Parto | Bamford | 6.004230000000001 |
出力列名の指定はオプションです。指定しない場合、新しい列名は式と等しくなります。次のクエリは、height*3.281 という名前の列を追加します:
Esql
FROM employees| SORT emp_no| KEEP first_name, last_name, height| EVAL height * 3.281
| first_name:keyword | last_name:keyword | height:double | height * 3.281:double |
|---|---|---|---|
| Georgi | Facello | 2.03 | 6.66043 |
| Bezalel | Simmel | 2.08 | 6.82448 |
| Parto | Bamford | 1.83 | 6.004230000000001 |
この名前には特殊文字が含まれているため、引用符で囲む必要があります (` ) その後のコマンドで使用する場合:
Esql
FROM employees| EVAL height * 3.281| STATS avg_height_feet = AVG(`height * 3.281`)
| avg_height_feet:double |
|---|
| 5.801464200000001 |
GROK
構文
Esql
GROK input "pattern"
パラメータ
input- 構造化したい文字列を含む列。列に複数の値がある場合、
GROKは各値を処理します。 pattern- グロックパターン。フィールド名が既存の列と衝突する場合、既存の列は破棄されます。フィールド名が複数回使用される場合、各フィールド名の出現ごとに1つの値を持つ多値列が作成されます。
説明
GROK は、文字列から構造化データを抽出することを可能にします。GROK は、正規表現に基づいてパターンに対して文字列を一致させ、指定されたパターンを列として抽出します。
グロックパターンの構文については、GROK を使用してデータを処理するを参照してください。
例
次の例は、タイムスタンプ、IP アドレス、メールアドレス、および数値を含む文字列を解析します:
Esql
ROW a = "2023-01-23T12:15:00.000Z 127.0.0.1 [email protected] 42"| GROK a "%{TIMESTAMP_ISO8601:date} %{IP:ip} %{EMAILADDRESS:email} %{NUMBER:num}"| KEEP date, ip, email, num
| date:keyword | ip:keyword | email:keyword | num:keyword |
|---|---|---|---|
| 2023-01-23T12:15:00.000Z | 127.0.0.1 | [email protected] | 42 |
デフォルトでは、GROK はキーワード文字列列を出力します。int および float 型は、パターンの意味に :type を追加することで変換できます。たとえば {NUMBER:num:int}:
Esql
ROW a = "2023-01-23T12:15:00.000Z 127.0.0.1 [email protected] 42"| GROK a "%{TIMESTAMP_ISO8601:date} %{IP:ip} %{EMAILADDRESS:email} %{NUMBER:num:int}"| KEEP date, ip, email, num
| date:keyword | ip:keyword | email:keyword | num:integer |
|---|---|---|---|
| 2023-01-23T12:15:00.000Z | 127.0.0.1 | [email protected] | 42 |
他の型変換には、型変換関数を使用します:
Esql
ROW a = "2023-01-23T12:15:00.000Z 127.0.0.1 [email protected] 42"| GROK a "%{TIMESTAMP_ISO8601:date} %{IP:ip} %{EMAILADDRESS:email} %{NUMBER:num:int}"| KEEP date, ip, email, num| EVAL date = TO_DATETIME(date)
| ip:keyword | email:keyword | num:integer | date:date |
|---|---|---|---|
| 127.0.0.1 | [email protected] | 42 | 2023-01-23T12:15:00.000Z |
フィールド名が複数回使用される場合、GROK は多値列を作成します:
Esql
FROM addresses| KEEP city.name, zip_code| GROK zip_code "%{WORD:zip_parts} %{WORD:zip_parts}"
| city.name:keyword | zip_code:keyword | zip_parts:keyword |
|---|---|---|
| アムステルダム | 1016 ED | [“1016”, “ED”] |
| サンフランシスコ | CA 94108 | [“CA”, “94108”] |
| 東京 | 100-7014 | null |
KEEP
構文
Esql
KEEP columns
パラメータ
