データノードのディスク使用量を減少させる
クラスター内のディスク使用量をデータを失うことなく減少させるために、インデックスのレプリカを減らすことを試みることができます。
インデックスのレプリカを減らすことで、検索スループットとデータの冗長性を減少させる可能性があります。しかし、より恒久的な解決策が整うまで、クラスターに呼吸の余地を与えることができます。
Kibanaを使用する
- 1. Elastic Cloudコンソールにログインします。
- 2. Elasticsearch Serviceパネルで、デプロイメントの名前をクリックします。
デプロイメントの名前が無効になっている場合、Kibanaインスタンスが正常でない可能性があります。その場合は、Elastic Supportに連絡してください。デプロイメントにKibanaが含まれていない場合は、最初に有効にするだけで済みます。 - 3. デプロイメントのサイドナビゲーションメニュー(左上のElasticロゴの下に配置されています)を開き、Stack Management > Index Managementに移動します。
- 4. すべてのインデックスのリストで、
Replicas列を2回クリックして、レプリカの数に基づいてインデックスをソートします。最も多くのレプリカを持つインデックスから始めます。インデックスを確認し、重要度が低く、レプリカの数が多いインデックスを1つずつ選択します。
インデックスのレプリカを減らすことで、検索スループットとデータの冗長性を減少させる可能性があります。 - 5. 選択した各インデックスの名前をクリックし、表示されるパネルで
Edit settingsをクリックし、index.number_of_replicasの値を希望の値に減少させてからSaveをクリックします。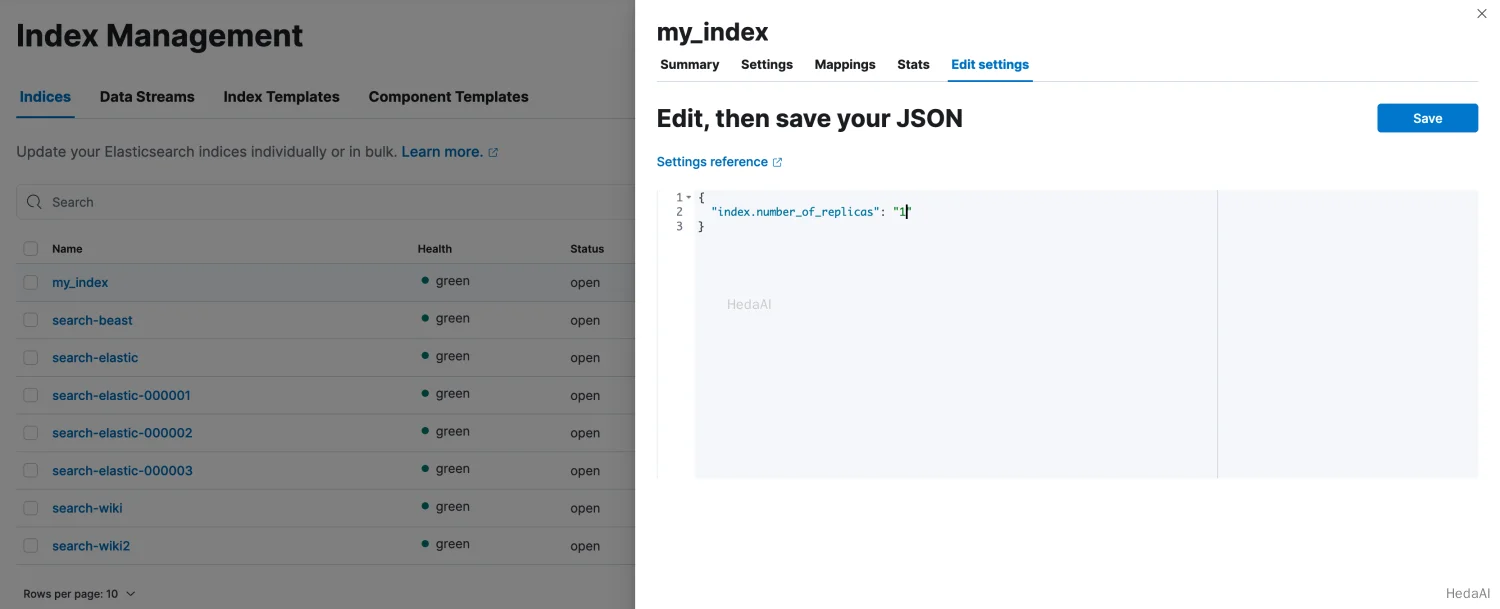
- 6. クラスターが再び正常になるまでこのプロセスを続けます。
削除する必要のあるレプリカの数を見積もるためには、まず解放する必要のあるディスクスペースの量を見積もる必要があります。
- 1. 最初に、どれだけのスペースを解放する必要があるかを示す関連するディスクの閾値を取得します。関連する閾値は、凍結されたものを除くすべての層の高水準と、凍結層の凍結洪水段階の水準です。以下の例は、ホット層でのディスク不足を示しているため、高水準のみを取得します。
Python
resp = client.cluster.get_settings(include_defaults=True,filter_path="*.cluster.routing.allocation.disk.watermark.high*",)print(resp)
Ruby
response = client.cluster.get_settings(include_defaults: true,filter_path: '*.cluster.routing.allocation.disk.watermark.high*')puts response
Js
const response = await client.cluster.getSettings({include_defaults: "true",filter_path: "*.cluster.routing.allocation.disk.watermark.high*",});console.log(response);
Console
GET _cluster/settings?include_defaults&filter_path=*.cluster.routing.allocation.disk.watermark.high*
Console-Result
{"defaults": {"cluster": {"routing": {"allocation": {"disk": {"watermark": {"high": "90%","high.max_headroom": "150GB"}}}}}}}
上記は、ディスク不足を解決するために、ディスク使用量を90%未満にするか、150GB以上の空き容量を持つ必要があることを意味します。この閾値の動作については、こちらで詳しく読むことができます。
- 2. 次のステップは、現在のディスク使用量を確認することです。これにより、どれだけのスペースを解放する必要があるかが示されます。簡単のために、私たちの例では1つのノードがありますが、関連する閾値を超えるすべてのノードに同じことを適用できます。
Python
resp = client.cat.allocation(v=True,s="disk.avail",h="node,disk.percent,disk.avail,disk.total,disk.used,disk.indices,shards",)print(resp)
Ruby
response = client.cat.allocation(v: true,s: 'disk.avail',h: 'node,disk.percent,disk.avail,disk.total,disk.used,disk.indices,shards')puts response
