ES|QL クエリの始め方
このガイドでは、ES|QLを使用してデータをクエリし、集計する方法を示します。
この入門ガイドは、elasticsearch-labs GitHub リポジトリの インタラクティブ Python ノートブック としても利用可能です。
前提条件
このガイドのクエリに従うには、自分のデプロイメントを設定するか、Elastic の公開 ES|QL デモ環境を使用できます。
まず、いくつかのサンプルデータを取り込みます。Kibana で、メインメニューを開き、Dev
Tools を選択します。次の 2 つのリクエストを実行します:
Python
resp = client.indices.create(index="sample_data",mappings={"properties": {"client_ip": {"type": "ip"},"message": {"type": "keyword"}}},)print(resp)resp1 = client.bulk(index="sample_data",operations=[{"index": {}},{"@timestamp": "2023-10-23T12:15:03.360Z","client_ip": "172.21.2.162","message": "Connected to 10.1.0.3","event_duration": 3450233},{"index": {}},{"@timestamp": "2023-10-23T12:27:28.948Z","client_ip": "172.21.2.113","message": "Connected to 10.1.0.2","event_duration": 2764889},{"index": {}},{"@timestamp": "2023-10-23T13:33:34.937Z","client_ip": "172.21.0.5","message": "Disconnected","event_duration": 1232382},{"index": {}},{"@timestamp": "2023-10-23T13:51:54.732Z","client_ip": "172.21.3.15","message": "Connection error","event_duration": 725448},{"index": {}},{"@timestamp": "2023-10-23T13:52:55.015Z","client_ip": "172.21.3.15","message": "Connection error","event_duration": 8268153},{"index": {}},{"@timestamp": "2023-10-23T13:53:55.832Z","client_ip": "172.21.3.15","message": "Connection error","event_duration": 5033755},{"index": {}},{"@timestamp": "2023-10-23T13:55:01.543Z","client_ip": "172.21.3.15","message": "Connected to 10.1.0.1","event_duration": 1756467}],)print(resp1)
Ruby
response = client.indices.create(index: 'sample_data',body: {mappings: {properties: {client_ip: {type: 'ip'},message: {type: 'keyword'}}}})puts responseresponse = client.bulk(index: 'sample_data',body: [{index: {}},{"@timestamp": '2023-10-23T12:15:03.360Z',client_ip: '172.21.2.162',message: 'Connected to 10.1.0.3',event_duration: 3_450_233},{index: {}},{"@timestamp": '2023-10-23T12:27:28.948Z',client_ip: '172.21.2.113',message: 'Connected to 10.1.0.2',event_duration: 2_764_889},{index: {}},{"@timestamp": '2023-10-23T13:33:34.937Z',client_ip: '172.21.0.5',message: 'Disconnected',event_duration: 1_232_382},{index: {}},{"@timestamp": '2023-10-23T13:51:54.732Z',client_ip: '172.21.3.15',message: 'Connection error',event_duration: 725_448},{index: {}},{"@timestamp": '2023-10-23T13:52:55.015Z',client_ip: '172.21.3.15',message: 'Connection error',event_duration: 8_268_153},{index: {}},{"@timestamp": '2023-10-23T13:53:55.832Z',client_ip: '172.21.3.15',message: 'Connection error',event_duration: 5_033_755},{index: {}},{"@timestamp": '2023-10-23T13:55:01.543Z',client_ip: '172.21.3.15',message: 'Connected to 10.1.0.1',event_duration: 1_756_467}])puts response
Js