columns- 保持する列のカンマ区切りリスト。ワイルドカードをサポートします。既存の列が複数の指定されたワイルドカードまたは列名に一致する場合の動作については、以下を参照してください。
説明
KEEP 処理コマンドは、返される列とその順序を指定することを可能にします。
フィールド名が複数の式に一致する場合、優先順位ルールが適用されます。フィールドは出現順に追加されます。1つのフィールドが複数の式に一致する場合、次の優先順位ルールが適用されます(最高から最低の優先順位まで):
- 1. 完全なフィールド名(ワイルドカードなし)
- 2. 部分的なワイルドカード式(例:
fieldNam*) - 3. ワイルドカードのみ (
*)
フィールドが同じ優先順位の2つの式に一致する場合、右側の式が勝ちます。
これらの優先順位ルールの例については、例を参照してください。
例
指定された順序で列が返されます:
Esql
FROM employees| KEEP emp_no, first_name, last_name, height
| emp_no:integer | first_name:keyword | last_name:keyword | height:double |
|---|---|---|---|
| 10001 | Georgi | Facello | 2.03 |
| 10002 | Bezalel | Simmel | 2.08 |
| 10003 | Parto | Bamford | 1.83 |
| 10004 | Chirstian | Koblick | 1.78 |
| 10005 | Kyoichi | Maliniak | 2.05 |
各列を名前で指定する代わりに、ワイルドカードを使用して、パターンに一致するすべての列を返すことができます:
Esql
FROM employees| KEEP h*
| height:double | height.float:double | height.half_float:double | height.scaled_float:double | hire_date:date |
|---|---|---|---|---|
アスタリスクワイルドカード (*) は、他の引数に一致しないすべての列を表します。
このクエリは、h で始まる名前のすべての列を最初に返し、その後に他のすべての列を返します:
Esql
FROM employees| KEEP h*, *
| height:double | height.float:double | height.half_float:double | height.scaled_float:double | hire_date:date | avg_worked_seconds:long | birth_date:date | emp_no:integer | first_name:keyword | gender:keyword | is_rehired:boolean | job_positions:keyword | languages:integer | languages.byte:integer | languages.long:long | languages.short:integer | last_name:keyword | salary:integer | salary_change:double | salary_change.int:integer | salary_change.keyword:keyword | salary_change.long:long | still_hired:boolean |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
次の例は、フィールド名が複数の式に一致する場合の優先順位ルールがどのように機能するかを示しています。
完全なフィールド名は、ワイルドカード式よりも優先されます:
Esql
FROM employees| KEEP first_name, last_name, first_name*
| first_name:keyword | last_name:keyword |
|---|---|
ワイルドカード式は同じ優先順位を持ちますが、最後のものが勝ちます(具体性が低くても):
Esql
FROM employees| KEEP first_name*, last_name, first_na*
| last_name:keyword | first_name:keyword |
|---|---|
単純なワイルドカード式 * は最低の優先順位を持ちます。出力順序は他の引数によって決まります:
Esql
FROM employees| KEEP *, first_name
| avg_worked_seconds:long | birth_date:date | emp_no:integer | gender:keyword | height:double | height.float:double | height.half_float:double | height.scaled_float:double | hire_date:date | is_rehired:boolean | job_positions:keyword | languages:integer | languages.byte:integer | languages.long:long | languages.short:integer | last_name:keyword | salary:integer | salary_change:double | salary_change.int:integer | salary_change.keyword:keyword | salary_change.long:long | still_hired:boolean | first_name:keyword |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
