クラスタレベルのシャード割り当てとルーティング設定
シャード割り当ては、シャードのコピーをノードに割り当てるプロセスです。これは、初期回復、レプリカの割り当て、再バランス、ノードがクラスタに追加または削除されるとき、または割り当てに影響を与えるクラスタまたはインデックス設定が更新されるときに発生する可能性があります。
マスターの主な役割の1つは、どのシャードをどのノードに割り当てるか、そしてクラスタのバランスを取るためにシャードをノード間で移動するタイミングを決定することです。
シャード割り当てプロセスを制御するための設定がいくつかあります:
- クラスタレベルのシャード割り当て設定は、割り当てと再バランス操作を制御します。
- ディスクベースのシャード割り当て設定は、Elasticsearchが利用可能なディスクスペースを考慮に入れる方法と関連設定を説明します。
- シャード割り当ての認識と強制認識は、シャードが異なるラックや可用性ゾーンに分散される方法を制御します。
- クラスタレベルのシャード割り当てフィルタリングは、特定のノードまたはノードのグループを割り当てから除外し、廃止できるようにします。
これらに加えて、いくつかの他の雑多なクラスタレベルの設定があります。
クラスタレベルのシャード割り当て設定
次の設定を使用して、シャードの割り当てと回復を制御できます:
cluster.routing.allocation.enable(動的) 特定の種類のシャードの割り当てを有効または無効にします:
all- (デフォルト) すべての種類のシャードの割り当てを許可します。primaries- プライマリシャードのみの割り当てを許可します。new_primaries- 新しいインデックスのプライマリシャードのみの割り当てを許可します。none- すべてのインデックスに対して、いかなる種類のシャードの割り当ても許可されません。
この設定は、ノードを再起動する際にローカルプライマリシャードの回復には影響しません。 割り当てIDがクラスタ状態のアクティブな割り当てIDの1つと一致する場合、再起動されたノードは未割り当てのプライマリシャードのコピーを持っていると、そのプライマリを即座に回復します。
cluster.routing.allocation.same_shard.host- (動的)
trueの場合、同じホスト上の異なるノードにシャードの複数のコピーが割り当てられることを禁止します。つまり、同じネットワークアドレスを持つノードです。 デフォルトはfalseで、シャードのコピーが同じホストのノードに割り当てられることがあります。この設定は、各ホストで複数のノードを実行している場合にのみ関連します。 cluster.routing.allocation.node_concurrent_incoming_recoveries- (動的) ノードで許可される同時の受信シャード回復の数。 受信回復は、ターゲットシャード(シャードが移動していない限り、最も可能性が高いのはレプリカ)がノードに割り当てられる回復です。 デフォルトは
2です。この設定を増やすと、シャードの移動がクラスタ内の他のアクティビティにパフォーマンスの影響を与える可能性がありますが、シャードの移動が目に見えて早く完了することはありません。この設定を2のデフォルトから調整することはお勧めしません。 cluster.routing.allocation.node_concurrent_outgoing_recoveries- (動的) ノードで許可される同時の送信シャード回復の数。 送信回復は、ソースシャード(シャードが移動していない限り、最も可能性が高いのはプライマリ)がノードに割り当てられる回復です。 デフォルトは
2です。この設定を増やすと、シャードの移動がクラスタ内の他のアクティビティにパフォーマンスの影響を与える可能性がありますが、シャードの移動が目に見えて早く完了することはありません。この設定を2のデフォルトから調整することはお勧めしません。 cluster.routing.allocation.node_concurrent_recoveries- (動的)
cluster.routing.allocation.node_concurrent_incoming_recoveriesとcluster.routing.allocation.node_concurrent_outgoing_recoveriesの両方を設定するためのショートカットです。この設定の値は、より具体的な設定が構成されていない場合にのみ有効になります。 デフォルトは2です。この設定を増やすと、シャードの移動がクラスタ内の他のアクティビティにパフォーマンスの影響を与える可能性がありますが、シャードの移動が目に見えて早く完了することはありません。この設定を2のデフォルトから調整することはお勧めしません。 cluster.routing.allocation.node_initial_primaries_recoveries- (動的) レプリカの回復はネットワークを介して行われますが、ノードの再起動後の未割り当てプライマリの回復はローカルディスクのデータを使用します。 これらは迅速であるべきであり、各ノードでより多くの初期プライマリ回復が並行して行われることができます。 デフォルトは