const response = await client.indices.create({index: "sample_data",mappings: {properties: {client_ip: {type: "ip",},message: {type: "keyword",},},},});console.log(response);const response1 = await client.bulk({index: "sample_data",operations: [{index: {},},{"@timestamp": "2023-10-23T12:15:03.360Z",client_ip: "172.21.2.162",message: "Connected to 10.1.0.3",event_duration: 3450233,},{index: {},},{"@timestamp": "2023-10-23T12:27:28.948Z",client_ip: "172.21.2.113",message: "Connected to 10.1.0.2",event_duration: 2764889,},{index: {},},{"@timestamp": "2023-10-23T13:33:34.937Z",client_ip: "172.21.0.5",message: "Disconnected",event_duration: 1232382,},{index: {},},{"@timestamp": "2023-10-23T13:51:54.732Z",client_ip: "172.21.3.15",message: "Connection error",event_duration: 725448,},{index: {},},{"@timestamp": "2023-10-23T13:52:55.015Z",client_ip: "172.21.3.15",message: "Connection error",event_duration: 8268153,},{index: {},},{"@timestamp": "2023-10-23T13:53:55.832Z",client_ip: "172.21.3.15",message: "Connection error",event_duration: 5033755,},{index: {},},{"@timestamp": "2023-10-23T13:55:01.543Z",client_ip: "172.21.3.15",message: "Connected to 10.1.0.1",event_duration: 1756467,},],});console.log(response1);
コンソール
PUT sample_data{"mappings": {"properties": {"client_ip": {"type": "ip"},"message": {"type": "keyword"}}}}PUT sample_data/_bulk{"index": {}}{"@timestamp": "2023-10-23T12:15:03.360Z", "client_ip": "172.21.2.162", "message": "Connected to 10.1.0.3", "event_duration": 3450233}{"index": {}}{"@timestamp": "2023-10-23T12:27:28.948Z", "client_ip": "172.21.2.113", "message": "Connected to 10.1.0.2", "event_duration": 2764889}{"index": {}}{"@timestamp": "2023-10-23T13:33:34.937Z", "client_ip": "172.21.0.5", "message": "Disconnected", "event_duration": 1232382}{"index": {}}{"@timestamp": "2023-10-23T13:51:54.732Z", "client_ip": "172.21.3.15", "message": "Connection error", "event_duration": 725448}{"index": {}}{"@timestamp": "2023-10-23T13:52:55.015Z", "client_ip": "172.21.3.15", "message": "Connection error", "event_duration": 8268153}{"index": {}}{"@timestamp": "2023-10-23T13:53:55.832Z", "client_ip": "172.21.3.15", "message": "Connection error", "event_duration": 5033755}{"index": {}}{"@timestamp": "2023-10-23T13:55:01.543Z", "client_ip": "172.21.3.15", "message": "Connected to 10.1.0.1", "event_duration": 1756467}
このガイドで使用されるデータセットは、Elastic ES|QL 公開デモ環境に事前にロードされています。ela.st/ql を訪れて使用を開始してください。
ES|QL クエリの実行
Kibana では、Console または Discover を使用して ES|QL クエリを実行できます:
Console で ES|QL を始めるには、メインメニューを開き、Dev Tools を選択します。
ES|QL クエリ API リクエストの一般的な構造は次のとおりです:
テキスト
POST /_query?format=txt{"query": """"""}
実際の ES|QL クエリを 2 つの三重引用符の間に入力します。例えば:
テキスト
POST /_query?format=txt{"query": """FROM sample_data"""}
Discover で ES|QL を始めるには、メインメニューを開き、Discover を選択します。次に、データビュー メニューから Language: ES|QL を選択します。
サンプルデータのタイムスタンプを含むように、時間フィルターを調整します(2023年10月23日)。
