- ES|QL 関数と演算子
- 関数の概要
- 演算子の概要
- ES|QL 集約関数
- AVG
- COUNT
- COUNT_DISTINCT
- カウントは近似値です
- MAX
- MEDIAN
- MEDIAN_ABSOLUTE_DEVIATION
- MIN
- PERCENTILE
- PERCENTILE is (usually) approximate
- ST_CENTROID_AGG
- SUM
- TOP
- VALUES
- WEIGHTED_AVG
- ES|QL grouping functions
- BUCKET
- ES|QL conditional functions and expressions
- CASE
- COALESCE
- ES|QL 関数と演算子
- LEAST
- ES|QL date-time functions
- DATE_DIFF
- DATE_EXTRACT
- DATE_FORMAT
- DATE_PARSE
- DATE_TRUNC
- NOW
- ES|QL IP functions
- CIDR_MATCH
- IP_PREFIX
- ES|QL mathematical functions
- ABS
- ACOS
- ASIN
- ATAN
- ATAN2
- CBRT
- CEIL
- COS
- COSH
- E
- FLOOR
- LOG
- LOG10
- PI
- POW
- ROUND
- SIGNUM
- SIN
- SINH
- SQRT
- TAN
- TANH
- TAU
- ES|QL spatial functions
- ST_INTERSECTS
- ST_DISJOINT
- ST_CONTAINS
- ST_WITHIN
- ST_X
- ST_Y
- ST_DISTANCE
- ES|QL string functions
- CONCAT
- ENDS_WITH
- FROM_BASE64
- LEFT
- LENGTH
- LOCATE
- LTRIM
- REPEAT
- REPLACE
- RIGHT
- RTRIM
- SPLIT
- STARTS_WITH
- SUBSTRING
- TO_BASE64
- TO_LOWER
- TO_UPPER
- TRIM
- ES|QL type conversion functions
- TO_BOOLEAN
- TO_CARTESIANPOINT
- TO_CARTESIANSHAPE
- TO_DATETIME
- TO_DEGREES
- TO_DOUBLE
- TO_GEOPOINT
- TO_GEOSHAPE
- TO_INTEGER
- TO_IP
- TO_LONG
- TO_RADIANS
- TO_STRING
- TO_UNSIGNED_LONG
- TO_VERSION
- ES|QL multivalue functions
- MV_APPEND
- MV_AVG
- MV_CONCAT
- MV_COUNT
- MV_DEDUPE
- MV_FIRST
- MV_LAST
- MV_MAX
- MV_MEDIAN
- MV_MIN
- MV_SLICE
- MV_SORT
- MV_SUM
- MV_ZIP
- ES|QL operators
- Binary operators
- Equality
- Inequality !=
- Less than <
- Less than or equal to <=
- Greater than >
- Greater than or equal to >=
- Add +
- " level="2">引き算 -

- 掛け算 *
- 割り算 /
- 剰余 %
- 単項演算子
- 論理演算子
- IS NULL および IS NOT NULL 述語
- キャスト (::)
- IN
- LIKE
- RLIKE
ES|QL 関数と演算子
ES|QL はデータを操作するための包括的な関数と演算子のセットを提供します。リファレンスドキュメントは以下のカテゴリに分かれています:
関数の概要
集約関数
AVGCOUNTCOUNT_DISTINCTMAXMEDIANMEDIAN_ABSOLUTE_DEVIATIONMINPERCENTILE- [プレビュー] この機能は技術プレビュー中であり、将来のリリースで変更または削除される可能性があります。Elastic は問題を修正するために取り組みますが、技術プレビューの機能は公式 GA 機能のサポート SLA の対象外です。
ST_CENTROID_AGG SUMTOPVALUES- [プレビュー] この機能は技術プレビュー中であり、将来のリリースで変更または削除される可能性があります。Elastic は問題を修正するために取り組みますが、技術プレビューの機能は公式 GA 機能のサポート SLA の対象外です。
WEIGHTED_AVG
グループ化関数
条件付き関数と式
日付と時間の関数
IP 関数
数学関数
ABSACOSASINATANATAN2CBRTCEILCOSCOSHEFLOORLOGLOG10PIPOWROUNDSIGNUMSINSINHSQRTTANTANHTAU
空間関数
- [プレビュー] この機能は技術プレビュー中であり、将来のリリースで変更または削除される可能性があります。Elastic は問題を修正するために取り組みますが、技術プレビューの機能は公式 GA 機能のサポート SLA の対象外です。
ST_INTERSECTS - [プレビュー] この機能は技術プレビュー中であり、将来のリリースで変更または削除される可能性があります。Elastic は問題を修正するために取り組みますが、技術プレビューの機能は公式 GA 機能のサポート SLA の対象外です。
ST_DISJOINT - [プレビュー] この機能は技術プレビュー中であり、将来のリリースで変更または削除される可能性があります。Elastic は問題を修正するために取り組みますが、技術プレビューの機能は公式 GA 機能のサポート SLA の対象外です。
ST_CONTAINS - [プレビュー] この機能は技術プレビュー中であり、将来のリリースで変更または削除される可能性があります。Elastic は問題を修正するために取り組みますが、技術プレビューの機能は公式 GA 機能のサポート SLA の対象外です。
ST_WITHIN - [プレビュー] この機能は技術プレビュー中であり、将来のリリースで変更または削除される可能性があります。Elastic は問題を修正するために取り組みますが、技術プレビューの機能は公式 GA 機能のサポート SLA の対象外です。
ST_X - [プレビュー] この機能は技術プレビュー中であり、将来のリリースで変更または削除される可能性があります。Elastic は問題を修正するために取り組みますが、技術プレビューの機能は公式 GA 機能のサポート SLA の対象外です。
ST_Y - [プレビュー] この機能は技術プレビュー中であり、将来のリリースで変更または削除される可能性があります。Elastic は問題を修正するために取り組みますが、技術プレビューの機能は公式 GA 機能のサポート SLA の対象外です。
ST_DISTANCE
文字列関数
CONCATENDS_WITHFROM_BASE64LEFTLENGTHLOCATELTRIMREPEATREPLACERIGHTRTRIMSPLITSTARTS_WITHSUBSTRINGTO_BASE64TO_LOWERTO_UPPERTRIM
型変換関数
TO_BOOLEANTO_CARTESIANPOINTTO_CARTESIANSHAPETO_DATETIMETO_DEGREESTO_DOUBLETO_GEOPOINTTO_GEOSHAPETO_INTEGERTO_IPTO_LONGTO_RADIANSTO_STRING- [プレビュー] この機能は技術プレビュー中であり、将来のリリースで変更または削除される可能性があります。Elastic は問題を修正するために取り組みますが、技術プレビューの機能は公式 GA 機能のサポート SLA の対象外です。
TO_UNSIGNED_LONG TO_VERSION
マルチバリュー関数
MV_APPENDMV_AVGMV_CONCATMV_COUNTMV_DEDUPEMV_FIRSTMV_LASTMV_MAXMV_MEDIANMV_MINMV_SORTMV_SLICEMV_SUMMV_ZIP
演算子の概要
演算子
ES|QL 集約関数
STATS ... BY コマンドは次の集約関数をサポートしています:
AVGCOUNTCOUNT_DISTINCTMAXMEDIANMEDIAN_ABSOLUTE_DEVIATIONMINPERCENTILE- [プレビュー] この機能は技術プレビュー中であり、将来のリリースで変更または削除される可能性があります。Elastic は問題を修正するために取り組みますが、技術プレビューの機能は公式 GA 機能のサポート SLA の対象外です。
ST_CENTROID_AGG SUMTOPVALUES- [プレビュー] この機能は技術プレビュー中であり、将来のリリースで変更または削除される可能性があります。Elastic は問題を修正するために取り組みますが、技術プレビューの機能は公式 GA 機能のサポート SLA の対象外です。
WEIGHTED_AVG
AVG
構文
Esql
AVG(expression)
expression- 数値式。
説明
数値式の平均。
サポートされる型
結果は常に double であり、入力型に関係ありません。
例
Esql
FROM employees| STATS AVG(height)
| AVG(height):double |
|---|
| 1.7682 |
この式はインライン関数を使用できます。たとえば、マルチバリュー列の平均を計算するには、まず MV_AVG を使用して行ごとの複数の値の平均を計算し、その結果を AVG 関数と共に使用します:
Esql
FROM employees| STATS avg_salary_change = ROUND(AVG(MV_AVG(salary_change)), 10)
| avg_salary_change:double |
|---|
| 1.3904535865 |
COUNT
構文
Esql
COUNT([expression])
パラメータ
expression- カウントされる値を出力する式。省略した場合、
COUNT(*)(行数)と同等です。
説明
入力値の合計数(カウント)を返します。
サポートされる型
任意のフィールド型を入力として受け取ることができます。
例
Esql
FROM employees| STATS COUNT(height)
| COUNT(height):long |
|---|
| 100 |
行数をカウントするには、COUNT() または COUNT(*) を使用します:
Esql
FROM employees| STATS count = COUNT(*) BY languages| SORT languages DESC
| count:long | languages:integer |
|---|---|
| 10 | null |
| 21 | 5 |
| 18 | 4 |
| 17 | 3 |
| 19 | 2 |
| 15 | 1 |
この式はインライン関数を使用できます。この例では、SPLIT 関数を使用して文字列を複数の値に分割し、その値をカウントします:
Esql
ROW words="foo;bar;baz;qux;quux;foo"| STATS word_count = COUNT(SPLIT(words, ";"))
| word_count:long |
|---|
| 6 |
COUNT_DISTINCT
構文
Esql
COUNT_DISTINCT(expression[, precision_threshold])
パラメータ
expression- 一意のカウントを実行する値を出力する式。
precision_threshold- 精度の閾値。カウントは近似値ですを参照してください。サポートされる最大値は 40000 です。この数値を超える閾値は、40000 の閾値と同じ効果を持ちます。デフォルト値は 3000 です。
説明
近似的な一意の値の数を返します。
サポートされる型
任意のフィールド型を入力として受け取ることができます。
例
Esql
FROM hosts| STATS COUNT_DISTINCT(ip0), COUNT_DISTINCT(ip1)
| COUNT_DISTINCT(ip0):long | COUNT_DISTINCT(ip1):long |
|---|---|
| 7 | 8 |
オプションの第二パラメータを使用して精度の閾値を設定します:
Esql
FROM hosts| STATS COUNT_DISTINCT(ip0, 80000), COUNT_DISTINCT(ip1, 5)
| COUNT_DISTINCT(ip0, 80000):long | COUNT_DISTINCT(ip1, 5):long |
|---|---|
| 7 | 9 |
この式はインライン関数を使用できます。この例では、SPLIT 関数を使用して文字列を複数の値に分割し、一意の値をカウントします:
Esql
ROW words="foo;bar;baz;qux;quux;foo"| STATS distinct_word_count = COUNT_DISTINCT(SPLIT(words, ";"))
| distinct_word_count:long |
|---|
| 5 |
カウントは近似値です
正確なカウントを計算するには、値をセットに読み込み、そのサイズを返す必要があります。これは、高カーディナリティのセットや大きな値を扱う場合にはスケールしません。必要なメモリ使用量と、ノード間でそれらのシャードごとのセットを通信する必要があるため、クラスターのリソースを過剰に使用します。
この COUNT_DISTINCT 関数は、HyperLogLog++ アルゴリズムに基づいており、値のハッシュに基づいてカウントを行い、いくつかの興味深い特性を持っています:
- 設定可能な精度、メモリと精度のトレードオフを決定します、
- 低カーディナリティのセットに対して優れた精度、
- 固定メモリ使用量:ユニークな値が数十または数十億であっても、メモリ使用量は設定された精度のみに依存します。
c の精度の閾値の場合、私たちが使用している実装は約 c * 8 バイトを必要とします。
以下のチャートは、閾値の前後でエラーがどのように変化するかを示しています:
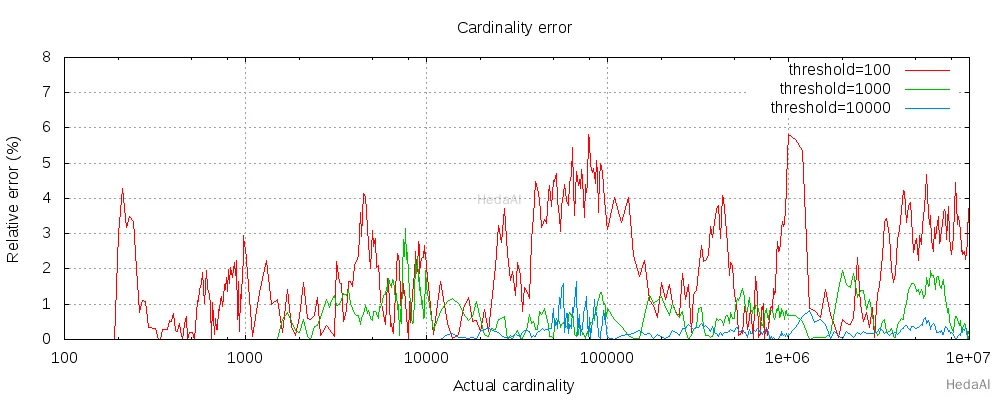
すべての 3 つの閾値に対して、カウントは設定された閾値まで正確でした。保証はされていませんが、これはその可能性が高いです。実際の精度は、問題のデータセットに依存します。一般的に、ほとんどのデータセットは一貫して良好な精度を示します。また、閾値が 100 のように低くても、エラーは非常に低く(上記のグラフで見られるように 1-6%)、数百万のアイテムをカウントする場合でも同様です。
HyperLogLog++ アルゴリズムは、ハッシュ値の先頭のゼロに依存しており、データセット内のハッシュの正確な分布がカーディナリティの精度に影響を与える可能性があります。
COUNT_DISTINCT 関数は、精度の閾値を設定するためのオプションの第二パラメータを受け取ります。precision_threshold オプションは、メモリと精度のトレードオフを可能にし、カウントが正確に近いと期待される一意のカウントを定義します。この値を超えると、カウントは少しあいまいになる可能性があります。サポートされる最大値は 40000 であり、この数値を超える閾値は 40000 の閾値と同じ効果を持ちます。デフォルト値は 3000 です。
MAX
構文
Esql
MAX(expression)
パラメータ
expression- 最大値を返す式。
説明
数値式の最大値を返します。
例
Esql
FROM employees| STATS MAX(languages)
| MAX(languages):integer |
|---|
| 5 |
この式はインライン関数を使用できます。たとえば、マルチバリュー列の平均の最大値を計算するには、MV_AVG を使用して行ごとの複数の値の平均を計算し、その結果を MAX 関数と共に使用します:
Esql
FROM employees| STATS max_avg_salary_change = MAX(MV_AVG(salary_change))
| max_avg_salary_change:double |
|---|
| 13.75 |
MEDIAN
構文
Esql
MEDIAN(expression)
パラメータ
expression- 中央値を返す式。
説明
すべての値の半分より大きく、すべての値の半分より小さい値を返します。これは 50% PERCENTILE としても知られています。
PERCENTILE と同様に、MEDIAN は 通常近似値 です。
MEDIAN も 非決定的 です。これは、同じデータを使用してもわずかに異なる結果が得られることを意味します。
例
Esql
FROM employees| STATS MEDIAN(salary), PERCENTILE(salary, 50)
| MEDIAN(salary):double | PERCENTILE(salary, 50):double |
|---|---|
| 47003 | 47003 |
この式はインライン関数を使用できます。たとえば、マルチバリュー列の最大値の中央値を計算するには、まず MV_MAX を使用して行ごとの最大値を取得し、その結果を MEDIAN 関数と共に使用します:
Esql
FROM employees| STATS median_max_salary_change = MEDIAN(MV_MAX(salary_change))
| median_max_salary_change:double |
|---|
| 7.69 |
MEDIAN_ABSOLUTE_DEVIATION
構文
Esql
MEDIAN_ABSOLUTE_DEVIATION(expression)
パラメータ
expression- 中位数絶対偏差を返すための式。
説明
中位数絶対偏差を返します。これは変動性の指標です。ロバストな統計量であり、外れ値があるか、正規分布していないデータを記述するのに役立ちます。このようなデータに対しては、標準偏差よりも説明的であることがあります。
これは、各データポイントの中央値からの偏差の中央値として計算されます。すなわち、ランダム変数 X に対して、中位数絶対偏差は median(|median(X) - X|) です。
PERCENTILE のように、MEDIAN_ABSOLUTE_DEVIATION は 通常近似的 です。
MEDIAN_ABSOLUTE_DEVIATION は 非決定的 でもあります。これは、同じデータを使用してもわずかに異なる結果が得られることを意味します。
例
Esql
FROM employees| STATS MEDIAN(salary), MEDIAN_ABSOLUTE_DEVIATION(salary)
| MEDIAN(salary):double | MEDIAN_ABSOLUTE_DEVIATION(salary):double |
|---|---|
| 47003 | 10096.5 |
式はインライン関数を使用できます。たとえば、多値列の最大値の中位数絶対偏差を計算するには、まず MV_MAX を使用して行ごとの最大値を取得し、その結果を MEDIAN_ABSOLUTE_DEVIATION 関数と共に使用します:
Esql
FROM employees| STATS m_a_d_max_salary_change = MEDIAN_ABSOLUTE_DEVIATION(MV_MAX(salary_change))
| m_a_d_max_salary_change:double |
|---|
| 5.69 |
MIN
構文
Esql
MIN(expression)
パラメータ
expression- 最小値を返すための式。
説明
数値式の最小値を返します。
例
Esql
FROM employees| STATS MIN(languages)
| MIN(languages):integer |
|---|
| 1 |
式はインライン関数を使用できます。たとえば、多値列の平均の最小値を計算するには、まず MV_AVG を使用して行ごとの複数の値の平均を計算し、その結果を MIN 関数と共に使用します:
Esql
FROM employees| STATS min_avg_salary_change = MIN(MV_AVG(salary_change))
| min_avg_salary_change:double |
|---|
| -8.46 |
PERCENTILE
構文
Esql
PERCENTILE(expression, percentile)
パラメータ
expression- パーセンタイルを返すための式。
percentile- 定数数値式。
説明
観測された値の特定の割合が発生する値を返します。たとえば、95パーセンタイルは観測された値の95%より大きい値であり、50パーセンタイルは MEDIAN です。
例
Esql
FROM employees| STATS p0 = PERCENTILE(salary, 0), p50 = PERCENTILE(salary, 50), p99 = PERCENTILE(salary, 99)
| p0:double | p50:double | p99:double |
|---|---|---|
| 25324 | 47003 | 74970.29 |
式はインライン関数を使用できます。たとえば、多値列の最大値のパーセンタイルを計算するには、まず MV_MAX を使用して行ごとの最大値を取得し、その結果を PERCENTILE 関数と共に使用します:
Esql
FROM employees| STATS p80_max_salary_change = PERCENTILE(MV_MAX(salary_change), 80)
| p80_max_salary_change:double |
|---|
| 12.132 |
PERCENTILE is (usually) approximate
パーセンタイルを計算するためのさまざまなアルゴリズムがあります。単純な実装は、すべての値をソートされた配列に保存します。50パーセンタイルを見つけるには、my_array[count(my_array) * 0.5] にある値を見つけるだけです。
明らかに、単純な実装はスケールしません。ソートされた配列は、データセット内の値の数に対して線形に成長します。Elasticsearchクラスター内の数十億の値にわたってパーセンタイルを計算するために、近似パーセンタイルが計算されます。
percentile メトリクスで使用されるアルゴリズムは、TDigest(Computing Accurate Quantiles using T-DigestsでTed Dunningによって導入されました)と呼ばれます。
このメトリクスを使用する際には、いくつかのガイドラインを考慮する必要があります:
- 精度は
q(1-q)に比例します。これは、極端なパーセンタイル(例:99%)が中央値などのあまり極端でないパーセンタイルよりも正確であることを意味します。 - 小さな値のセットでは、パーセンタイルは非常に正確です(データが十分に小さい場合、潜在的に100%正確です)。
- バケット内の値の量が増えるにつれて、アルゴリズムはパーセンタイルを近似し始めます。これは、精度をメモリの節約と引き換えにしていることを意味します。正確な不正確さのレベルは一般化するのが難しいです。なぜなら、それはデータ分布と集約されるデータの量に依存するからです。
次のチャートは、収集された値の数と要求されたパーセンタイルに応じた均一分布の相対誤差を示しています:
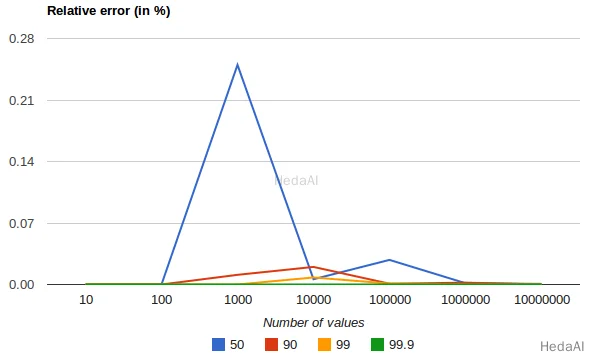
これは、精度が極端なパーセンタイルに対してより良いことを示しています。多くの値に対して誤差が減少する理由は、大数の法則が値の分布をますます均一にし、t-digestツリーがそれを要約するのにより良い仕事をするからです。より歪んだ分布ではそうではありません。
PERCENTILE は 非決定的 でもあります。これは、同じデータを使用してもわずかに異なる結果が得られることを意味します。
ST_CENTROID_AGG
この機能は技術プレビュー中であり、将来のリリースで変更または削除される可能性があります。Elasticは問題を修正するために取り組みますが、技術プレビューの機能は公式GA機能のサポートSLAの対象ではありません。
空間ポイントジオメトリタイプのフィールドに対して空間セントロイドを計算します。
Esql
FROM airports| STATS centroid=ST_CENTROID_AGG(location)
| centroid:geo_point |
|---|
| POINT(-0.030548143003023033 24.37553649504829) |
サポートされているタイプ:
| v | result |
|---|---|
| geo_point | geo_point |
| cartesian_point | cartesian_point |
SUM
構文
Esql
SUM(expression)
expression- 数値式。
説明
数値式の合計を返します。
例
Esql
FROM employees| STATS SUM(languages)
| SUM(languages):long |
|---|
| 281 |
式はインライン関数を使用できます。たとえば、各従業員の最大給与の変化の合計を計算するには、MV_MAX 関数を各行に適用し、その後結果を合計します:
Esql
FROM employees| STATS total_salary_changes = SUM(MV_MAX(salary_change))
| total_salary_changes:double |
|---|
| 446.75 |
TOP
構文