LIMIT
構文
Esql
LIMIT max_number_of_rows
パラメータ
max_number_of_rows- 返される最大行数。
説明
LIMIT 処理コマンドは、返される行数を制限することを可能にします。クエリは、LIMIT コマンドの値に関係なく、10,000 行を超えて返されません。
この制限は、クエリによって取得される行数にのみ適用されます。クエリと集計は、完全なデータセットで実行されます。
この制限を克服するには:
- クエリを修正して、関連するデータのみを返すことによって、結果セットのサイズを減らします。
WHEREを使用して、データの小さなサブセットを選択します。 - クエリ後の処理をクエリ自体に移します。ES|QL
STATS ... BYコマンドを使用して、クエリ内でデータを集計できます。
デフォルトおよび最大制限は、これらの動的クラスター設定を使用して変更できます:
esql.query.result_truncation_default_sizeesql.query.result_truncation_max_size
例
Esql
FROM employees| SORT emp_no ASC| LIMIT 5
MV_EXPAND
この機能は技術プレビュー中であり、将来のリリースで変更または削除される可能性があります。Elastic は問題を修正するために取り組みますが、技術プレビューの機能は公式 GA 機能のサポート SLA の対象外です。
構文
Esql
MV_EXPAND column
パラメータ
column- 拡張する多値列。
説明
MV_EXPAND 処理コマンドは、多値列を値ごとに1行に展開し、他の列を複製します。
例
Esql
ROW a=[1,2,3], b="b", j=["a","b"]| MV_EXPAND a
| a:integer | b:keyword | j:keyword |
|---|---|---|
| 1 | b | [“a”, “b”] |
| 2 | b | [“a”, “b”] |
| 3 | b | [“a”, “b”] |
RENAME
構文
Esql
RENAME old_name1 AS new_name1[, ..., old_nameN AS new_nameN]
パラメータ
old_nameX- リネームしたい列の名前。
new_nameX- 列の新しい名前。既存の列名と衝突する場合、既存の列は削除されます。複数の列が同じ名前にリネームされる場合、右側の同じ新しい名前の列以外はすべて削除されます。
説明
RENAME 処理コマンドは、1つ以上の列の名前を変更します。新しい名前の列がすでに存在する場合、それは新しい列に置き換えられます。
例
Esql
FROM employees| KEEP first_name, last_name, still_hired| RENAME still_hired AS employed
複数の列を単一の RENAME コマンドでリネームできます:
Esql
FROM employees| KEEP first_name, last_name| RENAME first_name AS fn, last_name AS ln
SORT
構文
Esql
SORT column1 [ASC/DESC][NULLS FIRST/NULLS LAST][, ..., columnN [ASC/DESC][NULLS FIRST/NULLS LAST]]
パラメータ
columnX- ソートする列。
説明
SORT 処理コマンドは、1つ以上の列に基づいてテーブルをソートします。
デフォルトのソート順は昇順です。明示的なソート順を指定するには、ASC または DESC を使用します。
同じソートキーを持つ2つの行は等しいと見なされます。追加のソート式を提供して、タイブレーカーとして機能させることができます。
多値列のソートでは、昇順でソートする際には最小値が使用され、降順でソートする際には最大値が使用されます。
デフォルトでは、null の値は他の値よりも大きいと見なされます。昇順のソートでは、null の値が最後にソートされ、降順のソートでは、null の値が最初にソートされます。NULLS FIRST または NULLS LAST を提供することでこれを変更できます。
例
Esql
FROM employees| KEEP first_name, last_name, height| SORT height
ASC を使用して昇順で明示的にソートする:
Esql
FROM employees| KEEP first_name, last_name, height| SORT height DESC
タイブレーカーとして機能する追加のソート式を提供する:
Esql
FROM employees| KEEP first_name, last_name, height| SORT height DESC, first_name ASC
NULLS FIRST を使用して null の値を最初にソートする:
Esql
FROM employees| KEEP first_name, last_name, height| SORT first_name ASC NULLS FIRST
STATS … BY