ES|QL モードに切り替えると、クエリバーにサンプルクエリが表示されます。このクエリをこの入門ガイドのクエリに置き換えることができます。
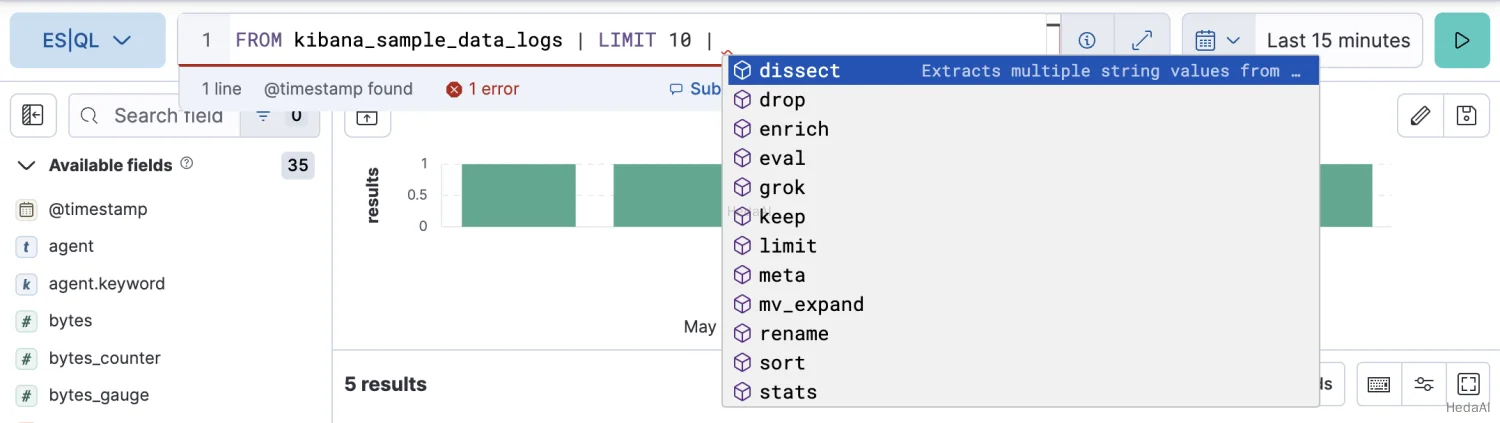
クエリの記述を容易にするために、オートコンプリートは可能なコマンドや関数の提案を提供します:
マルチラインクエリの記述を容易にするために、二重矢印ボタン ( ) をクリックしてクエリバーを展開します:
) をクリックしてクエリバーを展開します:
コンパクトなクエリバーに戻るには、エディタを最小化するボタン ( ) をクリックします。
) をクリックします。
最初の ES|QL クエリ
各 ES|QL クエリは、ソースコマンド で始まります。ソースコマンドは、通常、Elasticsearch からのデータを持つテーブルを生成します。

FROM ソースコマンドは、データストリーム、インデックス、またはエイリアスからのドキュメントを持つテーブルを返します。結果のテーブルの各行は、1 つのドキュメントを表します。このクエリは、sample_data インデックスから最大 1000 ドキュメントを返します:
Esql
FROM sample_data
各列はフィールドに対応し、そのフィールドの名前でアクセスできます。
ES|QL キーワードは大文字と小文字を区別しません。次のクエリは前のクエリと同じです:
Esql
from sample_data
処理コマンド
ソースコマンドの後には、パイプ文字で区切られた 1 つ以上の 処理コマンド を続けることができます: |。処理コマンドは、行や列を追加、削除、または変更することによって入力テーブルを変更します。処理コマンドは、フィルタリング、プロジェクション、集計などを実行できます。

例えば、LIMIT コマンドを使用して、返される行の数を最大 10,000 行に制限できます:
Esql
FROM sample_data| LIMIT 3
可読性のために、各コマンドを別の行に置くことができます。ただし、必ずしもそうする必要はありません。次のクエリは前のクエリと同じです:
Esql
FROM sample_data | LIMIT 3
テーブルのソート
別の処理コマンドは、SORT コマンドです。デフォルトでは、FROM によって返される行には定義されたソート順序がありません。SORT コマンドを使用して、1 つ以上の列で行をソートします:
Esql
FROM sample_data| SORT @timestamp DESC
データのクエリ
データをクエリするには、WHERE コマンドを使用します。例えば、5ms より長い期間のすべてのイベントを見つけるには:
Esql
FROM sample_data| WHERE event_duration > 5000000
WHERE は、いくつかの 演算子 をサポートしています。例えば、LIKE を使用して、message 列に対してワイルドカードクエリを実行できます:
Esql
FROM sample_data| WHERE message LIKE "Connected*"
さらなる処理コマンド
KEEP や DROP など、列を保持または削除するための他の多くの処理コマンドがあります。ENRICH は、Elasticsearch のインデックスからデータを使用してテーブルを強化し、DISSECT や GROK はデータを処理します。処理コマンド を参照して、すべての処理コマンドの概要を確認してください。
処理コマンドのチェーン
処理コマンドは、パイプ文字で区切ってチェーンできます: |。各処理コマンドは、前のコマンドの出力テーブルで動作します。クエリの結果は、最終的な処理コマンドによって生成されたテーブルです。
次の例では、最初に @timestamp でテーブルをソートし、次に結果セットを 3 行に制限します:
Esql
FROM sample_data| SORT @timestamp DESC| LIMIT 3
処理コマンドの順序は重要です。最初に結果セットを 3 行に制限してから、その 3 行をソートすると、この例とは異なる結果が返される可能性が高いです。この例では、ソートが制限の前に行われます。
値の計算
EVAL コマンドを使用して、計算された値を持つ列をテーブルに追加します。例えば、次のクエリは duration_ms 列を追加します。この列の値は、event_duration を 1,000,000 で割ることによって計算されます。言い換えれば、event_duration はナノ秒からミリ秒に変換されます。
Esql
FROM sample_data| EVAL duration_ms = event_duration/1000000.0
EVAL は、いくつかの 関数 をサポートしています。例えば、指定された桁数で最も近い数に丸めるには、ROUND 関数を使用します:
Esql
FROM sample_data| EVAL duration_ms = ROUND(event_duration/1000000.0, 1)
統計の計算
ES|QL は、データをクエリするだけでなく、データを集計するためにも使用できます。STATS ... BY コマンドを使用して統計を計算します。例えば、中央値の期間:
Esql
FROM sample_data| STATS median_duration = MEDIAN(event_duration)
1 つのコマンドで複数の統計を計算できます:
Esql
FROM sample_data| STATS median_duration = MEDIAN(event_duration), max_duration = MAX(event_duration)
BY を使用して、計算された統計を 1 つ以上の列でグループ化します。例えば、クライアント IP ごとの中央値の期間を計算するには:
Esql
FROM sample_data| STATS median_duration = MEDIAN(event_duration) BY client_ip
列へのアクセス
列には、その名前でアクセスできます。名前に特殊文字が含まれている場合は、バックティックで引用する必要があります (` )。