パラメータ
field- トップ値を収集するフィールド。
limit- 収集する最大値の数。
order- トップ値を計算する順序。
ascまたはdescのいずれか。
説明
フィールドのトップ値を収集します。繰り返し値を含みます。
サポートされる型
| field | limit | order | result |
|---|---|---|---|
| date | integer | keyword | date |
| double | integer | keyword | double |
| integer | integer | keyword | integer |
| long | integer | keyword | long |
例
Esql
FROM employees| STATS top_salaries = TOP(salary, 3, "desc"), top_salary = MAX(salary)
| top_salaries:integer | top_salary:integer |
|---|---|
| [74999, 74970, 74572] | 74999 |
VALUES
本番環境で VALUES を使用しないでください。この機能は技術プレビュー中であり、将来のリリースで変更または削除される可能性があります。Elastic は問題を修正するために取り組みますが、技術プレビューの機能は公式 GA 機能のサポート SLA の対象ではありません。
構文
Esql
VALUES(expression)
expressiongeo_point、cartesian_point、geo_shape、またはcartesian_shape以外の任意の型の式。
説明
グループ内のすべての値を多値フィールドとして返します。返される値の順序は保証されません。順序で返される値が必要な場合は、MV_SORT を使用してください。
これはかなりのメモリを使用する可能性があり、ES|QL はまだメモリを超えて集計を成長させません。したがって、この集計は、メモリに収まる以上の値を収集するために使用されるまで機能します。あまりにも多くの値を収集すると、サーキットブレイカーエラー でクエリが失敗します。
例
Esql
FROM employees| EVAL first_letter = SUBSTRING(first_name, 0, 1)| STATS first_name=MV_SORT(VALUES(first_name)) BY first_letter| SORT first_letter
| first_name:keyword | first_letter:keyword |
|---|---|
| [Alejandro, Amabile, Anneke, Anoosh, Arumugam] | A |
| [Basil, Berhard, Berni, Bezalel, Bojan, Breannda, Brendon] | B |
| [Charlene, Chirstian, Claudi, Cristinel] | C |
| [Danel, Divier, Domenick, Duangkaew] | D |
| [Ebbe, Eberhardt, Erez] | E |
| Florian | F |
| [Gao, Georgi, Georgy, Gino, Guoxiang] | G |
| [Heping, Hidefumi, Hilari, Hironobu, Hironoby, Hisao] | H |
| [Jayson, Jungsoon] | J |
| [Kazuhide, Kazuhito, Kendra, Kenroku, Kshitij, Kwee, Kyoichi] | K |
| [Lillian, Lucien] | L |
| [Magy, Margareta, Mary, Mayuko, Mayumi, Mingsen, Mokhtar, Mona, Moss] | M |
| Otmar | O |
| [Parto, Parviz, Patricio, Prasadram, Premal] | P |
| [Ramzi, Remzi, Reuven] | R |
| [Sailaja, Saniya, Sanjiv, Satosi, Shahaf, Shir, Somnath, Sreekrishna, Sudharsan, Sumant, Suzette] | S |
| [Tse, Tuval, Tzvetan] | T |
| [Udi, Uri] | U |
| [Valdiodio, Valter, Vishv] | V |
| Weiyi | W |
| Xinglin | X |
| [Yinghua, Yishay, Yongqiao] | Y |
| [Zhongwei, Zvonko] | Z |
| null | null |
WEIGHTED_AVG
構文
Esql
WEIGHTED_AVG(expression, weight)
expression- 数値式。
weight- 数値の重み。
説明
数値式の加重平均。
サポートされる型
結果は常に double であり、入力型に関係ありません。
例
Esql
FROM employees| STATS w_avg = WEIGHTED_AVG(salary, height) by languages| EVAL w_avg = ROUND(w_avg)| KEEP w_avg, languages| SORT languages
| w_avg:double | languages:integer |
|---|---|
| 51464.0 | 1 |
| 48477.0 | 2 |
| 52379.0 | 3 |
| 47990.0 | 4 |
| 42119.0 | 5 |
| 52142.0 | null |
ES|QL grouping functions
STATS ... BY コマンドは、これらのグループ化関数をサポートしています:
BUCKET
構文

パラメータ
field- バケットを導出するための数値または日付の式。
buckets- バケットの目標数。
from- 範囲の開始。数値または文字列として表現された日付である可能性があります。
to- 範囲の終了。数値または文字列として表現された日付である可能性があります。
説明
日付時刻または数値入力から値のグループ - バケット - を作成します。バケットのサイズは、直接提供するか、推奨されるカウントと値の範囲に基づいて選択できます。
サポートされる型
| field | buckets | from | to | result |
|---|---|---|---|---|
| date | date_period | date | ||
| date | integer | date | date | date |
| date | time_duration | date | ||
| double | double | double | ||
| double | integer | double | double | double |
| double | integer | double | integer | double |
| double | integer | double | long | double |
| double | integer | integer | double | double |
| double | integer | integer | integer | double |
| double | integer | integer | long | double |
| double | integer | long | double | double |
| double | integer | long | integer | double |
| double | integer | long | long | double |
| integer | double | double | ||
| integer | integer | double | double | double |
| integer | integer | double | integer | double |
| integer | integer | double | long | double |
| integer | integer | integer | double | double |
| integer | integer | integer | integer | double |
| integer | integer | integer | long | double |
| integer | integer | long | double | double |
| integer | integer | long | integer | double |
| integer | integer | long | long | double |
| long | double | double | ||
| long | integer | double | double | double |
| long | integer | double | integer | double |
| long | integer | double | long | double |
| long | integer | integer | double | double |
| long | integer | integer | integer | double |
| long | integer | integer | long | double |
| long | integer | long | double | double |
| long | integer | long | integer | double |
| long | integer | long | long | double |
例
BUCKET は二つのモードで動作できます: 一つはバケットのサイズがバケット数の推奨に基づいて計算されるモード(四つのパラメータ)で、もう一つはバケットサイズが直接提供されるモード(二つのパラメータ)です。
目標バケット数、範囲の開始、範囲の終了を使用して、BUCKET は目標バケット数またはそれ以下の適切なバケットサイズを選択します。たとえば、1年で最大20のバケットを要求すると、月ごとのバケットが得られます:
Esql
FROM employees| WHERE hire_date >= "1985-01-01T00:00:00Z" AND hire_date < "1986-01-01T00:00:00Z"| STATS hire_date = MV_SORT(VALUES(hire_date)) BY month = BUCKET(hire_date, 20, "1985-01-01T00:00:00Z", "1986-01-01T00:00:00Z")| SORT hire_date
| hire_date:date | month:date |
|---|---|
| [1985-02-18T00:00:00.000Z, 1985-02-24T00:00:00.000Z] | 1985-02-01T00:00:00.000Z |
| 1985-05-13T00:00:00.000Z | 1985-05-01T00:00:00.000Z |
| 1985-07-09T00:00:00.000Z | 1985-07-01T00:00:00.000Z |
| 1985-09-17T00:00:00.000Z | 1985-09-01T00:00:00.000Z |
| [1985-10-14T00:00:00.000Z, 1985-10-20T00:00:00.000Z] | 1985-10-01T00:00:00.000Z |
| [1985-11-19T00:00:00.000Z, 1985-11-20T00:00:00.000Z, 1985-11-21T00:00:00.000Z] | 1985-11-01T00:00:00.000Z |
目標は、正確に目標バケット数を提供することではなく、人々が快適に感じる範囲を選択し、最大で目標バケット数を提供することです。
[BUCKET] と 集計 を組み合わせてヒストグラムを作成します:
Esql
FROM employees| WHERE hire_date >= "1985-01-01T00:00:00Z" AND hire_date < "1986-01-01T00:00:00Z"| STATS hires_per_month = COUNT(*) BY month = BUCKET(hire_date, 20, "1985-01-01T00:00:00Z", "1986-01-01T00:00:00Z")| SORT month
| hires_per_month:long | month:date |
|---|---|
| 2 | 1985-02-01T00:00:00.000Z |
| 1 | 1985-05-01T00:00:00.000Z |
| 1 | 1985-07-01T00:00:00.000Z |
| 1 | 1985-09-01T00:00:00.000Z |
| 2 | 1985-10-01T00:00:00.000Z |
| 4 | 1985-11-01T00:00:00.000Z |
BUCKET は、ドキュメントに一致しないバケットを作成しません。これが、この例で 1985-03-01 や他の日付が欠落している理由です。
より多くのバケットを要求すると、より小さな範囲になる可能性があります。たとえば、1年で最大100のバケットを要求すると、週ごとのバケットが得られます:
Esql
FROM employees| WHERE hire_date >= "1985-01-01T00:00:00Z" AND hire_date < "1986-01-01T00:00:00Z"| STATS hires_per_week = COUNT(*) BY week = BUCKET(hire_date, 100, "1985-01-01T00:00:00Z", "1986-01-01T00:00:00Z")| SORT week
| hires_per_week:long | week:date |
|---|---|
| 2 | 1985-02-18T00:00:00.000Z |
| 1 | 1985-05-13T00:00:00.000Z |
| 1 | 1985-07-08T00:00:00.000Z |
| 1 | 1985-09-16T00:00:00.000Z |
| 2 | 1985-10-14T00:00:00.000Z |
| 4 | 1985-11-18T00:00:00.000Z |
BUCKET は、行をフィルタリングしません。提供された範囲を使用して適切なバケットサイズを選択するだけです。範囲外の値を持つ行には、範囲外のバケットに対応するバケット値が返されます。BUCKET を WHERE と組み合わせて行をフィルタリングします。
希望するバケットサイズが事前にわかっている場合は、単にそれを第二引数として提供し、範囲を省略します:
Esql
FROM employees| WHERE hire_date >= "1985-01-01T00:00:00Z" AND hire_date < "1986-01-01T00:00:00Z"| STATS hires_per_week = COUNT(*) BY week = BUCKET(hire_date, 1 week)| SORT week
| hires_per_week:long | week:date |
|---|---|
| 2 | 1985-02-18T00:00:00.000Z |
| 1 | 1985-05-13T00:00:00.000Z |
| 1 | 1985-07-08T00:00:00.000Z |
| 1 | 1985-09-16T00:00:00.000Z |
| 2 | 1985-10-14T00:00:00.000Z |
| 4 | 1985-11-18T00:00:00.000Z |
バケットサイズを第二引数として提供する場合、それは時間の長さまたは日付の期間でなければなりません。
BUCKET は数値フィールドでも動作できます。たとえば、給与のヒストグラムを作成するには:
Esql
FROM employees| STATS COUNT(*) by bs = BUCKET(salary, 20, 25324, 74999)| SORT bs
| COUNT(*):long | bs:double |
|---|---|
| 9 | 25000.0 |
| 9 | 30000.0 |
| 18 | 35000.0 |
| 11 | 40000.0 |
| 11 | 45000.0 |
| 10 | 50000.0 |
| 7 | 55000.0 |
| 9 | 60000.0 |
| 8 | 65000.0 |
| 8 | 70000.0 |
以前の例とは異なり、日付範囲で意図的にフィルタリングすることはほとんどありません。数値範囲でフィルタリングする必要があります。min と max を別々に見つける必要があります。ES|QL には、まだ自動的にそれを行う簡単な方法がありません。
希望するバケットサイズが事前にわかっている場合は、単にそれを第二引数として提供します:
Esql
FROM employees| WHERE hire_date >= "1985-01-01T00:00:00Z" AND hire_date < "1986-01-01T00:00:00Z"| STATS c = COUNT(1) BY b = BUCKET(salary, 5000.)| SORT b
| c:long | b:double |
|---|---|
| 1 | 25000.0 |
| 1 | 30000.0 |
| 1 | 40000.0 |
| 2 | 45000.0 |
| 2 | 50000.0 |
| 1 | 55000.0 |
| 1 | 60000.0 |
バケットサイズを第二引数として提供する場合、それは浮動小数点型でなければなりません。
過去24時間の時間ごとのバケットを作成し、時間ごとのイベント数を計算します:
Esql
FROM sample_data| WHERE @timestamp >= NOW() - 1 day and @timestamp < NOW()| STATS COUNT(*) BY bucket = BUCKET(@timestamp, 25, NOW() - 1 day, NOW())
| COUNT(*):long | bucket:date |
|---|---|
1985年の月ごとのバケットを作成し、採用月ごとの平均給与を計算します
Esql
FROM employees| WHERE hire_date >= "1985-01-01T00:00:00Z" AND hire_date < "1986-01-01T00:00:00Z"| STATS AVG(salary) BY bucket = BUCKET(hire_date, 20, "1985-01-01T00:00:00Z", "1986-01-01T00:00:00Z")| SORT bucket
| AVG(salary):double | bucket:date |
|---|---|
| 46305.0 | 1985-02-01T00:00:00.000Z |
| 44817.0 | 1985-05-01T00:00:00.000Z |
| 62405.0 | 1985-07-01T00:00:00.000Z |
| 49095.0 | 1985-09-01T00:00:00.000Z |
| 51532.0 | 1985-10-01T00:00:00.000Z |
| 54539.75 | 1985-11-01T00:00:00.000Z |
BUCKET は、BUCKET コマンドの集計部分とグループ化部分の両方で使用できます。ただし、集計部分では、関数がグループ化部分で定義されたエイリアスによって参照されるか、正確に同じ式で呼び出される必要があります:
Esql
FROM employees| STATS s1 = b1 + 1, s2 = BUCKET(salary / 1000 + 999, 50.) + 2 BY b1 = BUCKET(salary / 100 + 99, 50.), b2 = BUCKET(salary / 1000 + 999, 50.)| SORT b1, b2| KEEP s1, b1, s2, b2
| s1:double | b1:double | s2:double | b2:double |
|---|---|---|---|
| 351.0 | 350.0 | 1002.0 | 1000.0 |
| 401.0 | 400.0 | 1002.0 | 1000.0 |
| 451.0 | 450.0 | 1002.0 | 1000.0 |
| 501.0 | 500.0 | 1002.0 | 1000.0 |
| 551.0 | 550.0 | 1002.0 | 1000.0 |
| 601.0 | 600.0 | 1002.0 | 1000.0 |
| 601.0 | 600.0 | 1052.0 | 1050.0 |
| 651.0 | 650.0 | 1052.0 | 1050.0 |
| 701.0 | 700.0 | 1052.0 | 1050.0 |
| 751.0 | 750.0 | 1052.0 | 1050.0 |
| 801.0 | 800.0 | 1052.0 | 1050.0 |
ES|QL conditional functions and expressions
条件関数は、if-else の方法で評価することによって引数の一つを返します。ES|QL はこれらの条件関数をサポートしています:
CASE
構文