4です。この設定を増やすと、シャードの回復がクラスタ内の他のアクティビティにパフォーマンスの影響を与える可能性がありますが、シャードの回復が目に見えて早く完了することはありません。この設定を4のデフォルトから調整することはお勧めしません。
シャード再バランス設定
クラスタは、各ノードに均等な数のシャードがあり、すべてのノードが均等なリソースを必要とし、任意のインデックスのシャードが任意のノードに集中していない場合にバランスされています。Elasticsearchは、クラスタ内のノード間でシャードを移動してバランスを改善する自動プロセスである再バランスを実行します。再バランスは、割り当てフィルタリングや強制認識などの他のすべてのシャード割り当てルールに従い、クラスタを完全にバランスさせることを妨げる可能性があります。その場合、再バランスは、構成したルール内で可能な限り最もバランスの取れたクラスタを達成することを目指します。データティアを使用している場合、Elasticsearchは自動的に割り当てフィルタリングルールを適用して、各シャードを適切なティア内に配置します。これらのルールにより、バランサーは各ティア内で独立して機能します。
次の設定を使用して、クラスタ全体のシャードの再バランスを制御できます:
cluster.routing.allocation.allow_rebalance- (動的) シャードの再バランスが許可されるタイミングを指定します:
always- 常に再バランスを許可します。indices_primaries_active- クラスタ内のすべてのプライマリが割り当てられている場合のみ。indices_all_active- (デフォルト) クラスタ内のすべてのシャード(プライマリとレプリカ)が割り当てられている場合のみ。
cluster.routing.rebalance.enable- (動的) 特定の種類のシャードの再バランスを有効または無効にします:
all- (デフォルト) すべての種類のシャードのバランスを許可します。primaries- プライマリシャードのみのバランスを許可します。replicas- レプリカシャードのみのバランスを許可します。none- いかなるインデックスに対してもシャードのバランスを許可しません。
再バランスは、障害後にクラスタが健康で完全に回復力のある状態に戻ることを保証するために重要です。この設定を調整する場合は、できるだけ早くallに戻すことを忘れないでください。
cluster.routing.allocation.cluster_concurrent_rebalance- (動的) クラスタ全体で許可される同時シャード再バランスの数を定義します。 デフォルトは
2です。この設定は、クラスタ内の不均衡による同時シャード移動の数のみを制御します。この設定は、割り当てフィルタリングや強制認識によるシャード移動を制限しません。この設定を増やすと、クラスタがノード間でシャードを移動するために追加のリソースを使用する可能性があるため、一般的には2のデフォルトからこの設定を調整することはお勧めしません。 cluster.routing.allocation.type- クラスタバランスを計算するために使用されるアルゴリズムを選択します。 デフォルトは
desired_balanceで、希望するバランスアロケーターを選択します。このアロケーターは、クラスタ内のシャードの希望するバランスを計算するバックグラウンドタスクを実行します。このバックグラウンドタスクが完了すると、Elasticsearchはシャードを希望する場所に移動します。
[8.8] 8.8で非推奨。balancedアロケータータイプは非推奨であり、もはや推奨されません。balancedに設定して、レガシーバランスアロケーターを選択することもできます。このアロケーターは、8.6.0以前のElasticsearchのバージョンでデフォルトのアロケーターでした。これは、フォアグラウンドで実行され、マスターが並行して他の作業を行うのを妨げます。これは、クラスタのバランスを即座に改善する少数のシャード移動を選択し、それらのシャード移動が完了すると再度実行され、別のいくつかのシャードを移動するように選択します。このアロケーターは、クラスタの現在の状態に基づいてのみ決定を行うため、クラスタのバランスを取る際にシャードを何度も移動することがあります。
シャードバランスのヒューリスティック設定
再バランスは、各ノードのシャードの割り当てに基づいて重みを計算し、重いノードの重みを減らし、軽いノードの重みを増やすためにシャードをノード間で移動することによって機能します。クラスタは、任意のノードの重みを他のノードの重みに近づけることができるシャードの移動がない場合にバランスが取れています。