EVAL または STATS によって作成された列に明示的な名前を付けることはオプションです。名前を提供しない場合、新しい列の名前は関数式と等しくなります。例えば:
Esql
FROM sample_data| EVAL event_duration/1000000.0
このクエリでは、EVAL が event_duration/1000000.0 という名前の新しい列を追加します。名前に特殊文字が含まれているため、この列にアクセスするには、バックティックで引用します:
Esql
FROM sample_data| EVAL event_duration/1000000.0| STATS MEDIAN(`event_duration/1000000.0`)
ヒストグラムの作成
時間の経過に伴う統計を追跡するために、ES|QL は BUCKET 関数を使用してヒストグラムを作成できます。BUCKET は、人間に優しいバケットサイズを作成し、各行に対して、その行が属する結果のバケットに対応する値を返します。
BUCKET と組み合わせてヒストグラムを作成します。例えば、時間ごとのイベント数をカウントするには:
Esql
FROM sample_data| STATS c = COUNT(*) BY bucket = BUCKET(@timestamp, 24, "2023-10-23T00:00:00Z", "2023-10-23T23:59:59Z")
または、時間ごとの中央値の期間:
Esql
FROM sample_data| KEEP @timestamp, event_duration| STATS median_duration = MEDIAN(event_duration) BY bucket = BUCKET(@timestamp, 24, "2023-10-23T00:00:00Z", "2023-10-23T23:59:59Z")
ES|QL クエリの始め方
このガイドでは、ES|QLを使用してデータをクエリし、集計する方法を示します。
この入門ガイドは、elasticsearch-labs GitHub リポジトリの インタラクティブ Python ノートブック としても利用可能です。
Python
resp = client.indices.create(index="clientips",mappings={"properties": {"client_ip": {"type": "keyword"},"env": {"type": "keyword"}}},)print(resp)resp1 = client.bulk(index="clientips",operations=[{"index": {}},{"client_ip": "172.21.0.5","env": "Development"},{"index": {}},{"client_ip": "172.21.2.113","env": "QA"},{"index": {}},{"client_ip": "172.21.2.162","env": "QA"},{"index": {}},{"client_ip": "172.21.3.15","env": "Production"},{"index": {}},{"client_ip": "172.21.3.16","env": "Production"}],)print(resp1)resp2 = client.enrich.put_policy(name="clientip_policy",match={"indices": "clientips","match_field": "client_ip","enrich_fields": ["env"]},)print(resp2)resp3 = client.enrich.execute_policy(name="clientip_policy",wait_for_completion=False,)print(resp3)
Ruby
response = client.indices.create(index: 'clientips',body: {mappings: {properties: {client_ip: {type: 'keyword'},env: {type: 'keyword'}}}})puts responseresponse = client.bulk(index: 'clientips',body: [{index: {}},{client_ip: '172.21.0.5',env: 'Development'},{index: {}},{client_ip: '172.21.2.113',env: 'QA'},{index: {}},{client_ip: '172.21.2.162',env: 'QA'},{index: {}},{client_ip: '172.21.3.15',env: 'Production'},{index: {}},{client_ip: '172.21.3.16',env: 'Production'}])puts responseresponse = client.enrich.put_policy(name: 'clientip_policy',body: {match: {indices: 'clientips',match_field: 'client_ip',enrich_fields: ['env']}})puts responseresponse = client.enrich.execute_policy(name: 'clientip_policy',wait_for_completion: false)puts response
Js