パラメータ
condition- 条件。
trueValue- 対応する条件が最初に
trueに評価されるときに返される値。条件が一致しない場合はデフォルト値が返されます。
説明
条件と値のペアを受け入れます。この関数は、最初に true に評価される条件に属する値を返します。引数の数が奇数の場合、最後の引数はデフォルト値であり、条件が一致しない場合に返されます。引数の数が偶数で、条件が一致しない場合、関数は null を返します。
サポートされる型
| condition | trueValue | result |
|---|---|---|
| boolean | boolean | boolean |
| boolean | cartesian_point | cartesian_point |
| boolean | date | date |
| boolean | double | double |
| boolean | geo_point | geo_point |
| boolean | integer | integer |
| boolean | ip | ip |
| boolean | long | long |
| boolean | text | text |
| boolean | unsigned_long | unsigned_long |
| boolean | version | version |
例
従業員が単言語話者、バイリンガル、または多言語話者であるかどうかを判断します:
Esql
FROM employees| EVAL type = CASE(languages <= 1, "monolingual",languages <= 2, "bilingual","polyglot")| KEEP emp_no, languages, type
| emp_no:integer | languages:integer | type:keyword |
|---|---|---|
| 10001 | 2 | バイリンガル |
| 10002 | 5 | 多言語話者 |
| 10003 | 4 | 多言語話者 |
| 10004 | 5 | 多言語話者 |
| 10005 | 1 | 単言語話者 |
ログメッセージに基づいて接続成功率の合計を計算します:
Esql
FROM sample_data| EVAL successful = CASE(STARTS_WITH(message, "Connected to"), 1,message == "Connection error", 0)| STATS success_rate = AVG(successful)
| success_rate:double |
|---|
| 0.5 |
ログメッセージの総数に対する時間ごとのエラー率を計算します:
Esql
FROM sample_data| EVAL error = CASE(message LIKE "*error*", 1, 0)| EVAL hour = DATE_TRUNC(1 hour, @timestamp)| STATS error_rate = AVG(error) by hour| SORT hour
| error_rate:double | hour:date |
|---|---|
| 0.0 | 2023-10-23T12:00:00.000Z |
| 0.6 | 2023-10-23T13:00:00.000Z |
COALESCE
構文

パラメータ
first- 評価する式。
rest- 評価する他の式。
説明
最初の引数が null でないものを返します。すべての引数が null の場合、null を返します。
サポートされる型
| first | rest | result |
|---|---|---|
| boolean | boolean | boolean |
| boolean | boolean | |
| cartesian_point | cartesian_point | cartesian_point |
| cartesian_shape | cartesian_shape | cartesian_shape |
| date | date | date |
| geo_point | geo_point | geo_point |
| geo_shape | geo_shape | geo_shape |
| integer | integer | integer |
| integer | integer | |
| ip | ip | ip |
| keyword | keyword | keyword |
| keyword | keyword | |
| long | long | long |
| long | long | |
| text | text | text |
| text | text | |
| version | version | version |
例
Esql
ROW a=null, b="b"| EVAL COALESCE(a, b)
| a:null | b:keyword | COALESCE(a, b):keyword |
|---|---|---|
| null | b | b |
ES|QL 関数と演算子
ES|QL はデータを操作するための包括的な関数と演算子のセットを提供します。リファレンスドキュメントは以下のカテゴリに分かれています:
Esql
ROW a = 10, b = 20| EVAL g = GREATEST(a, b)
| a:integer | b:integer | g:integer |
|---|---|---|
| 10 | 20 | 20 |
LEAST
構文

パラメータ
first- 評価する最初の列。
rest- 評価する残りの列。
説明
複数の列から最小値を返します。これはMV_MINに似ていますが、複数の列を同時に実行することを目的としています。
サポートされる型
| first | rest | result |
|---|---|---|
| boolean | boolean | boolean |
| boolean | boolean | |
| double | double | double |
| integer | integer | integer |
| integer | integer | |
| ip | ip | ip |
| keyword | keyword | keyword |
| keyword | keyword | |
| long | long | long |
| long | long | |
| text | text | text |
| text | text | |
| version | version | version |
例
Esql
ROW a = 10, b = 20| EVAL l = LEAST(a, b)
| a:integer | b:integer | l:integer |
|---|---|---|
| 10 | 20 | 10 |
ES|QL date-time functions
ES|QLは次の日時関数をサポートしています:
DATE_DIFF
構文

パラメータ
unit- 時間差の単位
startTimestamp- 開始タイムスタンプを表す文字列
endTimestamp- 終了タイムスタンプを表す文字列
説明
| 日付時刻の差の単位 || :-: || **単位** | **略語** || 年 | 年、yy、yyyy || 四半期 | 四半期、qq、q || 月 | 月、mm、m || 年の日 | dy、y || 日 | 日、dd、d || 週 | 週、wk、ww || 曜日 | 曜日、dw || 時間 | 時間、hh || 分 | 分、mi、n || 秒 | 秒、ss、s || ミリ秒 | ミリ秒、ms || マイクロ秒 | マイクロ秒、mcs || ナノ秒 | ナノ秒、ns |関数がサポートする単位とES|QLがサポートする時間範囲リテラルの間には重複がありますが、これらのセットは異なり、相互に交換可能ではありません。同様に、サポートされている略語は、この関数の他の確立された製品での実装と便利に共有されており、Elasticsearchで使用される日時の命名法と必ずしも共通ではありません。**サポートされる型**| unit | startTimestamp | endTimestamp | result || :-- | :-- | :-- | :-- || keyword | date | date | integer || text | date | date | integer |**例**#### Esql``````esqlROW date1 = TO_DATETIME("2023-12-02T11:00:00.000Z"), date2 = TO_DATETIME("2023-12-02T11:00:00.001Z")| EVAL dd_ms = DATE_DIFF("microseconds", date1, date2)`
| date1:date | date2:date | dd_ms:integer |
|---|---|---|
| 2023-12-02T11:00:00.000Z | 2023-12-02T11:00:00.001Z | 1000 |
DATE_EXTRACT
構文

パラメータ
datePart- 抽出する日付の部分。可能な値:
aligned_day_of_week_in_month,aligned_day_of_week_in_year,aligned_week_of_month,aligned_week_of_year,ampm_of_day,clock_hour_of_ampm,clock_hour_of_day,day_of_month,day_of_week,day_of_year,epoch_day,era,hour_of_ampm,hour_of_day,instant_seconds,micro_of_day,micro_of_second,milli_of_day,milli_of_second,minute_of_day,minute_of_hour,month_of_year,nano_of_day,nano_of_second,offset_seconds,proleptic_month,second_of_day,second_of_minute,year, またはyear_of_era。これらの値の説明についてはjava.time.temporal.ChronoFieldを参照してください。nullの場合、関数はnullを返します。 date- 日付式。
nullの場合、関数はnullを返します。
説明
年、月、日、時などの部分を抽出します。
サポートされる型
| datePart | date | result |
|---|---|---|
| keyword | date | long |
| text | date | long |
例
Esql
ROW date = DATE_PARSE("yyyy-MM-dd", "2022-05-06")| EVAL year = DATE_EXTRACT("year", date)
| date:date | year:long |
|---|---|
| 2022-05-06T00:00:00.000Z | 2022 |
営業時間外(午前9時前または午後5時以降)に発生したすべてのイベントを特定します。
Esql
FROM sample_data| WHERE DATE_EXTRACT("hour_of_day", @timestamp) < 9 AND DATE_EXTRACT("hour_of_day", @timestamp) >= 17
| @timestamp:date | client_ip:ip | event_duration:long | message:keyword |
|---|---|---|---|
DATE_FORMAT
構文

パラメータ
dateFormat- 日付形式(オプション)。形式が指定されていない場合、
yyyy-MM-dd'T'HH:mm:ss.SSSZ形式が使用されます。nullの場合、関数はnullを返します。 date- 日付式。
nullの場合、関数はnullを返します。
説明
指定された形式で日付の文字列表現を返します。
サポートされる型
| dateFormat | date | result |
|---|---|---|
| keyword | date | keyword |
| text | date | keyword |
例
Esql
FROM employees| KEEP first_name, last_name, hire_date| EVAL hired = DATE_FORMAT("yyyy-MM-dd", hire_date)
| first_name:keyword | last_name:keyword | hire_date:date | hired:keyword |
|---|---|---|---|
| Alejandro | McAlpine | 1991-06-26T00:00:00.000Z | 1991-06-26 |
| Amabile | Gomatam | 1992-11-18T00:00:00.000Z | 1992-11-18 |
| Anneke | Preusig | 1989-06-02T00:00:00.000Z | 1989-06-02 |
DATE_PARSE
構文

パラメータ
datePattern- 日付形式。構文については
DateTimeFormatterのドキュメントを参照してください。nullの場合、関数はnullを返します。 dateString- 文字列としての日付式。
nullまたは空の文字列の場合、関数はnullを返します。
説明
指定された形式を使用して2番目の引数を解析することにより、日付を返します。
サポートされる型
| datePattern | dateString | result |
|---|---|---|
| keyword | keyword | date |
| keyword | text | date |
| text | keyword | date |
| text | text | date |
例
Esql
ROW date_string = "2022-05-06"| EVAL date = DATE_PARSE("yyyy-MM-dd", date_string)
| date_string:keyword | date:date |
|---|---|
| 2022-05-06 | 2022-05-06T00:00:00.000Z |
DATE_TRUNC
構文

パラメータ
interval- インターバル; タイムスパンリテラル構文を使用して表現されます。
date- 日付式
説明
最も近いインターバルに日付を切り捨てます。
サポートされる型
| interval | date | result |
|---|---|---|
| date_period | date | date |
| time_duration | date | date |
例
Esql
FROM employees| KEEP first_name, last_name, hire_date| EVAL year_hired = DATE_TRUNC(1 year, hire_date)
| first_name:keyword | last_name:keyword | hire_date:date | year_hired:date |
|---|---|---|---|
| Alejandro | McAlpine | 1991-06-26T00:00:00.000Z | 1991-01-01T00:00:00.000Z |
| Amabile | Gomatam | 1992-11-18T00:00:00.000Z | 1992-01-01T00:00:00.000Z |
| Anneke | Preusig | 1989-06-02T00:00:00.000Z | 1989-01-01T00:00:00.000Z |
DATE_TRUNCをSTATS ... BYと組み合わせて日付ヒストグラムを作成します。たとえば、年ごとの雇用数:
Esql
FROM employees| EVAL year = DATE_TRUNC(1 year, hire_date)| STATS hires = COUNT(emp_no) BY year| SORT year
| hires:long | year:date |
|---|---|
| 11 | 1985-01-01T00:00:00.000Z |
| 11 | 1986-01-01T00:00:00.000Z |
| 15 | 1987-01-01T00:00:00.000Z |
| 9 | 1988-01-01T00:00:00.000Z |
| 13 | 1989-01-01T00:00:00.000Z |
| 12 | 1990-01-01T00:00:00.000Z |
| 6 | 1991-01-01T00:00:00.000Z |
| 8 | 1992-01-01T00:00:00.000Z |
| 3 | 1993-01-01T00:00:00.000Z |
| 4 | 1994-01-01T00:00:00.000Z |
| 5 | 1995-01-01T00:00:00.000Z |
| 1 | 1996-01-01T00:00:00.000Z |
| 1 | 1997-01-01T00:00:00.000Z |
| 1 | 1999-01-01T00:00:00.000Z |
または、時間ごとのエラーレート:
Esql
FROM sample_data| EVAL error = CASE(message LIKE "*error*", 1, 0)| EVAL hour = DATE_TRUNC(1 hour, @timestamp)| STATS error_rate = AVG(error) by hour| SORT hour
| error_rate:double | hour:date |
|---|---|
| 0.0 | 2023-10-23T12:00:00.000Z |
| 0.6 | 2023-10-23T13:00:00.000Z |
NOW
構文

