データ層
データ層は、同じデータ役割を持つノードのコレクションで、通常は同じハードウェアプロファイルを共有します:
- コンテンツ層ノードは、製品カタログなどのコンテンツのインデックス作成とクエリ負荷を処理します。
- ホット層ノードは、ログやメトリクスなどの時系列データのインデックス作成負荷を処理し、最も最近の、最も頻繁にアクセスされるデータを保持します。
- ウォーム層ノードは、あまり頻繁にアクセスされず、更新がほとんど必要ない時系列データを保持します。
- コールド層ノードは、あまり頻繁にアクセスされず、通常は更新されない時系列データを保持します。スペースを節約するために、コールド層に完全にマウントされたインデックスの検索可能なスナップショットを保持できます。これらの完全にマウントされたインデックスは、レプリカの必要性を排除し、通常のインデックスと比較して必要なディスクスペースを約50%削減します。
- フローズン層ノードは、あまり頻繁にアクセスされず、決して更新されない時系列データを保持します。フローズン層は、部分的にマウントされたインデックスの検索可能なスナップショットのみを保存します。これにより、ストレージ容量がさらに拡張され、ウォーム層と比較して最大20倍になります。
Elasticsearchノードのパフォーマンスは、しばしば基盤となるストレージのパフォーマンスによって制限されます。インデックス作成および検索のためにストレージを最適化するための推奨事項を確認してください。
Elasticsearchは、一般的にデータ層内のノードが同じハードウェアプロファイルを共有することを期待しています。この推奨に従わないバリエーションは、ホットスポットを避けるために慎重に設計する必要があります。
特定のインデックスに直接ドキュメントをインデックス作成すると、それらは無期限にコンテンツ層ノードに残ります。
データストリームにドキュメントをインデックス作成すると、最初はホット層ノードに存在します。インデックスライフサイクル管理(ILM)ポリシーを構成して、パフォーマンス、耐障害性、およびデータ保持要件に応じて、時系列データをホット、ウォーム、コールド層に自動的に移行させることができます。
コンテンツ層
コンテンツ層に保存されているデータは、一般的に製品カタログや記事アーカイブなどのアイテムのコレクションです。時系列データとは異なり、コンテンツの価値は時間とともに比較的一定であるため、年齢が増すにつれて異なるパフォーマンス特性を持つ層に移動させることは意味がありません。コンテンツデータは通常、長期間のデータ保持要件を持ち、アイテムがどれだけ古くても迅速に取得できることを望みます。
コンテンツ層ノードは通常、クエリパフォーマンスの最適化が行われており、IOスループットよりも処理能力を優先して、複雑な検索や集計を処理し、迅速に結果を返すことができます。インデックス作成も担当していますが、コンテンツデータは通常、ログやメトリクスなどの時系列データほど高いレートで取り込まれることはありません。耐障害性の観点から、この層のインデックスは1つ以上のレプリカを使用するように構成する必要があります。