ノードの重みは、保持しているシャードの数と、それらのシャードの総推定リソース使用量に依存します。リソース使用量は、ディスク上のシャードのサイズと、シャードへの書き込みトラフィックをサポートするために必要なスレッドの数で表されます。Elasticsearchは、ロールオーバーによって作成されたデータストリームに属するシャードのリソース使用量を推定します。新しいシャードの推定ディスクサイズは、データストリーム内の他のシャードの平均サイズです。新しいシャードの推定書き込み負荷は、データストリーム内の最近のシャードの実際の書き込み負荷の加重平均です。データストリームの書き込みインデックスに属さないシャードは、推定書き込み負荷がゼロです。
次の設定は、Elasticsearchがこれらの値を各ノードの重みの全体的な尺度に組み合わせる方法を制御します。
cluster.routing.allocation.balance.threshold- (float, 動的) 再バランスシャード移動をトリガーする重みの最小改善。 デフォルトは
1.0fです。この値を上げると、Elasticsearchはシャードの再バランスを早く停止し、クラスタをより不均衡な状態に置くことになります。 cluster.routing.allocation.balance.shard- (float, 動的) 各ノードに割り当てられたシャードの総数に対する重み係数を定義します。 デフォルトは
0.45fです。この値を上げると、Elasticsearchは他のバランス変数の前にノード間でシャードの総数を均等にする傾向が強くなります。 cluster.routing.allocation.balance.index- (float, 動的) 各ノードに割り当てられたインデックスごとのシャードの数に対する重み係数を定義します。 デフォルトは
0.55fです。この値を上げると、Elasticsearchは他のバランス変数の前にノード間で各インデックスのシャードの数を均等にする傾向が強くなります。 cluster.routing.allocation.balance.disk_usage- (float, 動的) シャードの予測ディスクサイズ(バイト単位)に基づいてシャードをバランスさせるための重み係数を定義します。 デフォルトは
2e-11fです。この値を上げると、Elasticsearchは他のバランス変数の前にノード間で総ディスク使用量を均等にする傾向が強くなります。 cluster.routing.allocation.balance.write_load(float, 動的) 各シャードの書き込み負荷に対する重み係数を、シャードによって必要とされる推定インデックススレッド数の観点で定義します。 デフォルトは
10.0fです。この値を上げると、Elasticsearchは他のバランス変数の前にノード間で総書き込み負荷を均等にする傾向が強くなります。大規模なクラスタを持っている場合、常に完全にバランスの取れた状態を維持する必要はないかもしれません。 完全なバランスを達成するために必要なすべてのシャード移動を実行するよりも、やや不均衡な状態でクラスタを運営する方がリソースを消費しません。 その場合、
cluster.routing.allocation.balance.thresholdの値を上げて、ノード間の許容可能な不均衡を定義します。 たとえば、各ノードに平均500シャードがあり、ノード間の差を5%(25の典型的なシャード)まで受け入れられる場合、cluster.routing.allocation.balance.thresholdを25に設定します。- ヒューリスティック重み係数設定の値を調整することはお勧めしません。 デフォルト値はすべての合理的なクラスタでうまく機能します。 異なる値が現在のバランスを改善する場合がありますが、将来的に予期しない問題を引き起こしたり、予期しない障害に対処するのを妨げたりする可能性があります。
- バランシングアルゴリズムの結果に関係なく、強制認識や割り当てフィルタリングなどの割り当てルールにより再バランスが許可されない場合があります。 現在のシャードの割り当てを説明するには、クラスタ割り当ての説明 APIを使用してください。
ディスクベースのシャード割り当て設定
ディスクベースのシャードアロケーターは、すべてのノードが十分なディスクスペースを持つことを保証し、必要以上のシャード移動を行わないようにします。 それは、低水準と高水準として知られる一対のしきい値に基づいてシャードを割り当てます。 主な目標は、ノードが高水準を超えないようにすること、またはそのような超過が一時的であることを保証することです。 ノードが高水準を超えた場合、Elasticsearchはこれを解決するために、クラスタ内の他のノードにいくつかのシャードを移動します。
ノードが一時的に高水準を超えることは正常です。
アロケーターは、低水準を超えるノードにさらにシャードを割り当てることを禁止することによって、ノードが高水準を超えないようにしようとします。 重要なのは、すべてのノードが低水準を超えた場合、新しいシャードを割り当てることができず、Elasticsearchはディスク使用量を高水準以下に保つためにノード間でシャードを移動できなくなることです。 クラスタ全体で十分なディスクスペースがあることを確認し、常にいくつかのノードが低水準以下であることを確認する必要があります。