パラメータ
説明
現在の日付と時刻を返します。
サポートされる型
| result |
|---|
| date |
例
Esql
ROW current_date = NOW()
| y:keyword |
|---|
| 20 |
最後の1時間のログを取得するには:
Esql
FROM sample_data| WHERE @timestamp > NOW() - 1 hour
| @timestamp:date | client_ip:ip | event_duration:long | message:keyword |
|---|---|---|---|
ES|QL IP functions
ES|QLは次のIP関数をサポートしています:
CIDR_MATCH
構文

パラメータ
ipip型のIPアドレス(IPv4とIPv6の両方がサポートされています)。blockX- IPをテストするCIDRブロック。
説明
提供されたIPが提供されたCIDRブロックのいずれかに含まれている場合はtrueを返します。
サポートされる型
| ip | blockX | result |
|---|---|---|
| ip | keyword | boolean |
| ip | text | boolean |
例
Esql
FROM hosts| WHERE CIDR_MATCH(ip1, "127.0.0.2/32", "127.0.0.3/32")| KEEP card, host, ip0, ip1
| card:keyword | host:keyword | ip0:ip | ip1:ip |
|---|---|---|---|
| eth1 | beta | 127.0.0.1 | 127.0.0.2 |
| eth0 | gamma | fe80::cae2:65ff:fece:feb9 | 127.0.0.3 |
IP_PREFIX
構文

パラメータ
ipip型のIPアドレス(IPv4とIPv6の両方がサポートされています)。prefixLengthV4- IPv4アドレスのプレフィックス長。
prefixLengthV6- IPv6アドレスのプレフィックス長。
説明
指定されたプレフィックス長にIPを切り捨てます。
サポートされる型
| ip | prefixLengthV4 | prefixLengthV6 | result |
|---|---|---|---|
| ip | integer | integer | ip |
例
Esql
row ip4 = to_ip("1.2.3.4"), ip6 = to_ip("fe80::cae2:65ff:fece:feb9")| eval ip4_prefix = ip_prefix(ip4, 24, 0), ip6_prefix = ip_prefix(ip6, 0, 112);
| ip4:ip | ip6:ip | ip4_prefix:ip | ip6_prefix:ip |
|---|---|---|---|
| 1.2.3.4 | fe80::cae2:65ff:fece:feb9 | 1.2.3.0 | fe80::cae2:65ff:fece:0000 |
ES|QL mathematical functions
ES|QLは次の数学関数をサポートしています:
ABSACOSASINATANATAN2CBRTCEILCOSCOSHEFLOORLOGLOG10PIPOWROUNDSIGNUMSINSINHSQRTTANTANHTAU
ABS
構文

パラメータ
number- 数値式。
nullの場合、関数はnullを返します。
説明
絶対値を返します。
サポートされる型
| number | result |
|---|---|
| double | double |
| integer | integer |
| long | long |
| unsigned_long | unsigned_long |
例
Esql
ROW number = -1.0| EVAL abs_number = ABS(number)
| number:double | abs_number:double |
|---|---|
| -1.0 | 1.0 |
Esql
FROM employees| KEEP first_name, last_name, height| EVAL abs_height = ABS(0.0 - height)
| first_name:keyword | last_name:keyword | height:double | abs_height:double |
|---|---|---|---|
| Alejandro | McAlpine | 1.48 | 1.48 |
| Amabile | Gomatam | 2.09 | 2.09 |
| Anneke | Preusig | 1.56 | 1.56 |
ACOS
構文

パラメータ
number- -1から1の間の数値。
nullの場合、関数はnullを返します。
説明
**サポートされる型**| number | result || :-- | :-- || double | double || integer | double || long | double || unsigned\_long | double |**例**#### Esql``````esqlROW a=.9| EVAL acos=ACOS(a)`
| a:double | acos:double |
|---|---|
| .9 | 0.45102681179626236 |
ASIN
構文

パラメータ
number- -1から1の間の数値。
nullの場合、関数はnullを返します。
説明
入力数値式の逆正弦をラジアンで表した角度として返します。
サポートされる型
| number | result |
|---|---|
| double | double |
| integer | double |
| long | double |
| unsigned_long | double |
例
Esql
ROW a=.9| EVAL asin=ASIN(a)
| a:double | asin:double |
|---|---|
| .9 | 1.1197695149986342 |
ATAN
構文

パラメータ
number- 数値式。
nullの場合、関数はnullを返します。
説明
入力数値式の逆正接をラジアンで表した角度として返します。
サポートされる型
| number | result |
|---|---|
| double | double |
| integer | double |
| long | double |
| unsigned_long | double |
例
Esql
ROW a=12.9| EVAL atan=ATAN(a)
| a:double | atan:double |
|---|---|
| 12.9 | 1.4934316673669235 |
ATAN2
構文

パラメータ
y_coordinate- y座標。
nullの場合、関数はnullを返します。 x_coordinate- x座標。
nullの場合、関数はnullを返します。
説明
正のx軸と原点から点(x, y)への線分との間の角度をラジアンで表します。
サポートされる型
| y_coordinate | x_coordinate | result |
|---|---|---|
| double | double | double |
| double | integer | double |
| double | long | double |
| double | unsigned_long | double |
| integer | double | double |
| integer | integer | double |
| integer | long | double |
| integer | unsigned_long | double |
| long | double | double |
| long | integer | double |
| long | long | double |
| long | unsigned_long | double |
| unsigned_long | double | double |
| unsigned_long | integer | double |
| unsigned_long | long | double |
| unsigned_long | unsigned_long | double |
例
Esql
ROW y=12.9, x=.6| EVAL atan2=ATAN2(y, x)
| y:double | x:double | atan2:double |
|---|---|---|
| 12.9 | 0.6 | 1.5243181954438936 |
CBRT
構文

パラメータ
number- 数値式。
nullの場合、関数はnullを返します。
説明
数値の立方根を返します。入力は任意の数値で、返り値は常にdoubleです。無限の立方根はnullです。
サポートされる型
| number | result |
|---|---|
| double | double |
| integer | double |
| long | double |
| unsigned_long | double |
例
Esql
ROW d = 1000.0| EVAL c = cbrt(d)
| d: double | c:double |
|---|---|
| 1000.0 | 10.0 |
CEIL
構文

パラメータ
number- 数値式。
nullの場合、関数はnullを返します。
説明
最も近い整数に数値を切り上げます。
これはlong(符号なしを含む)およびintegerに対しては何もしません。doubleの場合、これはMath.ceilに似て、整数に最も近いdouble値を選択します。
サポートされる型
| number | result |
|---|---|
| double | double |
| integer | integer |
| long | long |
| unsigned_long | unsigned_long |
例
Esql
ROW a=1.8| EVAL a=CEIL(a)
| a:double |
|---|
| 2 |
COS
構文

パラメータ
angle- ラジアンでの角度。
nullの場合、関数はnullを返します。
説明
角度のコサインを返します。
サポートされる型
| angle | result |
|---|---|
| double | double |
| integer | double |
| long | double |
| unsigned_long | double |
例
Esql
ROW a=1.8| EVAL cos=COS(a)
| a:double | cos:double |
|---|---|
| 1.8 | -0.2272020946930871 |
COSH
構文

パラメータ
angle- ラジアンでの角度。
nullの場合、関数はnullを返します。
説明
角度の双曲線コサインを返します。
サポートされる型
| angle | result |
|---|---|
| double | double |
| integer | double |
| long | double |
| unsigned_long | double |
例
Esql
ROW a=1.8| EVAL cosh=COSH(a)
| a:double | cosh:double |
|---|---|
| 1.8 | 3.1074731763172667 |
E
構文

パラメータ
説明
https://en.wikipedia.org/wiki/E_(mathematical_constantを返します。
サポートされる型
| result |
|---|
| double |
例
Esql
ROW E()
| E():double |
|---|
| 2.718281828459045 |
FLOOR
構文

パラメータ
number- 数値式。
nullの場合、関数はnullを返します。
説明
最も近い整数に数値を切り捨てます。
これはlong(符号なしを含む)およびintegerに対しては何もしません。doubleの場合、これはMath.floorに似て、整数に最も近いdouble値を選択します。
サポートされる型
| number | result |
|---|---|
| double | double |
| integer | integer |
| long | long |
| unsigned_long | unsigned_long |
例
Esql
ROW a=1.8| EVAL a=FLOOR(a)
| a:double |
|---|
| 1 |
LOG
構文

パラメータ
base- 対数の底。
nullの場合、関数はnullを返します。指定されていない場合、この関数は値の自然対数(底e)を返します。 number- 数値式。
nullの場合、関数はnullを返します。
説明
指定された底の値の対数を返します。入力は任意の数値で、返り値は常にdoubleです。ゼロ、負の数、および底が1の対数はnullを返し、警告も表示されます。
サポートされる型
| base | number | result |
|---|---|---|
| double | double | double |
| double | integer | double |
| double | long | double |
| double | unsigned_long | double |
| double | double | |
| integer | double | double |
| integer | integer | double |
| integer | long | double |
| integer | unsigned_long | double |
| integer | double | |
| long | double | double |
| long | integer | double |
| long | long | double |
| long | unsigned_long | double |
| long | double | |
| unsigned_long | double | double |
| unsigned_long | integer | double |
| unsigned_long | long | double |
| unsigned_long | unsigned_long | double |
| unsigned_long | double |
例
Esql
ROW base = 2.0, value = 8.0| EVAL s = LOG(base, value)
| base: double | value: double | s:double |
|---|---|---|
| 2.0 | 8.0 | 3.0 |
Esql
row value = 100| EVAL s = LOG(value);
| value: integer | s:double |
|---|---|
| 100 | 4.605170185988092 |
LOG10
構文

パラメータ
number- 数値式。
nullの場合、関数はnullを返します。
説明
値の底10の対数を返します。入力は任意の数値で、返り値は常にdoubleです。0および負の数の対数はnullを返し、警告も表示されます。
サポートされる型
| number | result |
|---|---|
| double | double |
| integer | double |
| long | double |
| unsigned_long | double |
例
Esql
ROW d = 1000.0| EVAL s = LOG10(d)
| d: double | s:double |
|---|---|
| 1000.0 | 3.0 |
PI
構文

パラメータ
説明
円周と直径の比率である Pi を返します。
サポートされる型
| result |
|---|
| double |
例
Esql
ROW PI()
| PI():double |
|---|
| 3.141592653589793 |
POW
構文

パラメータ
base- 基数の数値式。もし
nullの場合、関数はnullを返します。 exponent- 指数の数値式。もし
nullの場合、関数はnullを返します。
説明
base の値を exponent の累乗にしたものを返します。
ここでダブル結果がオーバーフローする可能性があります。その場合、null が返されます。
サポートされる型
| base | exponent | result |
|---|---|---|
| double | double | double |
| double | integer | double |
| double | long | double |
| double | unsigned_long | double |
| integer | double | double |
| integer | integer | double |
| integer | long | double |
| integer | unsigned_long | double |
| long | double | double |
| long | integer | double |
| long | long | double |
| long | unsigned_long | double |
| unsigned_long | double | double |
| unsigned_long | integer | double |
| unsigned_long | long | double |
| unsigned_long | unsigned_long | double |
例
Esql
ROW base = 2.0, exponent = 2| EVAL result = POW(base, exponent)
| base:double | exponent:integer | result:double |
|---|---|---|
| 2.0 | 2 | 4.0 |
指数は分数であることができ、これは根を計算するのと似ています。例えば、0.5 の指数は基数の平方根を与えます:
Esql
ROW base = 4, exponent = 0.5| EVAL s = POW(base, exponent)
| base:integer | exponent:double | s:double |
|---|---|---|
| 4 | 0.5 | 2.0 |
ROUND
構文

パラメータ
number- 丸める数値。もし
nullの場合、関数はnullを返します。 decimals- 丸める小数点以下の桁数。デフォルトは 0 です。もし
nullの場合、関数はnullを返します。
説明
指定された小数点以下の桁数に数値を丸めます。デフォルトは 0 で、最も近い整数を返します。精度が負の数の場合、小数点の左側の桁数に丸めます。
サポートされる型
| number | decimals | result |
|---|---|---|
| double | integer | double |
| double | double | |
| integer | integer | integer |
| integer | integer | |
| long | integer | long |
| long | long | |
| unsigned_long | unsigned_long |
例
Esql
FROM employees| KEEP first_name, last_name, height| EVAL height_ft = ROUND(height * 3.281, 1)
| first_name:keyword | last_name:keyword | height:double | height_ft:double |
|---|---|---|---|
| Arumugam | Ossenbruggen | 2.1 | 6.9 |
| Kwee | Schusler | 2.1 | 6.9 |
| Saniya | Kalloufi | 2.1 | 6.9 |
SIGNUM
構文

パラメータ
number- 数値式。
nullの場合、関数はnullを返します。
説明
与えられた数の符号を返します。負の数の場合は -1 を、ゼロの場合は 0 を、正の数の場合は 1 を返します。
サポートされる型
| number | result |
|---|---|
| double | double |
| integer | double |
| long | double |
| unsigned_long | double |
例
Esql
ROW d = 100.0| EVAL s = SIGNUM(d)
| d: double | s:double |
|---|---|
| 100 | 1.0 |
SIN
構文

パラメータ
angle- ラジアンでの角度。
nullの場合、関数はnullを返します。
説明
角度の サイン 三角関数を返します。
サポートされる型
| angle | result |
|---|---|
| double | double |
| integer | double |
| long | double |
| unsigned_long | double |
例
Esql
ROW a=1.8| EVAL sin=SIN(a)
| a:double | sin:double |
|---|---|
| 1.8 | 0.9738476308781951 |
SINH
構文

パラメータ
angle- ラジアンでの角度。
nullの場合、関数はnullを返します。
説明
角度の 双曲線サイン を返します。
サポートされる型
| angle | result |
|---|---|
| double | double |
| integer | double |
| long | double |
| unsigned_long | double |
例
Esql
ROW a=1.8| EVAL sinh=SINH(a)
| a:double | sinh:double |
|---|---|
| 1.8 | 2.94217428809568 |
SQRT
構文

パラメータ
number- 数値式。
nullの場合、関数はnullを返します。
説明
数の平方根を返します。入力は任意の数値で、返り値は常にダブルです。負の数や無限大の平方根は null です。
サポートされる型
| number | result |
|---|---|
| double | double |
| integer | double |
| long | double |
| unsigned_long | double |
例
Esql
ROW d = 100.0| EVAL s = SQRT(d)
| d: double | s:double |
|---|---|
| 100.0 | 10.0 |
TAN
構文

パラメータ
angle- ラジアンでの角度。
nullの場合、関数はnullを返します。
説明
角度の タンジェント 三角関数を返します。
サポートされる型
| angle | result |
|---|---|
| double | double |
| integer | double |
| long | double |
| unsigned_long | double |
例
Esql
ROW a=1.8| EVAL tan=TAN(a)
| a:double | tan:double |
|---|---|
| 1.8 | -4.286261674628062 |
TANH
構文

パラメータ
angle- ラジアンでの角度。
nullの場合、関数はnullを返します。
説明
角度の 双曲線タンジェント を返します。
サポートされる型
| angle | result |
|---|---|
| double | double |
| integer | double |
| long | double |
| unsigned_long | double |
例
Esql
ROW a=1.8| EVAL tanh=TANH(a)
| a:double | tanh:double |
|---|---|
| 1.8 | 0.9468060128462683 |
TAU
構文