STATS ... BY 処理コマンドは、共通の値に基づいて行をグループ化し、グループ化された行に対して1つ以上の集約値を計算します。
構文
Esql
STATS [column1 =] expression1[, ..., [columnN =] expressionN][BY grouping_expression1[, ..., grouping_expressionN]]
パラメータ
columnX- 集約値が返される名前。省略した場合、名前は対応する式 (
expressionX) と等しくなります。同じ名前の複数の列がある場合、この名前を持つ右端の列以外はすべて無視されます。 expressionX- 集約値を計算する式。
grouping_expressionX- グループ化する値を出力する式。その名前が計算された列の1つと一致する場合、その列は無視されます。
個々の null 値は集約を計算する際にスキップされます。
説明
STATS ... BY 処理コマンドは、共通の値に基づいて行をグループ化し、グループ化された行に対して1つ以上の集約値を計算します。BY が省略された場合、出力テーブルには全データセットに対して適用された集約を持つ1行が含まれます。
次の 集約関数 がサポートされています:
AVGCOUNTCOUNT_DISTINCTMAXMEDIANMEDIAN_ABSOLUTE_DEVIATIONMINPERCENTILE- [プレビュー] この機能は技術プレビュー中であり、将来のリリースで変更または削除される可能性があります。Elastic は問題を修正するために取り組みますが、技術プレビューの機能は公式 GA 機能のサポート SLA の対象外です。
ST_CENTROID_AGG SUMTOPVALUES- [プレビュー] この機能は技術プレビュー中であり、将来のリリースで変更または削除される可能性があります。Elastic は問題を修正するために取り組みますが、技術プレビューの機能は公式 GA 機能のサポート SLA の対象外です。
WEIGHTED_AVG
次の グループ化関数 がサポートされています:
グループなしの STATS は、グループを追加するよりもはるかに高速です。
単一の式でのグループ化は、現在、多数の式でのグループ化よりもはるかに最適化されています。いくつかのテストでは、単一の keyword 列でのグループ化が2つの keyword 列でのグループ化よりも5倍速いことが確認されています。この2つの列を CONCAT のようなもので結合してからグループ化しようとしないでください - それは速くなりません。
例
別の列の値で統計を計算し、グループ化する:
Esql
FROM employees| STATS count = COUNT(emp_no) BY languages| SORT languages
| count:long | languages:integer |
|---|---|
| 15 | 1 |
| 19 | 2 |
| 17 | 3 |
| 18 | 4 |
| 21 | 5 |
| 10 | null |
BY を省略すると、全データセットに対して適用された集約を持つ1行が返されます:
Esql
FROM employees| STATS avg_lang = AVG(languages)
| avg_lang:double |
|---|
| 3.1222222222222222 |
複数の値を計算することが可能です:
Esql
FROM employees| STATS avg_lang = AVG(languages), max_lang = MAX(languages)
| avg_lang:double | max_lang:integer |
|---|---|
| 3.1222222222222222 | 5 |
複数の値でグループ化することも可能です(長いおよびキーワードファミリーフィールドのみサポート):
Esql
FROM employees| EVAL hired = DATE_FORMAT("yyyy", hire_date)| STATS avg_salary = AVG(salary) BY hired, languages.long| EVAL avg_salary = ROUND(avg_salary)| SORT hired, languages.long
集約関数とグループ化式の両方が他の関数を受け入れます。これは、STATS...BY を多値列で使用するのに便利です。たとえば、平均給与の変化を計算するには、MV_AVG を使用して最初に従業員ごとの複数の値を平均し、その結果を AVG 関数で使用できます:
Esql
FROM employees| STATS avg_salary_change = ROUND(AVG(MV_AVG(salary_change)), 10)
| avg_salary_change:double |
|---|
| 1.3904535865 |
式によるグループ化の例は、従業員を姓の最初の文字でグループ化することです:
Esql
FROM employees| STATS my_count = COUNT() BY LEFT(last_name, 1)| SORT `LEFT(last_name, 1)`
| my_count:long | LEFT(last_name, 1):keyword |
|---|---|
| 2 | A |
| 11 | B |
| 5 | C |
| 5 | D |
| 2 | E |
| 4 | F |
| 4 | G |
| 6 | H |
| 2 | J |
| 3 | K |
| 5 | L |
| 12 | M |
| 4 | N |