ディスクベースのシャードアロケーターによってトリガーされたシャード移動は、割り当てフィルタリングや強制認識などの他のすべてのシャード割り当てルールを満たす必要があります。 これらのルールが厳しすぎる場合、ノードのディスク使用量を制御するために必要なシャード移動を妨げる可能性があります。 データティアを使用している場合、Elasticsearchは自動的に割り当てフィルタリングルールを構成して、シャードを適切なティア内に配置します。これは、ディスクベースのシャードアロケーターが各ティア内で独立して機能することを意味します。
ノードがElasticsearchが他の場所にシャードを移動できるよりも早くディスクを埋めている場合、ディスクが完全に埋まるリスクがあります。 これを防ぐために、最後の手段として、ディスク使用量が洪水段階のしきい値に達すると、Elasticsearchは影響を受けたノードにシャードを持つインデックスへの書き込みをブロックします。 また、クラスタ内の他のノードにシャードを移動し続けます。 影響を受けたノードのディスク使用量が高水準を下回ると、Elasticsearchは自動的に書き込みブロックを解除します。 永続的な水準エラーを解決するには、水準エラーの修正を参照してください。
クラスタ内のノードが非常に異なる量のディスクスペースを使用しているのは正常です。 クラスタのバランスは、各ノードのシャードの数、これらのシャードが属するインデックス、およびシャードのサイズやCPU使用量に関するリソースニーズを含む要因の組み合わせに依存します。 Elasticsearchはこれらの要因を相互にトレードオフする必要があり、これらの要因の組み合わせを見たときにバランスが取れているクラスタは、単一の要因に焦点を当てた場合にはバランスが取れていないように見えるかもしれません。
次の設定を使用して、ディスクベースの割り当てを制御できます:
cluster.routing.allocation.disk.threshold_enabled(動的) デフォルトは
trueです。 ディスク割り当て決定者を無効にするにはfalseに設定します。 無効にすると、既存のindex.blocks.read_only_allow_deleteインデックスブロックも削除されます。cluster.routing.allocation.disk.watermark.low
- (動的) ディスク使用量の低水準を制御します。 デフォルトは
85%で、Elasticsearchは85%のディスク使用量を超えるノードにシャードを割り当てません。 比率値(例:0.85)に設定することもできます。 また、指定された量のスペースが利用可能でない場合、シャードの割り当てを防ぐために絶対バイト値(500mbのように)に設定することもできます。この設定は、新しく作成されたインデックスのプライマリシャードには影響しませんが、そのレプリカの割り当てを防ぎます。 cluster.routing.allocation.disk.watermark.low.max_headroom(動的) 低水準の最大余裕を制御します(割合/比率値の場合)。 デフォルトは
cluster.routing.allocation.disk.watermark.lowが明示的に設定されていない場合、200GBです。 これは、必要な空きスペースの量を制限します。cluster.routing.allocation.disk.watermark.high
- (動的) 高水準を制御します。 デフォルトは
90%で、Elasticsearchは90%を超えるディスク使用量のノードからシャードを移動しようとします。 比率値(例:0.9)に設定することもできます。 また、指定された量の空きスペースがない場合、ノードからシャードを移動するために絶対バイト値(低水準と同様)に設定することもできます。この設定は、以前に割り当てられたかどうかにかかわらず、すべてのシャードの割り当てに影響します。 cluster.routing.allocation.disk.watermark.high.max_headroom- (動的) 高水準の最大余裕を制御します(割合/比率値の場合)。 デフォルトは
cluster.routing.allocation.disk.watermark.highが明示的に設定されていない場合、150GBです。 これは、必要な空きスペースの量を制限します。 cluster.routing.allocation.disk.watermark.enable_for_single_data_node(静的) 以前のリリースでは、割り当て決定を行う際に単一のデータノードクラスタのディスク水準を無視するのがデフォルトの動作でした。 これは7.14以降の非推奨の動作であり、8.0で削除されました。 この設定の有効な値は現在
trueのみです。 この設定は将来のリリースで削除される予定です。cluster.routing.allocation.disk.watermark.flood_stage - (動的) 洪水段階の水準を制御します。 デフォルトは95%です。 Elasticsearchは、影響を受けたノードに1つ以上のシャードが割り当てられているすべてのインデックスに対して読み取り専用インデックスブロック(