パラメータ
説明
円周と半径の 比率 を返します。
サポートされる型
| result |
|---|
| double |
例
Esql
ROW TAU()
| TAU():double |
|---|
| 6.283185307179586 |
ES|QL spatial functions
ES|QL はこれらの空間関数をサポートしています:
- [プレビュー] この機能は技術プレビュー中であり、将来のリリースで変更または削除される可能性があります。Elasticは問題を修正するために取り組みますが、技術プレビューの機能は公式GA機能のサポートSLAの対象ではありません。
ST_INTERSECTS - [プレビュー] この機能は技術プレビュー中であり、将来のリリースで変更または削除される可能性があります。Elasticは問題を修正するために取り組みますが、技術プレビューの機能は公式GA機能のサポートSLAの対象ではありません。
ST_DISJOINT - [プレビュー] この機能は技術プレビュー中であり、将来のリリースで変更または削除される可能性があります。Elasticは問題を修正するために取り組みますが、技術プレビューの機能は公式GA機能のサポートSLAの対象ではありません。
ST_CONTAINS - [プレビュー] この機能は技術プレビュー中であり、将来のリリースで変更または削除される可能性があります。Elasticは問題を修正するために取り組みますが、技術プレビューの機能は公式GA機能のサポートSLAの対象ではありません。
ST_WITHIN - [プレビュー] この機能は技術プレビュー中であり、将来のリリースで変更または削除される可能性があります。Elastic は問題を修正するために取り組みますが、技術プレビューの機能は公式 GA 機能のサポート SLA の対象外です。
ST_X - [プレビュー] この機能は技術プレビュー中であり、将来のリリースで変更または削除される可能性があります。Elastic は問題を修正するために取り組みますが、技術プレビューの機能は公式 GA 機能のサポート SLA の対象外です。
ST_Y - [プレビュー] この機能は技術プレビュー中であり、将来のリリースで変更または削除される可能性があります。Elasticは問題を修正するために取り組みますが、技術プレビューの機能は公式GA機能のサポートSLAの対象ではありません。
ST_DISTANCE
ST_INTERSECTS
構文

パラメータ
geomAgeo_point、cartesian_point、geo_shape、またはcartesian_shapeの型の式。もしnullの場合、関数はnullを返します。geomBgeo_point、cartesian_point、geo_shape、またはcartesian_shapeの型の式。もしnullの場合、関数はnullを返します。第二のパラメータは第一のものと同じ座標系を持つ必要があります。これはgeo_*とcartesian_*のパラメータを組み合わせることができないことを意味します。
説明
二つのジオメトリが交差する場合は true を返します。交差するとは、共通の点がある場合、内部点(線上の点や多角形内の点を含む)を含みます。これは ST_DISJOINT 関数の逆です。数学的には: ST_Intersects(A, B) ⇔ A ⋂ B ≠ ∅
サポートされる型
| geomA | geomB | result |
|---|---|---|
| cartesian_point | cartesian_point | boolean |
| cartesian_point | cartesian_shape | boolean |
| cartesian_shape | cartesian_point | boolean |
| cartesian_shape | cartesian_shape | boolean |
| geo_point | geo_point | boolean |
| geo_point | geo_shape | boolean |
| geo_shape | geo_point | boolean |
| geo_shape | geo_shape | boolean |
例
Esql
FROM airports| WHERE ST_INTERSECTS(location, TO_GEOSHAPE("POLYGON((42 14, 43 14, 43 15, 42 15, 42 14))"))
| abbrev:keyword | city:keyword | city_location:geo_point | country:keyword | location:geo_point | name:text | scalerank:i | type:k |
|---|---|---|---|---|---|---|---|
| HOD | Al Ḩudaydah | POINT(42.9511 14.8022) | Yemen | POINT(42.97109630194 14.7552534413725) | Hodeidah Int’l | 9 | mid |
ST_DISJOINT
構文

パラメータ
geomAgeo_point、cartesian_point、geo_shape、またはcartesian_shapeの型の式。もしnullの場合、関数はnullを返します。geomBgeo_point、cartesian_point、geo_shape、またはcartesian_shapeの型の式。もしnullの場合、関数はnullを返します。第二のパラメータは第一のものと同じ座標系を持つ必要があります。これはgeo_*とcartesian_*のパラメータを組み合わせることができないことを意味します。
説明
二つのジオメトリまたはジオメトリ列が離れているかどうかを返します。これは ST_INTERSECTS 関数の逆です。数学的には: ST_Disjoint(A, B) ⇔ A ⋂ B = ∅
サポートされる型
| geomA | geomB | result |
|---|---|---|
| cartesian_point | cartesian_point | boolean |
| cartesian_point | cartesian_shape | boolean |
| cartesian_shape | cartesian_point | boolean |
| cartesian_shape | cartesian_shape | boolean |
| geo_point | geo_point | boolean |
| geo_point | geo_shape | boolean |
| geo_shape | geo_point | boolean |
| geo_shape | geo_shape | boolean |
例
Esql
FROM airport_city_boundaries| WHERE ST_DISJOINT(city_boundary, TO_GEOSHAPE("POLYGON((-10 -60, 120 -60, 120 60, -10 60, -10 -60))"))| KEEP abbrev, airport, region, city, city_location
| abbrev:keyword | airport:text | region:text | city:keyword | city_location:geo_point |
|---|---|---|---|---|
| ACA | General Juan N Alvarez Int’l | Acapulco de Juárez | Acapulco de Juárez | POINT (-99.8825 16.8636) |
ST_CONTAINS
構文

パラメータ
geomAgeo_point、cartesian_point、geo_shape、またはcartesian_shapeの型の式。もしnullの場合、関数はnullを返します。geomBgeo_point、cartesian_point、geo_shape、またはcartesian_shapeの型の式。もしnullの場合、関数はnullを返します。第二のパラメータは第一のものと同じ座標系を持つ必要があります。これはgeo_*とcartesian_*のパラメータを組み合わせることができないことを意味します。
説明
第一のジオメトリが第二のジオメトリを含むかどうかを返します。これは ST_WITHIN 関数の逆です。
サポートされる型
| geomA | geomB | result |
|---|---|---|
| cartesian_point | cartesian_point | boolean |
| cartesian_point | cartesian_shape | boolean |
| cartesian_shape | cartesian_point | boolean |
| cartesian_shape | cartesian_shape | boolean |
| geo_point | geo_point | boolean |
| geo_point | geo_shape | boolean |
| geo_shape | geo_point | boolean |
| geo_shape | geo_shape | boolean |
例
Esql
FROM airport_city_boundaries| WHERE ST_CONTAINS(city_boundary, TO_GEOSHAPE("POLYGON((109.35 18.3, 109.45 18.3, 109.45 18.4, 109.35 18.4, 109.35 18.3))"))| KEEP abbrev, airport, region, city, city_location
| abbrev:keyword | airport:text | region:text | city:keyword | city_location:geo_point |
|---|---|---|---|---|
| SYX | Sanya Phoenix Int’l | 天涯区 | Sanya | POINT(109.5036 18.2533) |
ST_WITHIN
構文

パラメータ
geomAgeo_point、cartesian_point、geo_shape、またはcartesian_shapeの型の式。もしnullの場合、関数はnullを返します。geomBgeo_point、cartesian_point、geo_shape、またはcartesian_shapeの型の式。もしnullの場合、関数はnullを返します。第二のパラメータは第一のものと同じ座標系を持つ必要があります。これはgeo_*とcartesian_*のパラメータを組み合わせることができないことを意味します。
説明
第一のジオメトリが第二のジオメトリの中にあるかどうかを返します。これは ST_CONTAINS 関数の逆です。
サポートされる型
| geomA | geomB | result |
|---|---|---|
| cartesian_point | cartesian_point | boolean |
| cartesian_point | cartesian_shape | boolean |
| cartesian_shape | cartesian_point | boolean |
| cartesian_shape | cartesian_shape | boolean |
| geo_point | geo_point | boolean |
| geo_point | geo_shape | boolean |
| geo_shape | geo_point | boolean |
| geo_shape | geo_shape | boolean |
例
Esql
FROM airport_city_boundaries| WHERE ST_WITHIN(city_boundary, TO_GEOSHAPE("POLYGON((109.1 18.15, 109.6 18.15, 109.6 18.65, 109.1 18.65, 109.1 18.15))"))| KEEP abbrev, airport, region, city, city_location
| abbrev:keyword | airport:text | region:text | city:keyword | city_location:geo_point |
|---|---|---|---|---|
| SYX | Sanya Phoenix Int’l | 天涯区 | Sanya | POINT(109.5036 18.2533) |
ST_X
構文

パラメータ
pointgeo_pointまたはcartesian_pointの型の式。もしnullの場合、関数はnullを返します。
説明
提供された点から x 座標を抽出します。点が geo_point 型の場合、これは longitude 値を抽出することに相当します。
サポートされる型
| point | result |
|---|---|
| cartesian_point | double |
| geo_point | double |
例
Esql
ROW point = TO_GEOPOINT("POINT(42.97109629958868 14.7552534006536)")| EVAL x = ST_X(point), y = ST_Y(point)
| point:geo_point | x:double | y:double |
|---|---|---|
| POINT(42.97109629958868 14.7552534006536) | 42.97109629958868 | 14.7552534006536 |
ST_Y
構文

パラメータ
pointgeo_pointまたはcartesian_pointの型の式。もしnullの場合、関数はnullを返します。
説明
提供された点から y 座標を抽出します。点が geo_point 型の場合、これは latitude 値を抽出することに相当します。
サポートされる型
| point | result |
|---|---|
| cartesian_point | double |
| geo_point | double |
例
Esql
ROW point = TO_GEOPOINT("POINT(42.97109629958868 14.7552534006536)")| EVAL x = ST_X(point), y = ST_Y(point)
| point:geo_point | x:double | y:double |
|---|---|---|
| POINT(42.97109629958868 14.7552534006536) | 42.97109629958868 | 14.7552534006536 |
ST_DISTANCE
構文

パラメータ
geomAgeo_pointまたはcartesian_pointの型の式。もしnullの場合、関数はnullを返します。geomBgeo_pointまたはcartesian_pointの型の式。もしnullの場合、関数はnullを返します。第二のパラメータは第一のものと同じ座標系を持つ必要があります。これはgeo_pointとcartesian_pointのパラメータを組み合わせることができないことを意味します。
説明
二つの点の間の距離を計算します。直交ジオメトリの場合、これは元の座標と同じ単位でのピタゴラス距離です。地理的ジオメトリの場合、これはメートル単位の大円に沿った円距離です。
サポートされる型
| geomA | geomB | result |
|---|---|---|
| cartesian_point | cartesian_point | double |
| geo_point | geo_point | double |
例
Esql
FROM airports| WHERE abbrev == "CPH"| EVAL distance = ST_DISTANCE(location, city_location)| KEEP abbrev, name, location, city_location, distance
| abbrev:k | name:text | location:geo_point | city_location:geo_point | distance:d |
|---|---|---|---|---|
| CPH | Copenhagen | POINT(12.6493508684508 55.6285017221528) | POINT(12.5683 55.6761) | 7339.573896618216 |
ES|QL string functions
ES|QL はこれらの文字列関数をサポートしています:
CONCATENDS_WITHFROM_BASE64LEFTLENGTHLOCATELTRIMREPEATREPLACERIGHTRTRIMSPLITSTARTS_WITHSUBSTRINGTO_BASE64TO_LOWERTO_UPPERTRIM
CONCAT
構文

パラメータ
string1- 連結する文字列。
string2- 連結する文字列。
説明
二つ以上の文字列を連結します。
サポートされる型
| string1 | string2 | result |
|---|---|---|
| keyword | keyword | keyword |
| keyword | text | keyword |
| text | keyword | keyword |
| text | text | keyword |
例
Esql
FROM employees| KEEP first_name, last_name| EVAL fullname = CONCAT(first_name, " ", last_name)
| first_name:keyword | last_name:keyword | fullname:keyword |
|---|---|---|
| Alejandro | McAlpine | Alejandro McAlpine |
| Amabile | Gomatam | Amabile Gomatam |
| Anneke | Preusig | Anneke Preusig |
ENDS_WITH
構文

パラメータ
str- 文字列式。もし
nullの場合、関数はnullを返します。 suffix- 文字列式。もし
nullの場合、関数はnullを返します。
説明
キーワード文字列が別の文字列で終わるかどうかを示すブール値を返します。
サポートされる型
| str | suffix | result |
|---|---|---|
| keyword | keyword | boolean |
| text | text | boolean |
例
Esql
FROM employees| KEEP last_name| EVAL ln_E = ENDS_WITH(last_name, "d")
| last_name:keyword | ln_E:boolean |
|---|---|
| Awdeh | false |
| Azuma | false |
| Baek | false |
| Bamford | true |
| Bernatsky | false |
FROM_BASE64
構文

パラメータ
string- base64 文字列。
説明
base64 文字列をデコードします。
サポートされる型
| string | result |
|---|---|
| keyword | keyword |
| text | keyword |
例
Esql
row a = "ZWxhc3RpYw=="| eval d = from_base64(a)
| a:keyword | d:keyword |
|---|---|
| ZWxhc3RpYw== | elastic |
LEFT
構文

パラメータ
string- サブストリングを返す元の文字列。
length- 返す文字数。
説明
左から length 文字を string から抽出するサブストリングを返します。
サポートされる型
| string | length | result |
|---|---|---|
| keyword | integer | keyword |
| text | integer | keyword |
例
Esql
FROM employees| KEEP last_name| EVAL left = LEFT(last_name, 3)| SORT last_name ASC| LIMIT 5
| last_name:keyword | left:keyword |
|---|---|
| Awdeh | Awd |
| Azuma | Azu |
| Baek | Bae |
| Bamford | Bam |
| Bernatsky | Ber |
LENGTH
構文

パラメータ
string- 文字列式。もし
nullの場合、関数はnullを返します。
説明
文字列の文字数を返します。
サポートされる型
| string | result |
|---|---|
| keyword | integer |
| text | integer |
例
Esql
FROM employees| KEEP first_name, last_name| EVAL fn_length = LENGTH(first_name)
| first_name:keyword | last_name:keyword | fn_length:integer |
|---|---|---|
| Alejandro | McAlpine | 9 |
| Amabile | Gomatam | 7 |
| Anneke | Preusig | 6 |
LOCATE
構文

パラメータ
string- 入力文字列
substring- 入力文字列内で位置を特定するサブストリング
start- 開始インデックス
説明
キーワードサブストリングが別の文字列内の位置を示す整数を返します。サブストリングが見つからない場合は 0 を返します。文字列の位置は 1 から始まることに注意してください。
サポートされる型
| string | substring | start | result |
|---|---|---|---|
| keyword | keyword | integer | integer |
| keyword | keyword | integer | |
| keyword | text | integer | integer |
| keyword | text | integer | |
| text | keyword | integer | integer |
| text | keyword | integer | |
| text | text | integer | integer |
| text | text | integer |
例
Esql
row a = "hello"| eval a_ll = locate(a, "ll")
| a:keyword | a_ll:integer |
|---|---|
| hello | 3 |
LTRIM
構文

パラメータ
string- 文字列式。もし
nullの場合、関数はnullを返します。
説明
文字列の先頭の空白を削除します。
サポートされる型
| string | result |
|---|---|
| keyword | keyword |
| text | text |
例
Esql
ROW message = " some text ", color = " red "| EVAL message = LTRIM(message)| EVAL color = LTRIM(color)| EVAL message = CONCAT("'", message, "'")| EVAL color = CONCAT("'", color, "'")
| message:keyword | color:keyword |
|---|---|
| ‘some text ‘ | ‘red ‘ |
REPEAT
構文

パラメータ
string- 文字列式。
number- 繰り返す回数。
説明
指定された number 回数だけ string を自身と連結して構成された文字列を返します。
サポートされる型
| string | number | result |
|---|---|---|
| keyword | integer | keyword |
| text | integer | keyword |
例
Esql
ROW a = "Hello!"| EVAL triple_a = REPEAT(a, 3);
| a:keyword | triple_a:keyword |
|---|---|
| Hello! | Hello!Hello!Hello! |
REPLACE
構文