const response = await client.indices.create({index: "clientips",mappings: {properties: {client_ip: {type: "keyword",},env: {type: "keyword",},},},});console.log(response);const response1 = await client.bulk({index: "clientips",operations: [{index: {},},{client_ip: "172.21.0.5",env: "Development",},{index: {},},{client_ip: "172.21.2.113",env: "QA",},{index: {},},{client_ip: "172.21.2.162",env: "QA",},{index: {},},{client_ip: "172.21.3.15",env: "Production",},{index: {},},{client_ip: "172.21.3.16",env: "Production",},],});console.log(response1);const response2 = await client.enrich.putPolicy({name: "clientip_policy",match: {indices: "clientips",match_field: "client_ip",enrich_fields: ["env"],},});console.log(response2);const response3 = await client.enrich.executePolicy({name: "clientip_policy",wait_for_completion: "false",});console.log(response3);
コンソール
PUT clientips{"mappings": {"properties": {"client_ip": {"type": "keyword"},"env": {"type": "keyword"}}}}PUT clientips/_bulk{ "index" : {}}{ "client_ip": "172.21.0.5", "env": "Development" }{ "index" : {}}{ "client_ip": "172.21.2.113", "env": "QA" }{ "index" : {}}{ "client_ip": "172.21.2.162", "env": "QA" }{ "index" : {}}{ "client_ip": "172.21.3.15", "env": "Production" }{ "index" : {}}{ "client_ip": "172.21.3.16", "env": "Production" }PUT /_enrich/policy/clientip_policy{"match": {"indices": "clientips","match_field": "client_ip","enrich_fields": ["env"]}}PUT /_enrich/policy/clientip_policy/_execute?wait_for_completion=false
ela.st/ql のデモ環境では、clientip_policy という名前の強化ポリシーがすでに作成され、実行されています。このポリシーは、IP アドレスを環境(「Development」、「QA」、または「Production」)にリンクします。
ポリシーを作成して実行した後、ENRICH コマンドで使用できます:
Esql
FROM sample_data| KEEP @timestamp, client_ip, event_duration| EVAL client_ip = TO_STRING(client_ip)| ENRICH clientip_policy ON client_ip WITH env
ENRICH コマンドによって追加された新しい env 列を、後続のコマンドで使用できます。例えば、環境ごとの中央値の期間を計算するには:
Esql
FROM sample_data| KEEP @timestamp, client_ip, event_duration| EVAL client_ip = TO_STRING(client_ip)| ENRICH clientip_policy ON client_ip WITH env| STATS median_duration = MEDIAN(event_duration) BY env
ES|QL によるデータの強化についての詳細は、データの強化 を参照してください。
データの処理
データには、分析を容易にするために 構造化 したい非構造化文字列が含まれている場合があります。例えば、サンプルデータには次のようなログメッセージが含まれています:
テキスト
"Connected to 10.1.0.3"
これらのメッセージから IP アドレスを抽出することで、どの IP が最も多くのクライアント接続を受け入れたかを判断できます。
クエリ時に非構造化文字列を構造化するには、ES|QL の DISSECT および GROK コマンドを使用できます。DISSECT は、区切り文字ベースのパターンを使用して文字列を分割します。GROK は同様に機能しますが、正規表現を使用します。これにより、GROK はより強力になりますが、一般的に遅くなります。
この場合、正規表現は必要ありません。なぜなら、message は単純だからです: 「Connected to 」の後にサーバー IP が続きます。この文字列に一致させるには、次の DISSECT コマンドを使用できます:
Esql
FROM sample_data| DISSECT message "Connected to %{server_ip}"
これにより、このパターンに一致する message を持つ行に server_ip 列が追加されます。他の行の server_ip の値は null です。
DISSECT コマンドによって追加された新しい server_ip 列を、後続のコマンドで使用できます。例えば、各サーバーが受け入れた接続数を判断するには:
Esql
FROM sample_data| WHERE STARTS_WITH(message, "Connected to")| DISSECT message "Connected to %{server_ip}"| STATS COUNT(*) BY server_ip
ES|QL によるデータ処理の詳細は、DISSECT と GROK を使用したデータ処理 を参照してください。
詳細を学ぶ
ES|QL について詳しく学ぶには、ES|QL リファレンス および ES|QL の使用 を参照してください。