index.blocks.read_only_allow_delete)を強制し、洪水段階を超えるディスクを持つ少なくとも1つのディスクがあります。 この設定は、ノードがディスクスペースを使い果たすのを防ぐための最後の手段です。 ディスク使用量が高水準を下回ると、インデックスブロックは自動的に解除されます。 低水準および高水準の値と同様に、比率値(例:0.95)または絶対バイト値に設定することもできます。my-index-000001インデックスの読み取り専用インデックスブロックをリセットする例:
Python
resp = client.indices.put_settings(index="my-index-000001",settings={"index.blocks.read_only_allow_delete": None},)print(resp)
Ruby
response = client.indices.put_settings(index: 'my-index-000001',body: {'index.blocks.read_only_allow_delete' => nil})puts response
Js
const response = await client.indices.putSettings({index: "my-index-000001",settings: {"index.blocks.read_only_allow_delete": null,},});console.log(response);
Console
PUT /my-index-000001/_settings{"index.blocks.read_only_allow_delete": null}
cluster.routing.allocation.disk.watermark.flood_stage.max_headroom- (動的) 洪水段階の水準の最大余裕を制御します(割合/比率値の場合)。 デフォルトは
cluster.routing.allocation.disk.watermark.flood_stageが明示的に設定されていない場合、100GBです。 これは、必要な空きスペースの量を制限します。
cluster.routing.allocation.disk.watermark.low、cluster.routing.allocation.disk.watermark.high、cluster.routing.allocation.disk.watermark.flood_stage 設定間で割合/比率値とバイト値の使用を混在させることはできません。 すべての値が割合/比率値に設定されるか、すべてがバイト値に設定される必要があります。 この強制は、Elasticsearchが設定が内部的に一貫していることを検証できるようにし、低ディスクしきい値が高ディスクしきい値よりも小さく、高ディスクしきい値が洪水段階しきい値よりも小さいことを保証します。 最大余裕値についても同様の比較チェックが行われます。
cluster.routing.allocation.disk.watermark.flood_stage.frozen - (動的) 専用のフローズンノードの洪水段階の水準を制御します。 デフォルトは95%です。
cluster.routing.allocation.disk.watermark.flood_stage.frozen.max_headroom - (動的) 専用のフローズンノードの洪水段階の水準の最大余裕を制御します(割合/比率値の場合)。 デフォルトは
cluster.routing.allocation.disk.watermark.flood_stage.frozenが明示的に設定されていない場合、20GBです。 これは、専用のフローズンノードで必要な空きスペースの量を制限します。 cluster.info.update.interval- (動的) Elasticsearchがクラスタ内の各ノードのディスク使用量をチェックする頻度。 デフォルトは
30sです。
割合値は使用されたディスクスペースを指し、バイト値は空きディスクスペースを指します。 これは混乱を招く可能性があり、低と高の意味を反転させます。 たとえば、低水準を10GB、高水準を5GBに設定するのは理にかなっていますが、その逆は理にかなっていません。
低水準を少なくとも100ギガバイトの空き、少なくとも50ギガバイトの高水準、10ギガバイトの洪水段階の水準に更新し、クラスタに関する情報を毎分更新する例:
Python
resp = client.cluster.put_settings(persistent={"cluster.routing.allocation.disk.watermark.low": "100gb","cluster.routing.allocation.disk.watermark.high": "50gb","cluster.routing.allocation.disk.watermark.flood_stage": "10gb","cluster.info.update.interval": "1m"},)print(resp)