パラメータ
string- 文字列式。
regex- 正規表現。
newString- 置換文字列。
説明
この関数は、文字列 str の中で、正規表現 regex に一致する部分を置換文字列 newStr で置き換えます。
サポートされる型
| 文字列 | 正規表現 | 新しい文字列 | 結果 |
|---|---|---|---|
| キーワード | キーワード | キーワード | キーワード |
| キーワード | キーワード | テキスト | キーワード |
| キーワード | テキスト | キーワード | キーワード |
| キーワード | テキスト | テキスト | キーワード |
| テキスト | キーワード | キーワード | キーワード |
| テキスト | キーワード | テキスト | キーワード |
| テキスト | テキスト | キーワード | キーワード |
| テキスト | テキスト | テキスト | キーワード |
例
この例では、単語「World」のすべての出現を単語「Universe」に置き換えます:
Esql
ROW str = "Hello World"| EVAL str = REPLACE(str, "World", "Universe")| KEEP str
| str:keyword |
|---|
| こんにちは宇宙 |
RIGHT
構文

パラメータ
string- サブストリングを返す元の文字列。
length- 返す文字数。
説明
右から str から length 文字を抽出するサブストリングを返します。
サポートされる型
| string | length | result |
|---|---|---|
| keyword | integer | keyword |
| text | integer | keyword |
例
Esql
FROM employees| KEEP last_name| EVAL right = RIGHT(last_name, 3)| SORT last_name ASC| LIMIT 5
| last_name:keyword | right:keyword |
|---|---|
| Awdeh | deh |
| Azuma | uma |
| Baek | aek |
| Bamford | ord |
| Bernatsky | sky |
RTRIM
構文

パラメータ
string- 文字列式。もし
nullの場合、関数はnullを返します。
説明
文字列の末尾の空白を削除します。
サポートされる型
| string | result |
|---|---|
| keyword | keyword |
| text | text |
例
Esql
ROW message = " some text ", color = " red "| EVAL message = RTRIM(message)| EVAL color = RTRIM(color)| EVAL message = CONCAT("'", message, "'")| EVAL color = CONCAT("'", color, "'")
| message:keyword | color:keyword |
|---|---|
| ‘some text ‘ | ‘red ‘ |
SPLIT
構文

パラメータ
string- 文字列式。もし
nullの場合、関数はnullを返します。 delim- デリミタ。現在は単一バイトのデリミタのみがサポートされています。
説明
単一の値を持つ文字列を複数の文字列に分割します。
サポートされる型
| 文字列 | デリミタ | 結果 |
|---|---|---|
| keyword | keyword | keyword |
| keyword | text | keyword |
| text | keyword | keyword |
| text | text | keyword |
例
Esql
ROW words="foo;bar;baz;qux;quux;corge"| EVAL word = SPLIT(words, ";")
| words:keyword | word:keyword |
|---|---|
| foo;bar;baz;qux;quux;corge | [foo,bar,baz,qux,quux,corge] |
STARTS_WITH
構文

パラメータ
str- 文字列式。もし
nullの場合、関数はnullを返します。 prefix- 文字列式。もし
nullの場合、関数はnullを返します。
説明
キーワード文字列が別の文字列で始まるかどうかを示すブール値を返します。
サポートされる型
| str | prefix | result |
|---|---|---|
| keyword | keyword | boolean |
| text | text | boolean |
例
Esql
FROM employees| KEEP last_name| EVAL ln_S = STARTS_WITH(last_name, "B")
| last_name:keyword | ln_S:boolean |
|---|---|
| Awdeh | false |
| Azuma | false |
| Baek | true |
| Bamford | true |
| Bernatsky | true |
SUBSTRING
構文

パラメータ
string- 文字列式。もし
nullの場合、関数はnullを返します。 start- 開始位置。
length- 開始位置からのサブストリングの長さ。オプション; 省略した場合、
startの後のすべての位置が返されます。
説明
文字列のサブストリングを返します。開始位置とオプションの長さで指定されます。
サポートされる型
| 文字列 | 開始 | 長さ | 結果 |
|---|---|---|---|
| キーワード | 整数 | 整数 | キーワード |
| テキスト | 整数 | 整数 | キーワード |
例
この例では、すべての姓の最初の3文字を返します:
Esql
FROM employees| KEEP last_name| EVAL ln_sub = SUBSTRING(last_name, 1, 3)
| last_name:keyword | ln_sub:keyword |
|---|---|
| Awdeh | Awd |
| Azuma | Azu |
| Baek | Bae |
| Bamford | Bam |
| Bernatsky | Ber |
負の開始位置は、文字列の末尾に対して相対的に解釈されます。この例では、すべての姓の最後の3文字を返します:
Esql
FROM employees| KEEP last_name| EVAL ln_sub = SUBSTRING(last_name, -3, 3)
| last_name:keyword | ln_sub:keyword |
|---|---|
| Awdeh | deh |
| Azuma | uma |
| Baek | aek |
| Bamford | ord |
| Bernatsky | sky |
長さが省略された場合、サブストリングは文字列の残りを返します。この例では、最初の文字を除くすべての文字を返します:
Esql
FROM employees| KEEP last_name| EVAL ln_sub = SUBSTRING(last_name, 2)
| last_name:keyword | ln_sub:keyword |
|---|---|
| Awdeh | wdeh |
| Azuma | zuma |
| Baek | aek |
| Bamford | amford |
| Bernatsky | ernatsky |
TO_BASE64
構文

パラメータ
string- 文字列。
説明
文字列をbase64文字列にエンコードします。
サポートされる型
| string | result |
|---|---|
| keyword | keyword |
| text | keyword |
例
Esql
row a = "elastic"| eval e = to_base64(a)
| a:keyword | e:keyword |
|---|---|
| elastic | ZWxhc3RpYw== |
TO_LOWER
構文

パラメータ
str- 文字列式。もし
nullの場合、関数はnullを返します。
説明
入力文字列を小文字に変換した新しい文字列を返します。
サポートされる型
| str | result |
|---|---|
| keyword | keyword |
| text | text |
例
Esql
ROW message = "Some Text"| EVAL message_lower = TO_LOWER(message)
| message:keyword | message_lower:keyword |
|---|---|
| 一部のテキスト | 一部のテキスト |
TO_UPPER
構文

パラメータ
str- 文字列式。もし
nullの場合、関数はnullを返します。
説明
入力文字列を大文字に変換した新しい文字列を返します。
サポートされる型
| str | result |
|---|---|
| keyword | keyword |
| text | text |
例
Esql
ROW message = "Some Text"| EVAL message_upper = TO_UPPER(message)
| message:keyword | message_upper:keyword |
|---|---|
| 一部のテキスト | 一部のテキスト |
TRIM
構文

パラメータ
string- 文字列式。もし
nullの場合、関数はnullを返します。
説明
文字列の先頭と末尾の空白を削除します。
サポートされる型
| string | result |
|---|---|
| keyword | keyword |
| text | text |
例
Esql
ROW message = " some text ", color = " red "| EVAL message = TRIM(message)| EVAL color = TRIM(color)
| message:s | color:s |
|---|---|
| 一部のテキスト | 赤 |
ES|QL type conversion functions
ES|QLは、文字列リテラルから特定のデータ型への暗黙のキャストをサポートしています。詳細については、暗黙のキャストを参照してください。
ES|QLは、次の型変換関数をサポートしています:
TO_BOOLEANTO_CARTESIANPOINTTO_CARTESIANSHAPETO_DATETIMETO_DEGREESTO_DOUBLETO_GEOPOINTTO_GEOSHAPETO_INTEGERTO_IPTO_LONGTO_RADIANSTO_STRING- [プレビュー] この機能は技術プレビュー中であり、将来のリリースで変更または削除される可能性があります。Elastic は問題を修正するために取り組みますが、技術プレビューの機能は公式 GA 機能のサポート SLA の対象外です。
TO_UNSIGNED_LONG TO_VERSION
TO_BOOLEAN
構文

パラメータ
field- 入力値。入力は単一または複数値の列または式であることができます。
説明
入力値をブール値に変換します。文字列値 true は、大文字小文字を区別せずにブール値 true に変換されます。それ以外のもの、空の文字列を含むものは、関数は false を返します。数値の 0 は false に変換され、それ以外は true に変換されます。
サポートされる型
| フィールド | 結果 |
|---|---|
| boolean | boolean |
| double | boolean |
| integer | boolean |
| keyword | boolean |
| long | boolean |
| text | boolean |
| unsigned_long | boolean |
例
Esql
ROW str = ["true", "TRuE", "false", "", "yes", "1"]| EVAL bool = TO_BOOLEAN(str)
| str:keyword | bool:boolean |
|---|---|
| [“true”, “TRuE”, “false”, “”, “yes”, “1”] | [true, true, false, false, false, false] |
TO_CARTESIANPOINT
構文

パラメータ
field- 入力値。入力は単一または複数値の列または式であることができます。
説明
入力値を cartesian_point 値に変換します。文字列は、WKT Point 形式を尊重する場合にのみ正常に変換されます。
サポートされる型
| フィールド | 結果 |
|---|---|
| cartesian_point | cartesian_point |
| keyword | cartesian_point |
| text | cartesian_point |
例
Esql
ROW wkt = ["POINT(4297.11 -1475.53)", "POINT(7580.93 2272.77)"]| MV_EXPAND wkt| EVAL pt = TO_CARTESIANPOINT(wkt)
| wkt:keyword | pt:cartesian_point |
|---|---|
| “POINT(4297.11 -1475.53)” | POINT(4297.11 -1475.53) |
| “POINT(7580.93 2272.77)” | POINT(7580.93 2272.77) |
TO_CARTESIANSHAPE
構文

パラメータ
field- 入力値。入力は単一または複数値の列または式であることができます。
説明
入力値を cartesian_shape 値に変換します。文字列は、WKT 形式を尊重する場合にのみ正常に変換されます。
サポートされる型
| フィールド | 結果 |
|---|---|
| cartesian_point | cartesian_shape |
| cartesian_shape | cartesian_shape |
| keyword | cartesian_shape |
| text | cartesian_shape |
例
Esql
ROW wkt = ["POINT(4297.11 -1475.53)", "POLYGON ((3339584.72 1118889.97, 4452779.63 4865942.27, 2226389.81 4865942.27, 1113194.90 2273030.92, 3339584.72 1118889.97))"]| MV_EXPAND wkt| EVAL geom = TO_CARTESIANSHAPE(wkt)
| wkt:keyword | geom:cartesian_shape |
|---|---|
| “POINT(4297.11 -1475.53)” | POINT(4297.11 -1475.53) |
| “POLYGON 3339584.72 1118889.97, 4452779.63 4865942.27, 2226389.81 4865942.27, 1113194.90 2273030.92, 3339584.72 1118889.97” | POLYGON 3339584.72 1118889.97, 4452779.63 4865942.27, 2226389.81 4865942.27, 1113194.90 2273030.92, 3339584.72 1118889.97 |
TO_DATETIME
構文

パラメータ
field- 入力値。入力は単一または複数値の列または式であることができます。
説明
入力値を日付値に変換します。文字列は、形式 yyyy-MM-dd'T'HH:mm:ss.SSS'Z' を尊重する場合にのみ正常に変換されます。他の形式の日付を変換するには、DATE_PARSE を使用します。
サポートされる型
| フィールド | 結果 |
|---|---|
| date | date |
| double | date |
| integer | date |
| keyword | date |
| long | date |
| text | date |
| unsigned_long | date |
例
Esql
ROW string = ["1953-09-02T00:00:00.000Z", "1964-06-02T00:00:00.000Z", "1964-06-02 00:00:00"]| EVAL datetime = TO_DATETIME(string)
| string:keyword | datetime:date |
|---|---|
| [“1953-09-02T00:00:00.000Z”, “1964-06-02T00:00:00.000Z”, “1964-06-02 00:00:00”] | [1953-09-02T00:00:00.000Z, 1964-06-02T00:00:00.000Z] |
この例では、ソースの複数値フィールドの最後の値は変換されていないことに注意してください。日付形式が尊重されない場合、変換は null 値になります。この場合、Warning ヘッダーが応答に追加されます。このヘッダーは、失敗の原因に関する情報を提供します:
"Line 1:112: evaluation of [TO_DATETIME(string)] failed, treating result as null. "Only first 20 failures recorded."
次のヘッダーには、失敗の理由と問題のある値が含まれます:
"java.lang.IllegalArgumentException: failed to parse date field [1964-06-02 00:00:00]
with format [yyyy-MM-dd'T'HH:mm:ss.SSS'Z']"
入力パラメータが数値型の場合、その値は Unix epoch からのミリ秒として解釈されます。例えば:
Esql
ROW int = [0, 1]| EVAL dt = TO_DATETIME(int)
| int:integer | dt:date |
|---|---|
| [0, 1] | [1970-01-01T00:00:00.000Z, 1970-01-01T00:00:00.001Z] |
TO_DEGREES
構文

パラメータ
number- 入力値。入力は単一または複数値の列または式であることができます。
説明
サポートされる型
| number | result |
|---|---|
| double | double |
| integer | double |
| long | double |
| unsigned_long | double |
例
Esql
ROW rad = [1.57, 3.14, 4.71]| EVAL deg = TO_DEGREES(rad)
| rad:double | deg:double |
|---|---|
| [1.57, 3.14, 4.71] | [89.95437383553924, 179.9087476710785, 269.86312150661774] |
TO_DOUBLE
構文

パラメータ
field- 入力値。入力は単一または複数値の列または式であることができます。
説明
入力値をダブル値に変換します。入力パラメータが日付型の場合、その値は Unix epoch からのミリ秒として解釈され、ダブルに変換されます。ブール値 true はダブル 1.0 に、false は 0.0 に変換されます。
サポートされる型
| フィールド | 結果 |
|---|---|
| boolean | double |
| counter_double | double |
| counter_integer | double |
| counter_long | double |
| date | double |
| double | double |
| integer | double |
| keyword | double |
| long | double |
| text | double |
| unsigned_long | double |
例
Esql
ROW str1 = "5.20128E11", str2 = "foo"| EVAL dbl = TO_DOUBLE("520128000000"), dbl1 = TO_DOUBLE(str1), dbl2 = TO_DOUBLE(str2)
| str1:keyword | str2:keyword | dbl:double | dbl1:double | dbl2:double |
|---|---|---|---|---|
| 5.20128E11 | foo | 5.20128E11 | 5.20128E11 | null |
この例では、文字列の最後の変換が不可能であることに注意してください。この場合、結果は null 値になります。この場合、Warning ヘッダーが応答に追加されます。このヘッダーは、失敗の原因に関する情報を提供します:
"Line 1:115: evaluation of [TO_DOUBLE(str2)] failed, treating result as null. Only first 20 failures recorded."
次のヘッダーには、失敗の理由と問題のある値が含まれます: "java.lang.NumberFormatException: For input string: "foo""
TO_GEOPOINT
構文

パラメータ
field- 入力値。入力は単一または複数値の列または式であることができます。
説明
入力値を geo_point 値に変換します。文字列は、WKT Point 形式を尊重する場合にのみ正常に変換されます。
サポートされる型
| フィールド | 結果 |
|---|---|
| geo_point | geo_point |
| keyword | geo_point |
| text | geo_point |
例
Esql
ROW wkt = "POINT(42.97109630194 14.7552534413725)"| EVAL pt = TO_GEOPOINT(wkt)
| wkt:keyword | pt:geo_point |
|---|---|
| “POINT(42.97109630194 14.7552534413725)” | POINT(42.97109630194 14.7552534413725) |
TO_GEOSHAPE
構文

パラメータ
field- 入力値。入力は単一または複数値の列または式であることができます。
説明
入力値を geo_shape 値に変換します。文字列は、WKT 形式を尊重する場合にのみ正常に変換されます。
サポートされる型
| フィールド | 結果 |
|---|---|
| geo_point | geo_shape |
| geo_shape | geo_shape |
| keyword | geo_shape |
| text | geo_shape |
例
Esql
ROW wkt = "POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))"| EVAL geom = TO_GEOSHAPE(wkt)
| wkt:keyword | geom:geo_shape |
|---|---|
| “POLYGON 30 10, 40 40, 20 40, 10 20, 30 10” | POLYGON 30 10, 40 40, 20 40, 10 20, 30 10 |
TO_INTEGER
構文