コンテンツ層は必須です。システムインデックスおよびデータストリームの一部でない他のインデックスは、自動的にコンテンツ層に割り当てられます。
ホット層
ホット層は、時系列データのElasticsearchエントリーポイントであり、最も最近の、最も頻繁に検索される時系列データを保持します。ホット層のノードは、読み取りと書き込みの両方で高速である必要があり、これにはより多くのハードウェアリソースと高速ストレージ(SSD)が必要です。耐障害性のために、ホット層のインデックスは1つ以上のレプリカを使用するように構成する必要があります。
ホット層は必須です。データストリームの一部である新しいインデックスは、自動的にホット層に割り当てられます。
ウォーム層
時系列データは、ホット層の最近インデックスされたデータよりも頻繁にクエリされなくなった場合、ウォーム層に移動できます。ウォーム層は通常、最近の数週間のデータを保持します。更新はまだ許可されていますが、頻繁ではない可能性があります。ウォーム層のノードは、ホット層のノードほど高速である必要はありません。耐障害性のために、ウォーム層のインデックスは1つ以上のレプリカを使用するように構成する必要があります。
コールド層
時系列データを定期的に検索する必要がなくなった場合、それはウォーム層からコールド層に移動できます。この層はまだ検索可能ですが、通常は検索速度よりも低いストレージコストに最適化されています。
より良いストレージの節約のために、コールド層に完全にマウントされたインデックスの検索可能なスナップショットを保持できます。通常のインデックスとは異なり、これらの完全にマウントされたインデックスは、信頼性のためにレプリカを必要としません。障害が発生した場合、基盤となるスナップショットからデータを回復できます。これにより、データに必要なローカルストレージが半分になる可能性があります。コールド層で完全にマウントされたインデックスを使用するには、スナップショットリポジトリが必要です。完全にマウントされたインデックスは読み取り専用です。
代わりに、コールド層を使用してレプリカを持つ通常のインデックスを保存することもできます。これにより、古いデータをより安価なハードウェアに保存できますが、ウォーム層と比較して必要なディスクスペースは削減されません。
フローズン層
データがもはやクエリされない、またはまれにクエリされる場合、それはコールド層からフローズン層に移動し、その後の生涯をそこで過ごします。
フローズン層にはスナップショットリポジトリが必要です。フローズン層は、スナップショットリポジトリからデータを保存およびロードするために部分的にマウントされたインデックスを使用します。これにより、ローカルストレージと運用コストが削減され、フローズンデータを検索することができます。Elasticsearchは時々フローズンデータをスナップショットリポジトリから取得する必要があるため、フローズン層での検索は通常、コールド層での検索よりも遅くなります。