Ruby
response = client.cluster.put_settings(body: {persistent: {'cluster.routing.allocation.disk.watermark.low' => '100gb','cluster.routing.allocation.disk.watermark.high' => '50gb','cluster.routing.allocation.disk.watermark.flood_stage' => '10gb','cluster.info.update.interval' => '1m'}})puts response
Js
const response = await client.cluster.putSettings({persistent: {"cluster.routing.allocation.disk.watermark.low": "100gb","cluster.routing.allocation.disk.watermark.high": "50gb","cluster.routing.allocation.disk.watermark.flood_stage": "10gb","cluster.info.update.interval": "1m",},});console.log(response);
Console
PUT _cluster/settings{"persistent": {"cluster.routing.allocation.disk.watermark.low": "100gb","cluster.routing.allocation.disk.watermark.high": "50gb","cluster.routing.allocation.disk.watermark.flood_stage": "10gb","cluster.info.update.interval": "1m"}}
水準の最大余裕設定に関しては、これらは水準設定が割合/比率である場合にのみ適用されることに注意してください。 最大余裕値の目的は、各水準に達する前に必要な空きディスクスペースを制限することです。 これは、より大きなディスクを持つサーバーに特に便利であり、割合/比率の水準は大きな空きディスクスペースの要件に変換される可能性があり、最大余裕を使用して必要な空きディスクスペースの量を制限できます。 例として、洪水水準のデフォルト設定を考えてみましょう。 デフォルト値は95%で、洪水最大余裕設定のデフォルト値は100GBです。 これは、
- 小さなディスク(例:100GB)の場合、洪水水準は95%で、5GBの空きスペースでヒットします。 これは、5GBが100GBの最大余裕値よりも小さいためです。
- 大きなディスク(例:100TB)の場合、洪水水準は100GBの空きスペースでヒットします。 これは、95%の洪水水準だけでは5TBの空きディスクスペースが必要ですが、最大余裕設定によって100GBに制限されるからです。
最後に、最大余裕設定は、それぞれの水準設定が明示的に設定されていない場合にのみデフォルト値を持ちます(したがって、デフォルトの割合値を持ちます)。 水準が明示的に設定されている場合、最大余裕設定はデフォルト値を持たず、望ましい場合は明示的に設定する必要があります。
シャード割り当ての認識
カスタムノード属性を認識属性として使用して、Elasticsearchがシャードを割り当てる際に物理ハードウェア構成を考慮できるようにします。 Elasticsearchが同じ物理サーバー、同じラック、または同じゾーンにあるノードを知っている場合、プライマリシャードとそのレプリカシャードを分散させて、障害が発生した場合にすべてのシャードコピーを失うリスクを最小限に抑えることができます。
シャード割り当ての認識が、動的 cluster.routing.allocation.awareness.attributes 設定で有効になっている場合、シャードは指定された認識属性の値が設定されているノードにのみ割り当てられます。 複数の認識属性を使用する場合、Elasticsearchはシャードを割り当てる際に各属性を個別に考慮します。
属性値の数は、各場所に割り当てられるシャードコピーの数を決定します。 各場所のノード数が不均衡で、レプリカが多い場合、レプリカシャードが未割り当てのままになる可能性があります。
回復力のあるクラスタの設計について詳しく学んでください。
シャード割り当ての認識を有効にする
シャード割り当ての認識を有効にするには:
- 1. 各ノードの場所をカスタムノード属性で指定します。 たとえば、Elasticsearchが異なるラックにシャードを分散させるようにしたい場合、
rack_idという認識属性を使用することがあります。
カスタム属性は2つの方法で設定できます:elasticsearch.yml設定ファイルを編集することによって:
Yaml
node.attr.rack_id: rack_one
- ノードを起動するときに
-Eコマンドライン引数を使用します:./bin/elasticsearch -Enode.attr.rack_id=rack_one