パラメータ
field- 入力値。入力は単一または複数値の列または式であることができます。
説明
入力値を整数値に変換します。入力パラメータが日付型の場合、その値は Unix epoch からのミリ秒として解釈され、整数に変換されます。ブール値 true は整数 1 に、false は 0 に変換されます。
サポートされる型
| フィールド | 結果 |
|---|---|
| boolean | integer |
| counter_integer | integer |
| date | integer |
| double | integer |
| integer | integer |
| keyword | integer |
| long | integer |
| text | integer |
| unsigned_long | integer |
例
Esql
ROW long = [5013792, 2147483647, 501379200000]| EVAL int = TO_INTEGER(long)
| long:long | int:integer |
|---|---|
| [5013792, 2147483647, 501379200000] | [5013792, 2147483647] |
この例では、複数値フィールドの最後の値は整数に変換できないことに注意してください。この場合、結果は null 値になります。この場合、Warning ヘッダーが応答に追加されます。このヘッダーは、失敗の原因に関する情報を提供します:
"Line 1:61: evaluation of [TO_INTEGER(long)] failed, treating result as null. Only first 20 failures recorded."
次のヘッダーには、失敗の理由と問題のある値が含まれます:
"org.elasticsearch.xpack.esql.core.InvalidArgumentException: [501379200000] out of [integer] range"
TO_IP
構文

パラメータ
field- 入力値。入力は単一または複数値の列または式であることができます。
説明
入力文字列をIP値に変換します。
サポートされる型
| フィールド | 結果 |
|---|---|
| ip | ip |
| keyword | ip |
| text | ip |
例
Esql
ROW str1 = "1.1.1.1", str2 = "foo"| EVAL ip1 = TO_IP(str1), ip2 = TO_IP(str2)| WHERE CIDR_MATCH(ip1, "1.0.0.0/8")
| str1:keyword | str2:keyword | ip1:ip | ip2:ip |
|---|---|---|---|
| 1.1.1.1 | foo | 1.1.1.1 | null |
この例では、文字列の最後の変換が不可能であることに注意してください。この場合、結果は null 値になります。この場合、Warning ヘッダーが応答に追加されます。このヘッダーは、失敗の原因に関する情報を提供します:
"Line 1:68: evaluation of [TO_IP(str2)] failed, treating result as null. Only first 20 failures recorded."
次のヘッダーには、失敗の理由と問題のある値が含まれます:
"java.lang.IllegalArgumentException: 'foo' is not an IP string literal."
TO_LONG
構文

パラメータ
field- 入力値。入力は単一または複数値の列または式であることができます。
説明
入力値をロング値に変換します。入力パラメータが日付型の場合、その値は Unix epoch からのミリ秒として解釈され、ロングに変換されます。ブール値 true はロング 1 に、false は 0 に変換されます。
サポートされる型
| フィールド | 結果 |
|---|---|
| boolean | long |
| counter_integer | long |
| counter_long | long |
| date | long |
| double | long |
| integer | long |
| keyword | long |
| long | long |
| text | long |
| unsigned_long | long |
例
Esql
ROW str1 = "2147483648", str2 = "2147483648.2", str3 = "foo"| EVAL long1 = TO_LONG(str1), long2 = TO_LONG(str2), long3 = TO_LONG(str3)
| str1:keyword | str2:keyword | str3:keyword | long1:long | long2:long | long3:long |
|---|---|---|---|---|---|
| 2147483648 | 2147483648.2 | foo | 2147483648 | 2147483648 | null |
この例では、文字列の最後の変換が不可能であることに注意してください。この場合、結果は null 値になります。この場合、Warning ヘッダーが応答に追加されます。このヘッダーは、失敗の原因に関する情報を提供します:
"Line 1:113: evaluation of [TO_LONG(str3)] failed, treating result as null. Only first 20 failures recorded."
次のヘッダーには、失敗の理由と問題のある値が含まれます:
"java.lang.NumberFormatException: For input string: "foo""
TO_RADIANS
構文

パラメータ
number- 入力値。入力は単一または複数値の列または式であることができます。
説明
サポートされる型
| number | result |
|---|---|
| double | double |
| integer | double |
| long | double |
| unsigned_long | double |
例
Esql
ROW deg = [90.0, 180.0, 270.0]| EVAL rad = TO_RADIANS(deg)
| deg:double | rad:double |
|---|---|
| [90.0, 180.0, 270.0] | [1.5707963267948966, 3.141592653589793, 4.71238898038469] |
TO_STRING
構文

パラメータ
field- 入力値。入力は単一または複数値の列または式であることができます。
説明
入力値を文字列に変換します。
サポートされる型
| フィールド | 結果 |
|---|---|
| boolean | keyword |
| cartesian_point | keyword |
| cartesian_shape | keyword |
| date | keyword |
| double | keyword |
| geo_point | keyword |
| geo_shape | keyword |
| integer | keyword |
| ip | keyword |
| keyword | keyword |
| long | keyword |
| text | keyword |
| unsigned_long | keyword |
| version | keyword |
例
Esql
ROW a=10| EVAL j = TO_STRING(a)
| a:integer | j:keyword |
|---|---|
| 10 | “10” |
複数値フィールドでも正常に動作します:
Esql
ROW a=[10, 9, 8]| EVAL j = TO_STRING(a)
| a:integer | j:keyword |
|---|---|
| [10, 9, 8] | [“10”, “9”, “8”] |
TO_UNSIGNED_LONG
構文