Js
const response = await client.cat.allocation({v: "true",s: "disk.avail",h: "node,disk.percent,disk.avail,disk.total,disk.used,disk.indices,shards",});console.log(response);
Console
GET _cat/allocation?v&s=disk.avail&h=node,disk.percent,disk.avail,disk.total,disk.used,disk.indices,shards
Console-Result
node disk.percent disk.avail disk.total disk.used disk.indices shardsinstance-0000000000 91 4.6gb 35gb 31.1gb 29.9gb 111
- 3. 高水準の設定は、ディスク使用量が90%未満に下がる必要があることを示しています。ノードが近い将来に閾値を超えないように、ある程度の余裕を持たせることを検討してください。この例では、約7GBを解放します。
- 4. 次のステップは、すべてのインデックスをリストし、どのレプリカを減らすかを選択することです。
次のコマンドは、レプリカの数とプライマリストレージサイズが降順でインデックスを並べ替えます。これは、レプリカが多いほど、コピーを削除した場合のリスクが小さく、レプリカが大きいほど解放されるスペースが大きくなるという仮定の下で、どのレプリカを減らすかを選択するのに役立ちます。これは、機能要件を考慮していないため、あくまで提案としてご覧ください。
Python
resp = client.cat.indices(v=True,s="rep:desc,pri.store.size:desc",h="health,index,pri,rep,store.size,pri.store.size",)print(resp)
Ruby
response = client.cat.indices(v: true,s: 'rep:desc,pri.store.size:desc',h: 'health,index,pri,rep,store.size,pri.store.size')puts response
Js
const response = await client.cat.indices({v: "true",s: "rep:desc,pri.store.size:desc",h: "health,index,pri,rep,store.size,pri.store.size",});console.log(response);
Console
GET _cat/indices?v&s=rep:desc,pri.store.size:desc&h=health,index,pri,rep,store.size,pri.store.size
Console-Result
health index pri rep store.size pri.store.sizegreen my_index 2 3 9.9gb 3.3gbgreen my_other_index 2 3 1.8gb 470.3mbgreen search-products 2 3 278.5kb 69.6kbgreen logs-000001 1 0 7.7gb 7.7gb
- 5. 上記のリストでは、インデックス
my_indexとmy_other_indexのレプリカを1に減らすと、必要なディスクスペースが解放されることがわかります。search-productsのレプリカを減らす必要はなく、logs-000001にはそもそもレプリカがありません。 インデックス更新設定APIを使用して、1つまたは複数のインデックスのレプリカを減らします:
インデックスのレプリカを減らすことで、検索スループットとデータの冗長性を減少させる可能性があります。
Python
resp = client.indices.put_settings(index="my_index,my_other_index",settings={"index.number_of_replicas": 1},)print(resp)
Ruby
response = client.indices.put_settings(index: 'my_index,my_other_index',body: {'index.number_of_replicas' => 1})puts response
Js
const response = await client.indices.putSettings({index: "my_index,my_other_index",settings: {"index.number_of_replicas": 1,},});console.log(response);
Console
PUT my_index,my_other_index/_settings{"index.number_of_replicas": 1}