- 2. シャードを割り当てる際に1つ以上の認識属性を考慮するようにElasticsearchに指示するには、すべてのマスター候補ノードの
elasticsearch.yml設定ファイルでcluster.routing.allocation.awareness.attributesを設定します。
Yaml
cluster.routing.allocation.awareness.attributes: rack_id
| 複数の属性をカンマ区切りのリストとして指定します。 |
cluster-update-settings APIを使用して、クラスタの認識属性を設定または更新することもできます:
Python
resp = client.cluster.put_settings(persistent={"cluster.routing.allocation.awareness.attributes": "rack_id"},)print(resp)
Ruby
response = client.cluster.put_settings(body: {persistent: {'cluster.routing.allocation.awareness.attributes' => 'rack_id'}})puts response
Js
const response = await client.cluster.putSettings({persistent: {"cluster.routing.allocation.awareness.attributes": "rack_id",},});console.log(response);
コンソール
PUT /_cluster/settings{"persistent" : {"cluster.routing.allocation.awareness.attributes" : "rack_id"}}
この例の設定では、node.attr.rack_id を rack_one に設定して2つのノードを起動し、5つのプライマリシャードと各プライマリの1つのレプリカを持つインデックスを作成すると、すべてのプライマリとレプリカが2つのノードに分配されます。
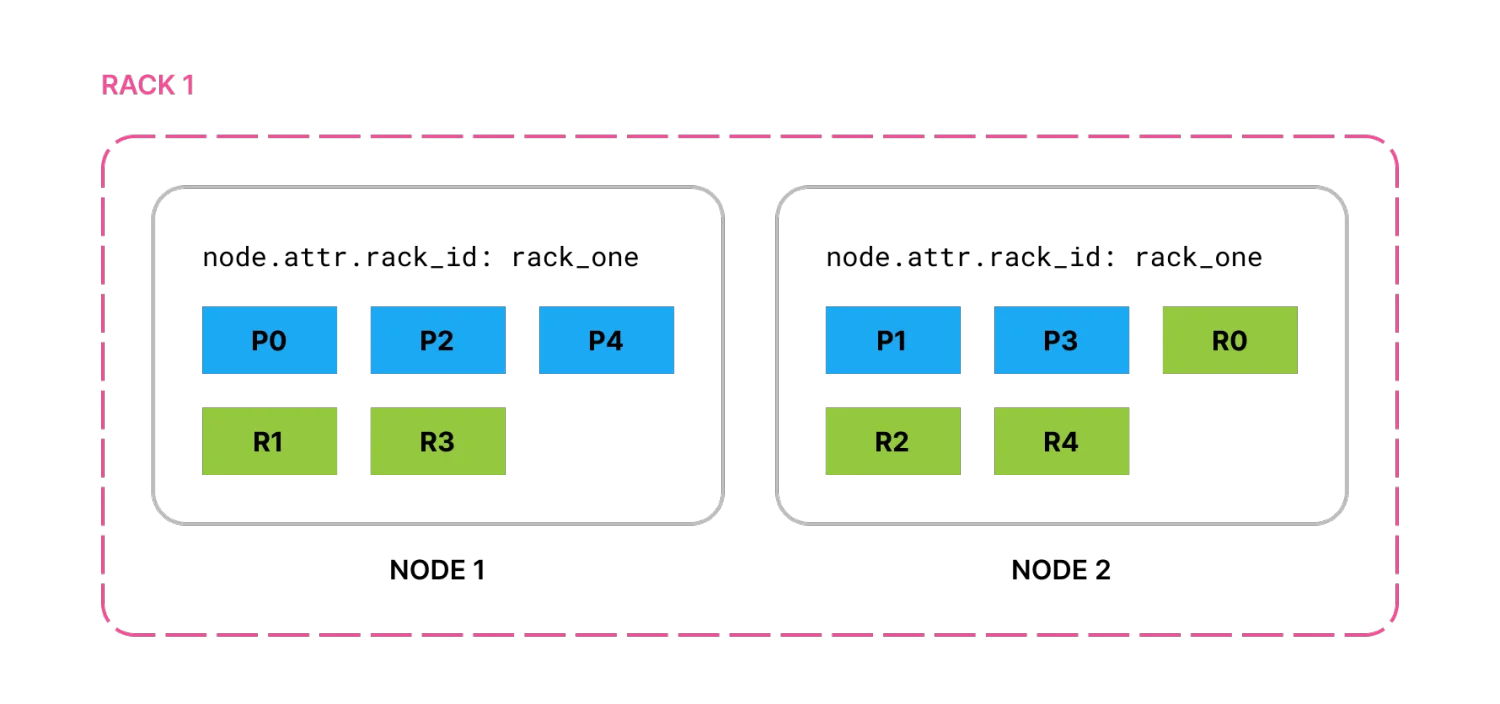
図1. 同じラックの2つのノードに分配されたすべてのプライマリとレプリカ
node.attr.rack_id を rack_two に設定した2つのノードを追加すると、Elasticsearch はシャードを新しいノードに移動し、可能であれば同じラックに同じシャードの2つのコピーが存在しないようにします。
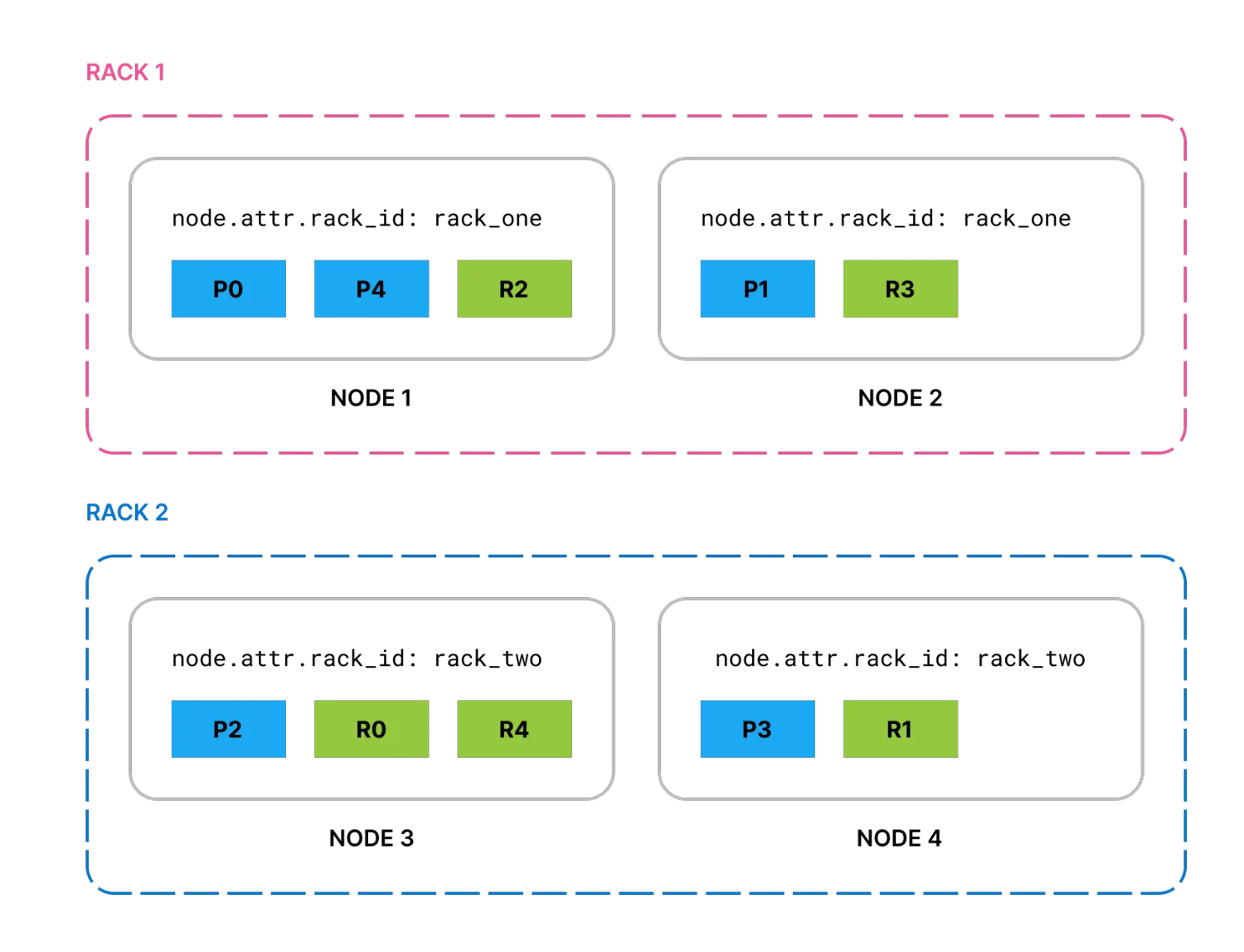
図2. 同じラックに同じシャードの2つのコピーが存在しない4つのノードに分配されたプライマリとレプリカ
rack_two が失敗し、そのノードの両方がダウンすると、デフォルトではElasticsearchは失われたシャードのコピーを rack_one のノードに割り当てます。特定のシャードの複数のコピーが同じ場所に割り当てられないようにするには、強制的な認識を有効にすることができます。
強制的な認識
デフォルトでは、1つの場所が失敗すると、Elasticsearch は残りの場所にシャードを分散させます。これは、1つの場所が欠けているときにクラスターがすべてのシャードをホストするのに十分なリソースを持っていない場合には望ましくないかもしれません。
全体の場所の障害が発生した場合に残りの場所が過負荷になるのを防ぐために、cluster.routing.allocation.awareness.force.* 設定で存在すべき属性値を指定します。これにより、Elasticsearch は全体の場所の障害が発生した場合に、残りの場所のノードを過負荷にする代わりに、一部のレプリカを未割り当てのままにすることを優先します。
たとえば、zone という認識属性があり、zone1 と zone2 にノードを設定している場合、強制的な認識を使用して、1つのゾーンしか利用できない場合にシャードコピーの半分を未割り当てのままにすることができます:
Yaml
cluster.routing.allocation.awareness.attributes: zonecluster.routing.allocation.awareness.force.zone.values: zone1,zone2
すべての可能な zone 属性値を指定します。 |
この例の設定では、node.attr.zone を zone1 に設定した2つのノードと、number_of_replicas を 1 に設定したインデックスがある場合、Elasticsearch はすべてのプライマリシャードを割り当てますが、レプリカは割り当てません。異なる node.attr.zone の値を持つノードがクラスターに参加すると、レプリカシャードが割り当てられます。対照的に、強制的な認識を設定しない場合、Elasticsearch は同じゾーンにあるにもかかわらず、すべてのプライマリとレプリカを2つのノードに割り当てます。