| 1 | O |
| 7 | P |
| 5 | R |
| 13 | S |
| 4 | T |
| 2 | W |
| 3 | Z |
出力列名の指定はオプションです。指定しない場合、新しい列名は式と等しくなります。次のクエリは、AVG(salary) という名前の列を返します:
Esql
FROM employees| STATS AVG(salary)
| AVG(salary):double |
|---|
| 48248.55 |
この名前には特殊文字が含まれているため、引用符で囲む必要があります (` ) その後のコマンドで使用する場合:
Esql
FROM employees| STATS AVG(salary)| EVAL avg_salary_rounded = ROUND(`AVG(salary)`)
| AVG(salary):double | avg_salary_rounded:double |
|---|---|
| 48248.55 | 48249.0 |
WHERE
構文
Esql
WHERE expression
パラメータ
expression- ブール式。
説明
WHERE 処理コマンドは、提供された条件が true に評価される入力テーブルのすべての行を含むテーブルを生成します。
例
Esql
FROM employees| KEEP first_name, last_name, still_hired| WHERE still_hired == true
still_hired がブールフィールドである場合、次のように簡略化できます:
Esql
FROM employees| KEEP first_name, last_name, still_hired| WHERE still_hired
特定の時間範囲からデータを取得するために日付数学を使用します。たとえば、最後の1時間のログを取得するには:
Esql
FROM sample_data| WHERE @timestamp > NOW() - 1 hour
WHERE はさまざまな 関数 をサポートしています。たとえば、LENGTH 関数:
Esql
FROM employees| KEEP first_name, last_name, height| WHERE LENGTH(first_name) < 4
すべての関数の完全なリストについては、関数の概要 を参照してください。
NULL 比較には、IS NULL および IS NOT NULL 述語を使用します:
Esql
FROM employees| WHERE birth_date IS NULL| KEEP first_name, last_name| SORT first_name| LIMIT 3
| first_name:keyword | last_name:keyword |
|---|---|
| Basil | Tramer |
| Florian | Syrotiuk |
| Lucien | Rosenbaum |
Esql
FROM employees| WHERE is_rehired IS NOT NULL| STATS COUNT(emp_no)
| COUNT(emp_no):long |
|---|
| 84 |
LIKE を使用して、ワイルドカードを使用して文字列パターンに基づいてデータをフィルタリングします。LIKE は通常、演算子の左側に配置されたフィールドに作用しますが、定数(リテラル)式にも作用できます。演算子の右側はパターンを表します。
次のワイルドカード文字がサポートされています:
*は0文字以上に一致します。?は1文字に一致します。
サポートされる型
| str | pattern | result |
|---|---|---|
| keyword | keyword | boolean |
| text | text | boolean |
Esql
FROM employees| WHERE first_name LIKE "?b*"| KEEP first_name, last_name
| first_name:keyword | last_name:keyword |
|---|---|
| Ebbe | Callaway |
| Eberhardt | Terkki |
RLIKE を使用して、正規表現 を使用して文字列パターンに基づいてデータをフィルタリングします。RLIKE は通常、演算子の左側に配置されたフィールドに作用しますが、定数(リテラル)式にも作用できます。演算子の右側はパターンを表します。
サポートされる型
| str | pattern | result |
|---|---|---|
| keyword | keyword | boolean |
| text | text | boolean |
Esql
FROM employees| WHERE first_name RLIKE ".leja.*"| KEEP first_name, last_name
| first_name:keyword | last_name:keyword |
|---|---|
| Alejandro | McAlpine |
IN 演算子は、フィールドまたは式がリテラル、フィールド、または式のリストの要素と等しいかどうかをテストすることを可能にします:
Esql
ROW a = 1, b = 4, c = 3| WHERE c-a IN (3, b / 2, a)
| a:integer | b:integer | c:integer |
|---|---|---|
| 1 | 4 | 3 |
すべての演算子の完全なリストについては、演算子 を参照してください。