パラメータ
field- 入力値。入力は単一または複数値の列または式であることができます。
説明
入力値を符号なしロング値に変換します。入力パラメータが日付型の場合、その値は Unix epoch からのミリ秒として解釈され、符号なしロングに変換されます。ブール値 true は符号なしロング 1 に、false は 0 に変換されます。
サポートされる型
| フィールド | 結果 |
|---|---|
| boolean | unsigned_long |
| date | unsigned_long |
| double | unsigned_long |
| integer | unsigned_long |
| keyword | unsigned_long |
| long | unsigned_long |
| text | unsigned_long |
| unsigned_long | unsigned_long |
例
Esql
ROW str1 = "2147483648", str2 = "2147483648.2", str3 = "foo"| EVAL long1 = TO_UNSIGNED_LONG(str1), long2 = TO_ULONG(str2), long3 = TO_UL(str3)
| str1:キーワード | str2:キーワード | str3:キーワード | long1:unsigned_long | long2:unsigned_long | long3:unsigned_long |
|---|---|---|---|---|---|
| 2147483648 | 2147483648.2 | foo | 2147483648 | 2147483648 | null |
この例では、文字列の最後の変換が不可能であることに注意してください。この場合、結果は null 値になります。この場合、Warning ヘッダーが応答に追加されます。このヘッダーは、失敗の原因に関する情報を提供します:
"Line 1:133: evaluation of [TO_UL(str3)] failed, treating result as null. Only first 20 failures recorded."
次のヘッダーには、失敗の理由と問題のある値が含まれます:
`````”java.lang.NumberFormatException: Character f is neither a decimal digit number, decimal point,
- “nor “e” notation exponential mark.”`````
TO_VERSION
構文

パラメータ
field- 入力値。入力は単一または複数値の列または式であることができます。
説明
入力文字列をバージョン値に変換します。
サポートされる型
| フィールド | 結果 |
|---|---|
| キーワード | バージョン |
| テキスト | バージョン |
| バージョン | バージョン |
例
Esql
ROW v = TO_VERSION("1.2.3")
| v:バージョン |
|---|
| 1.2.3 |
ES|QL multivalue functions
ES|QLは以下のマルチバリュー関数をサポートしています:
MV_APPENDMV_AVGMV_CONCATMV_COUNTMV_DEDUPEMV_FIRSTMV_LASTMV_MAXMV_MEDIANMV_MINMV_SORTMV_SLICEMV_SUMMV_ZIP
MV_APPEND
構文

パラメータ
field1field2
説明
2つのマルチバリューフィールドの値を連結します。
サポートされる型
| field1 | field2 | result |
|---|---|---|
| boolean | boolean | boolean |
| cartesian_point | cartesian_point | cartesian_point |
| cartesian_shape | cartesian_shape | cartesian_shape |
| date | date | date |
| double | double | double |
| geo_point | geo_point | geo_point |
| geo_shape | geo_shape | geo_shape |
| integer | integer | integer |
| ip | ip | ip |
| keyword | keyword | keyword |
| long | long | long |
| text | text | text |
| version | version | version |
MV_AVG
構文

パラメータ
number- マルチバリュー式。
説明
マルチバリューのフィールドを、すべての値の平均を含む単一値のフィールドに変換します。
サポートされる型
| number | result |
|---|---|
| double | double |
| integer | double |
| long | double |
| unsigned_long | double |
例
Esql
ROW a=[3, 5, 1, 6]| EVAL avg_a = MV_AVG(a)
| a:整数 | avg_a:倍精度 |
|---|---|
| [3, 5, 1, 6] | 3.75 |
MV_CONCAT
構文

パラメータ
string- マルチバリュー式。
delim- デリミタ。
説明
マルチバリューの文字列式を、デリミタで区切られたすべての値の連結を含む単一値の列に変換します。
サポートされる型
| 文字列 | デリミタ | 結果 |
|---|---|---|
| keyword | keyword | keyword |
| keyword | text | keyword |
| text | keyword | keyword |
| text | text | keyword |
例
Esql
ROW a=["foo", "zoo", "bar"]| EVAL j = MV_CONCAT(a, ", ")
| a:キーワード | j:キーワード |
|---|---|
| [“foo”, “zoo”, “bar”] | “foo, zoo, bar” |
非文字列列を連結するには、最初にTO_STRINGを呼び出します:
Esql
ROW a=[10, 9, 8]| EVAL j = MV_CONCAT(TO_STRING(a), ", ")
| a:integer | j:keyword |
|---|---|
| [10, 9, 8] | “10, 9, 8” |
MV_COUNT
構文

パラメータ
field- マルチバリュー式。
説明
マルチバリュー式を、値の数をカウントした単一値の列に変換します。
サポートされる型
| フィールド | 結果 |
|---|---|
| boolean | integer |
| cartesian_point | 整数 |
| cartesian_shape | 整数 |
| date | integer |
| double | integer |
| geo_point | 整数 |
| geo_shape | 整数 |
| integer | integer |
| ip | 整数 |
| keyword | integer |
| long | integer |
| text | integer |
| unsigned_long | integer |
| バージョン | 整数 |
例
Esql
ROW a=["foo", "zoo", "bar"]| EVAL count_a = MV_COUNT(a)
| a:キーワード | count_a:整数 |
|---|---|
| [“foo”, “zoo”, “bar”] | 3 |
MV_DEDUPE
構文

パラメータ
field- マルチバリュー式。
説明
マルチバリューのフィールドから重複する値を削除します。
**サポートされる型**| フィールド | 結果 || :-- | :-- || boolean | boolean || cartesian\_point | cartesian\_point || cartesian\_shape | cartesian\_shape || date | date || double | double || geo\_point | geo\_point || geo\_shape | geo\_shape || integer | integer || ip | ip || keyword | keyword || long | long || text | text || バージョン | バージョン |**例**#### Esql``````esqlROW a=["foo", "foo", "bar", "foo"]| EVAL dedupe_a = MV_DEDUPE(a)`
| a:キーワード | dedupe_a:キーワード |
|---|---|
| [“foo”, “foo”, “bar”, “foo”] | [“foo”, “bar”] |
MV_FIRST
構文

パラメータ
field- マルチバリュー式。
説明
マルチバリュー式を、最初の値を含む単一値の列に変換します。これは、SPLITのように、既知の順序でマルチバリュー列を出力する関数から読み取るときに最も便利です。 マルチバリューのフィールドが基盤ストレージから読み取られる順序は保証されていません。 頻繁に昇順ですが、それに依存しないでください。最小値が必要な場合は、MV_FIRSTの代わりにMV_MINを使用してください。 MV_MINはソートされた値に最適化されているため、MV_FIRSTに対するパフォーマンスの利点はありません。
サポートされる型
| フィールド | 結果 |
|---|---|
| boolean | boolean |
| cartesian_point | cartesian_point |
| cartesian_shape | cartesian_shape |
| date | date |
| double | double |
| geo_point | geo_point |
| geo_shape | geo_shape |
| integer | integer |
| ip | ip |
| keyword | keyword |
| long | long |
| text | text |
| unsigned_long | unsigned_long |
| バージョン | バージョン |
例
Esql
ROW a="foo;bar;baz"| EVAL first_a = MV_FIRST(SPLIT(a, ";"))
| a:キーワード | first_a:キーワード |
|---|---|
| foo;bar;baz | “foo” |
MV_LAST
構文

パラメータ
field- マルチバリュー式。
説明
マルチバリュー式を、最後の値を含む単一値の列に変換します。これは、SPLITのように、既知の順序でマルチバリュー列を出力する関数から読み取るときに最も便利です。 マルチバリューのフィールドが基盤ストレージから読み取られる順序は保証されていません。 頻繁に昇順ですが、それに依存しないでください。最大値が必要な場合は、MV_LASTの代わりにMV_MAXを使用してください。 MV_MAXはソートされた値に最適化されているため、MV_LASTに対するパフォーマンスの利点はありません。
サポートされる型
| フィールド | 結果 |
|---|---|
| boolean | boolean |
| cartesian_point | cartesian_point |
| cartesian_shape | cartesian_shape |
| date | date |
| double | double |
| geo_point | geo_point |
| geo_shape | geo_shape |
| integer | integer |
| ip | ip |
| keyword | keyword |
| long | long |
| text | text |
| unsigned_long | unsigned_long |
| バージョン | バージョン |
例
Esql
ROW a="foo;bar;baz"| EVAL last_a = MV_LAST(SPLIT(a, ";"))
| a:キーワード | last_a:キーワード |
|---|---|
| foo;bar;baz | “baz” |
MV_MAX
構文

パラメータ
field- マルチバリュー式。
説明
マルチバリュー式を、最大値を含む単一値の列に変換します。
サポートされる型
| フィールド | 結果 |
|---|---|
| boolean | boolean |
| date | date |
| double | double |
| integer | integer |
| ip | ip |
| keyword | keyword |
| long | long |
| text | text |
| unsigned_long | unsigned_long |
| バージョン | バージョン |
例
Esql
ROW a=[3, 5, 1]| EVAL max_a = MV_MAX(a)
| a:整数 | max_a:整数 |
|---|---|
| [3, 5, 1] | 5 |
任意の列タイプで使用でき、keyword列も含まれます。その場合、最後の文字列を選択し、utf-8表現をバイト単位で比較します:
Esql
ROW a=["foo", "zoo", "bar"]| EVAL max_a = MV_MAX(a)
| a:キーワード | max_a:キーワード |
|---|---|
| [“foo”, “zoo”, “bar”] | “zoo” |
MV_MEDIAN
構文

パラメータ
number- マルチバリュー式。
説明
マルチバリューのフィールドを、中央値を含む単一値のフィールドに変換します。
サポートされる型
| number | result |
|---|---|
| double | double |
| integer | integer |
| long | long |
| unsigned_long | unsigned_long |
例
Esql
ROW a=[3, 5, 1]| EVAL median_a = MV_MEDIAN(a)
| a:整数 | median_a:整数 |
|---|---|
| [3, 5, 1] | 3 |
行に列の値が偶数の場合、結果は中央の2つのエントリの平均になります。列が浮動小数点でない場合、平均は切り捨てられます:
Esql
ROW a=[3, 7, 1, 6]| EVAL median_a = MV_MEDIAN(a)
| a:整数 | median_a:整数 |
|---|---|
| [3, 7, 1, 6] | 4 |
MV_MIN
構文

パラメータ
field- マルチバリュー式。
説明
マルチバリュー式を、最小値を含む単一値の列に変換します。
サポートされる型
| フィールド | 結果 |
|---|---|
| boolean | boolean |
| date | date |
| double | double |
| integer | integer |
| ip | ip |
| keyword | keyword |
| long | long |
| text | text |
| unsigned_long | unsigned_long |
| バージョン | バージョン |
例
Esql
ROW a=[2, 1]| EVAL min_a = MV_MIN(a)
| a:整数 | min_a:整数 |
|---|---|
| [2, 1] | 1 |
任意の列タイプで使用でき、keyword列も含まれます。その場合、最初の文字列を選択し、utf-8表現をバイト単位で比較します:
Esql
ROW a=["foo", "bar"]| EVAL min_a = MV_MIN(a)
| a:キーワード | min_a:キーワード |
|---|---|
| [“foo”, “bar”] | “bar” |
MV_SLICE
構文

パラメータ
field- マルチバリュー式。
nullの場合、関数はnullを返します。 start- 開始位置。
nullの場合、関数はnullを返します。開始引数は負の値を取ることができます。インデックス-1は、リストの最後の値を指定するために使用されます。 end- 終了位置(含む)。オプション;省略した場合、
startの位置が返されます。終了引数は負の値を取ることができます。インデックス-1は、リストの最後の値を指定するために使用されます。
マルチバリューのフィールドのサブセットを、開始および終了インデックス値を使用して返します。
サポートされる型
| field | start | end | result |
|---|---|---|---|
| boolean | 整数 | 整数 | boolean |
| cartesian_point | 整数 | 整数 | cartesian_point |
| cartesian_shape | 整数 | 整数 | cartesian_shape |
| date | 整数 | 整数 | date |
| double | 整数 | 整数 | double |
| geo_point | 整数 | 整数 | geo_point |
| geo_shape | 整数 | 整数 | geo_shape |
| 整数 | 整数 | 整数 | 整数 |
| ip | integer | integer | ip |
| キーワード | 整数 | 整数 | キーワード |
| long | 整数 | 整数 | long |
| text | 整数 | 整数 | text |
| version | 整数 | 整数 | version |
例
Esql
row a = [1, 2, 2, 3]| eval a1 = mv_slice(a, 1), a2 = mv_slice(a, 2, 3)
| a:整数 | a1:整数 | a2:整数 |
|---|---|---|
| [1, 2, 2, 3] | 2 | [2, 3] |
Esql
row a = [1, 2, 2, 3]| eval a1 = mv_slice(a, -2), a2 = mv_slice(a, -3, -1)
| a:整数 | a1:整数 | a2:整数 |
|---|---|---|
| [1, 2, 2, 3] | 2 | [2, 2, 3] |
MV_SORT
構文

パラメータ
field- マルチバリュー式。
nullの場合、関数はnullを返します。 order- ソート順。 有効なオプションはASCとDESCで、デフォルトはASCです。
説明
マルチバリューのフィールドを辞書順にソートします。
サポートされる型
| field | order | result |
|---|---|---|
| boolean | キーワード | boolean |
| date | キーワード | date |
| double | キーワード | double |
| 整数 | キーワード | 整数 |
| ip | キーワード | ip |
| keyword | keyword | keyword |
| long | キーワード | long |
| text | キーワード | text |
| version | キーワード | version |
例
Esql
ROW a = [4, 2, -3, 2]| EVAL sa = mv_sort(a), sd = mv_sort(a, "DESC")
| a:整数 | sa:整数 | sd:整数 |
|---|---|---|
| [4, 2, -3, 2] | [-3, 2, 2, 4] | [4, 2, 2, -3] |
MV_SUM
構文

パラメータ
number- マルチバリュー式。
説明
マルチバリューのフィールドを、すべての値の合計を含む単一値のフィールドに変換します。
サポートされる型
| number | result |
|---|---|
| double | double |
| integer | integer |
| long | long |
| unsigned_long | unsigned_long |
例
Esql
ROW a=[3, 5, 6]| EVAL sum_a = MV_SUM(a)
| a:整数 | sum_a:整数 |
|---|---|
| [3, 5, 6] | 14 |
MV_ZIP
構文

パラメータ
string1- マルチバリュー式。
string2- マルチバリュー式。
delim- デリミタ。オプション;省略した場合、
,がデフォルトのデリミタとして使用されます。
説明
デリミタで結合された2つのマルチバリューのフィールドから値を組み合わせます。
サポートされる型
| string1 | string2 | delim | result |
|---|---|---|---|
| キーワード | キーワード | キーワード | キーワード |
| キーワード | キーワード | テキスト | キーワード |
| キーワード | キーワード | キーワード | |
| キーワード | テキスト | キーワード | キーワード |
| キーワード | テキスト | テキスト | キーワード |
| キーワード | テキスト | キーワード | |
| テキスト | キーワード | キーワード | キーワード |
| テキスト | キーワード | テキスト | キーワード |
| テキスト | キーワード | キーワード | |
| テキスト | テキスト | キーワード | キーワード |
| テキスト | テキスト | テキスト | キーワード |
| テキスト | テキスト | キーワード |
例
Esql
ROW a = ["x", "y", "z"], b = ["1", "2"]| EVAL c = mv_zip(a, b, "-")| KEEP a, b, c
| a:キーワード | b:キーワード | c:キーワード |
|---|---|---|
| [x, y, z] | [1 ,2] | [x-1, y-2, z] |
ES|QL operators
1つまたは複数の式に対して比較するためのブール演算子。
Binary operators
Equality

2つのフィールドが等しいかどうかを確認します。いずれかのフィールドがマルチバリューの場合、結果はnullです。
比較の片側が定数で、もう片側がインデックス内のフィールドで、indexとdoc_valuesの両方を持つ場合、これは基盤の検索インデックスにプッシュされます。
サポートされているタイプ:
サポートされる型
| lhs | rhs | result |
|---|---|---|
| boolean | boolean | boolean |
| cartesian_point | cartesian_point | boolean |
| cartesian_shape | cartesian_shape | boolean |
| date | date | boolean |
| double | double | boolean |
| double | 整数 | boolean |
| double | long | boolean |
| geo_point | geo_point | boolean |
| geo_shape | geo_shape | boolean |
| 整数 | double | boolean |
| 整数 | 整数 | boolean |
| 整数 | long | boolean |
| ip | ip | boolean |
| keyword | keyword | boolean |
| キーワード | テキスト | boolean |
| long | double | boolean |
| long | 整数 | boolean |
| long | long | boolean |
| テキスト | キーワード | boolean |
| text | text | boolean |
| unsigned_long | unsigned_long | boolean |
| バージョン | バージョン | boolean |
Inequality !=

2つのフィールドが不等であるかどうかを確認します。いずれかのフィールドがマルチバリューの場合、結果はnullです。
比較の片側が定数で、もう片側がインデックス内のフィールドで、indexとdoc_valuesの両方を持つ場合、これは基盤の検索インデックスにプッシュされます。
サポートされているタイプ:
サポートされる型
| lhs | rhs | result |
|---|---|---|
| boolean | boolean | boolean |
| cartesian_point | cartesian_point | boolean |
| cartesian_shape | cartesian_shape | boolean |
| date | date | boolean |
| double | double | boolean |
| double | 整数 | boolean |
| double | long | boolean |
| geo_point | geo_point | boolean |
| geo_shape | geo_shape | boolean |
| 整数 | double | boolean |
| 整数 | 整数 | boolean |
| 整数 | long | boolean |
| ip | ip | boolean |
| keyword | keyword | boolean |
| キーワード | テキスト | boolean |
| long | double | boolean |
| long | 整数 | boolean |
| long | long | boolean |
| テキスト | キーワード | boolean |
| text | text | boolean |
| unsigned_long | unsigned_long | boolean |
| バージョン | バージョン | boolean |
Less than <

1つのフィールドが別のフィールドより小さいかどうかを確認します。いずれかのフィールドがマルチバリューの場合、結果はnullです。
比較の片側が定数で、もう片側がインデックス内のフィールドで、indexとdoc_valuesの両方を持つ場合、これは基盤の検索インデックスにプッシュされます。
サポートされているタイプ:
サポートされる型
| lhs | rhs | result |
|---|---|---|
| date | date | boolean |
| double | double | boolean |
| double | 整数 | boolean |
| double | long | boolean |
| 整数 | double | boolean |
| 整数 | 整数 | boolean |
| 整数 | long | boolean |
| ip | ip | boolean |
| keyword | keyword | boolean |
| キーワード | テキスト | boolean |
| long | double | boolean |
| long | 整数 | boolean |
| long | long | boolean |
| テキスト | キーワード | boolean |
| text | text | boolean |
| unsigned_long | unsigned_long | boolean |
| バージョン | バージョン | boolean |
Less than or equal to <=

1つのフィールドが別のフィールド以下であるかどうかを確認します。いずれかのフィールドがマルチバリューの場合、結果はnullです。
比較の片側が定数で、もう片側がインデックス内のフィールドで、indexとdoc_valuesの両方を持つ場合、これは基盤の検索インデックスにプッシュされます。
サポートされているタイプ:
サポートされる型
| lhs | rhs | result |
|---|---|---|
| date | date | boolean |
| double | double | boolean |
| double | 整数 | boolean |
| double | long | boolean |
| 整数 | double | boolean |
| 整数 | 整数 | boolean |
| 整数 | long | boolean |
| ip | ip | boolean |
| keyword | keyword | boolean |
| キーワード | テキスト | boolean |
| long | double | boolean |
| long | 整数 | boolean |
| long | long | boolean |
| テキスト | キーワード | boolean |
| text | text | boolean |
| unsigned_long | unsigned_long | boolean |
| バージョン | バージョン | boolean |
Greater than >

1つのフィールドが別のフィールドより大きいかどうかを確認します。いずれかのフィールドがマルチバリューの場合、結果はnullです。
比較の片側が定数で、もう片側がインデックス内のフィールドで、indexとdoc_valuesの両方を持つ場合、これは基盤の検索インデックスにプッシュされます。
サポートされているタイプ:
サポートされる型
| lhs | rhs | result |
|---|---|---|
| date | date | boolean |
| double | double | boolean |
| double | 整数 | boolean |
| double | long | boolean |
| 整数 | double | boolean |
| 整数 | 整数 | boolean |
| 整数 | long | boolean |
| ip | ip | boolean |
| keyword | keyword | boolean |
| キーワード | テキスト | boolean |
| long | double | boolean |
| long | 整数 | boolean |
| long | long | boolean |
| テキスト | キーワード | boolean |
| text | text | boolean |
| unsigned_long | unsigned_long | boolean |
| バージョン | バージョン | boolean |
Greater than or equal to >=

1つのフィールドが別のフィールド以上であるかどうかを確認します。いずれかのフィールドがマルチバリューの場合、結果はnullです。
比較の片側が定数で、もう片側がインデックス内のフィールドで、indexとdoc_valuesの両方を持つ場合、これは基盤の検索インデックスにプッシュされます。
サポートされているタイプ:
サポートされる型
| lhs | rhs | result |
|---|---|---|
| date | date | boolean |
| double | double | boolean |
| double | 整数 | boolean |
| double | long | boolean |
| 整数 | double | boolean |
| 整数 | 整数 | boolean |
| 整数 | long | boolean |
| ip | ip | boolean |
| keyword | keyword | boolean |
| キーワード | テキスト | boolean |
| long | double | boolean |
| long | 整数 | boolean |
| long | long | boolean |
| テキスト | キーワード | boolean |
| text | text | boolean |
| unsigned_long | unsigned_long | boolean |
| バージョン | バージョン | boolean |
Add +

2つの数値を加算します。いずれかのフィールドがマルチバリューの場合、結果はnullです。
サポートされているタイプ:
サポートされる型
| lhs | rhs | result |
|---|---|---|
| date | date_period | date |
| date | time_duration | date |
| date_period | date | date |
| date_period | date_period | date_period |
| double | double | double |
| double | integer | double |
| double | long | double |
| integer | double | double |
| integer | integer | integer |
| 整数 | long | long |
| long | double | double |
| long | integer | long |
| long | long | long |
| time_duration | date | date |
| time_duration | time_duration | time_duration |
| unsigned_long | unsigned_long | unsigned_long |
" class="reference-link">引き算 -
一つの数から別の数を引きます。いずれかのフィールドがmultivaluedの場合、結果はnullです。
サポートされているタイプ:
サポートされる型
| lhs | rhs | result |
|---|---|---|
| date | date_period | date |
| date | time_duration | date |
| date_period | date_period | date_period |
| double | double | double |
| double | integer | double |
| double | long | double |
| integer | double | double |
| integer | integer | integer |
| 整数 | long | long |
| long | double | double |
| long | integer | long |
| long | long | long |
| time_duration | time_duration | time_duration |
| unsigned_long | unsigned_long | unsigned_long |
掛け算 *

二つの数を掛け算します。いずれかのフィールドがmultivaluedの場合、結果はnullです。
サポートされているタイプ:
サポートされる型
| lhs | rhs | result |
|---|---|---|
| double | double | double |
| double | integer | double |
| double | long | double |
| integer | double | double |
| integer | integer | integer |
| 整数 | long | long |
| long | double | double |
| long | integer | long |
| long | long | long |
| unsigned_long | unsigned_long | unsigned_long |
割り算 /

一つの数を別の数で割ります。いずれかのフィールドがmultivaluedの場合、結果はnullです。
二つの整数型を割ると、整数の結果が得られ、0に向かって丸められます。浮動小数点の割り算が必要な場合は、Cast (::)のいずれかの引数をDOUBLEに変換してください。
サポートされているタイプ:
サポートされる型
| lhs | rhs | result |
|---|---|---|
| double | double | double |
| double | integer | double |
| double | long | double |
| integer | double | double |
| integer | integer | integer |
| 整数 | long | long |
| long | double | double |
| long | integer | long |
| long | long | long |
| unsigned_long | unsigned_long | unsigned_long |
剰余 %

一つの数を別の数で割り、余りを返します。いずれかのフィールドがmultivaluedの場合、結果はnullです。
サポートされているタイプ:
サポートされる型
| lhs | rhs | result |
|---|---|---|
| double | double | double |
| double | integer | double |
| double | long | double |
| integer | double | double |
| integer | integer | integer |
| 整数 | long | long |
| long | double | double |
| long | integer | long |
| long | long | long |
| unsigned_long | unsigned_long | unsigned_long |
単項演算子
唯一の単項演算子は否定(-)です:

サポートされているタイプ:
サポートされる型
| v | result |
|---|---|
| date_period | date_period |
| double | double |
| integer | integer |
| long | long |
| time_duration | time_duration |
論理演算子
次の論理演算子がサポートされています:
ANDORNOT
IS NULL および IS NOT NULL 述語
NULL 比較には、IS NULL および IS NOT NULL 述語を使用します:
Esql
FROM employees| WHERE birth_date IS NULL| KEEP first_name, last_name| SORT first_name| LIMIT 3
| first_name:keyword | last_name:keyword |
|---|---|
| Basil | Tramer |
| Florian | Syrotiuk |
| Lucien | Rosenbaum |
Esql
FROM employees| WHERE is_rehired IS NOT NULL| STATS COUNT(emp_no)
| COUNT(emp_no):long |
|---|
| 84 |
キャスト (::)
:: 演算子は、TO_
Esql
ROW ver = CONCAT(("0"::INT + 1)::STRING, ".2.3")::VERSION
| ver:version |
|---|
| 1.2.3 |
IN
IN 演算子は、フィールドまたは式がリテラル、フィールド、または式のリストの要素と等しいかどうかをテストすることを可能にします:
Esql
ROW a = 1, b = 4, c = 3| WHERE c-a IN (3, b / 2, a)
| a:integer | b:integer | c:integer |
|---|---|---|
| 1 | 4 | 3 |
LIKE
LIKE を使用して、ワイルドカードを使用して文字列パターンに基づいてデータをフィルタリングします。LIKE は通常、演算子の左側に配置されたフィールドに作用しますが、定数(リテラル)式にも作用できます。演算子の右側はパターンを表します。
次のワイルドカード文字がサポートされています:
*は0文字以上に一致します。?は1文字に一致します。
サポートされる型
| str | pattern | result |
|---|---|---|
| keyword | keyword | boolean |
| text | text | boolean |
Esql
FROM employees| WHERE first_name LIKE "?b*"| KEEP first_name, last_name
| first_name:keyword | last_name:keyword |
|---|---|
| Ebbe | Callaway |
| Eberhardt | Terkki |
RLIKE
RLIKE を使用して、正規表現 を使用して文字列パターンに基づいてデータをフィルタリングします。RLIKE は通常、演算子の左側に配置されたフィールドに作用しますが、定数(リテラル)式にも作用できます。演算子の右側はパターンを表します。
サポートされる型
| str | pattern | result |
|---|---|---|
| keyword | keyword | boolean |
| text | text | boolean |
Esql
FROM employees| WHERE first_name RLIKE ".leja.*"| KEEP first_name, last_name
| first_name:keyword | last_name:keyword |
|---|---|
| Alejandro | McAlpine |