クラスター レベルのシャード割り当てフィルタリング
クラスター レベルのシャード割り当てフィルタを使用して、Elasticsearch が任意のインデックスからシャードをどこに割り当てるかを制御できます。これらのクラスター全体のフィルタは、インデックスごとの割り当てフィルタリング および 割り当て認識 と組み合わせて適用されます。
シャード割り当てフィルタは、カスタムノード属性または組み込みの _name、_host_ip、_publish_ip、_ip、_host、_id、および _tier 属性に基づくことができます。
cluster.routing.allocation 設定は 動的 であり、ライブインデックスを1つのノードセットから別のノードセットに移動できるようにします。シャードは、プライマリとレプリカシャードを同じノードに割り当てないなど、他のルーティング制約を破らない場合にのみ再配置されます。
クラスター レベルのシャード割り当てフィルタリングの最も一般的な使用例は、ノードを廃止したいときです。ノードをシャットダウンする前にシャードをノードから移動するには、IPアドレスでノードを除外するフィルタを作成できます:
Python
resp = client.cluster.put_settings(persistent={"cluster.routing.allocation.exclude._ip": "10.0.0.1"},)print(resp)
Ruby
response = client.cluster.put_settings(body: {persistent: {'cluster.routing.allocation.exclude._ip' => '10.0.0.1'}})puts response
Js
const response = await client.cluster.putSettings({persistent: {"cluster.routing.allocation.exclude._ip": "10.0.0.1",},});console.log(response);
コンソール
PUT _cluster/settings{"persistent" : {"cluster.routing.allocation.exclude._ip" : "10.0.0.1"}}
クラスター ルーティング設定
cluster.routing.allocation.include.{attribute}- (動的)
{attribute}にカンマ区切りの値のいずれかを持つノードにシャードを割り当てます。 cluster.routing.allocation.require.{attribute}- (動的)
{attribute}にカンマ区切りの値をすべて持つノードにのみシャードを割り当てます。 cluster.routing.allocation.exclude.{attribute}- (動的)
{attribute}にカンマ区切りの値のいずれかを持つノードにシャードを割り当てません。
クラスター割り当て設定は、次の組み込み属性をサポートしています:
_name |
ノード名でノードを一致させる |
_host_ip |
ホストIPアドレス(ホスト名に関連付けられたIP)でノードを一致させる |
_publish_ip |
公開IPアドレスでノードを一致させる |
_ip |
_host_ip または _publish_ip のいずれかで一致させる |
_host |
ホスト名でノードを一致させる |
_id |
ノードIDでノードを一致させる |
_tier |
ノードの データティア の役割でノードを一致させる |
_tier フィルタリングは ノード の役割に基づいています。役割のサブセットのみが データティア の役割であり、一般的な データ役割 は任意のティアフィルタリングに一致します。属性値を指定する際にワイルドカードを使用できます。たとえば:
Python
resp = client.cluster.put_settings(persistent={"cluster.routing.allocation.exclude._ip": "192.168.2.*"},)print(resp)
Ruby
response = client.cluster.put_settings(body: {persistent: {'cluster.routing.allocation.exclude._ip' => '192.168.2.*'}})puts response
Js
const response = await client.cluster.putSettings({persistent: {"cluster.routing.allocation.exclude._ip": "192.168.2.*",},});console.log(response);
コンソール
PUT _cluster/settings{"persistent": {"cluster.routing.allocation.exclude._ip": "192.168.2.*"}}