Elasticsearch ServiceまたはElastic Cloud Enterpriseでのデータ層の構成
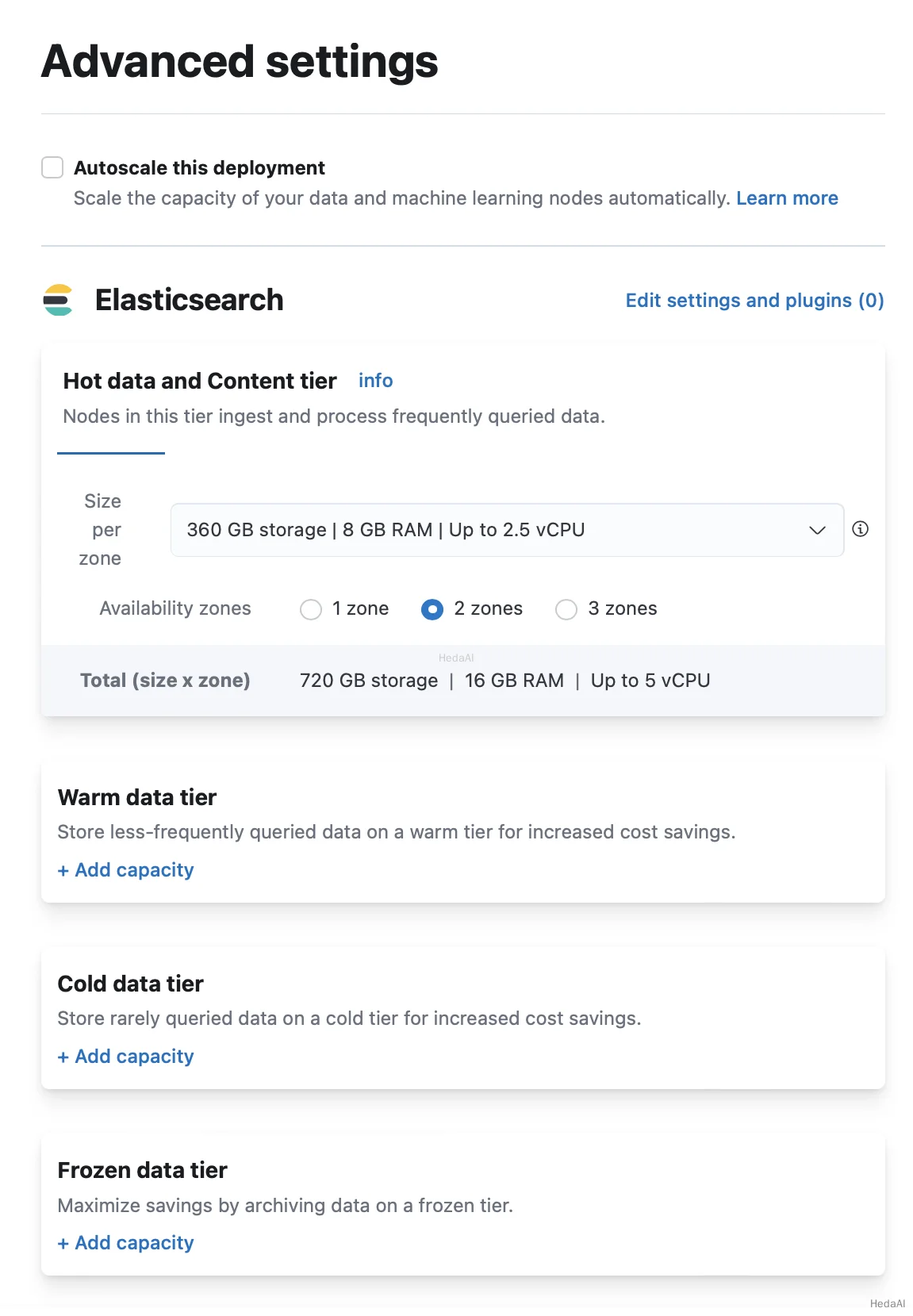
Elastic Cloudデプロイメントのデフォルト構成には、ホットデータとコンテンツデータのための共有層が含まれています。この層は必須であり、削除することはできません。
デプロイメントを作成するときにウォーム、コールド、またはフローズン層を追加するには:
- 1. デプロイメントの作成ページで、高度な設定をクリックします。
- 2. 追加するデータ層のために+ キャパシティを追加をクリックします。
3. ページの下部でデプロイメントを作成をクリックして、変更を保存します。
既存のデプロイメントにデータ層を追加するには:
- 1. Elastic Cloudコンソールにログインします。
- 2. デプロイメントページで、デプロイメントを選択します。
- 3. デプロイメントメニューで、編集を選択します。
- 4. 追加するデータ層のために+ キャパシティを追加をクリックします。
- 5. ページの下部で保存をクリックして、変更を保存します。
データ層を削除するには、データ層を無効にするを参照してください。
自己管理デプロイメントのデータ層の構成
自己管理デプロイメントでは、各ノードのデータ役割がelasticsearch.ymlで構成されています。たとえば、クラスター内の最高性能のノードは、ホット層とコンテンツ層の両方に割り当てられる場合があります:
Yaml
node.roles: ["data_hot", "data_content"]
フローズン層では専用ノードの使用を推奨します。
データ層インデックスの割り当て
インデックスを作成すると、デフォルトでElasticsearchはindex.routing.allocation.include._tier_preferenceをdata_contentに設定して、インデックスシャードをコンテンツ層に自動的に割り当てます。
Elasticsearchがデータストリームの一部としてインデックスを作成すると、デフォルトでElasticsearchはindex.routing.allocation.include._tier_preferenceをdata_hotに設定して、インデックスシャードをホット層に自動的に割り当てます。
デフォルトの層ベースの割り当てをオプトアウトするには、index.routing.allocation.include._tier_preferenceを明示的に設定できます。
自動データ層移行
ILMは、migrateアクションを使用して、管理されたインデックスを利用可能なデータ層間で自動的に移行します。デフォルトでは、このアクションはすべてのフェーズに自動的に注入されます。自動移行を無効にするために、"enabled": falseでmigrateアクションを明示的に指定できます。たとえば、allocate actionを使用して割り当てルールを手動で指定する場合です。
