for i in /sys/devices/system/cpu/cpu[0-7]
do
echo performance
$i/cpufreq/scaling_governor
done
#
``````
私たちは Hundtのベンチマークプログラム をC++とGoで取り込み、それぞれを単一のソースファイルに結合し、出力の1行を除いてすべてを削除しました。プログラムの実行時間をLinuxの time ユーティリティを使用して、ユーザー時間、システム時間、実時間、最大メモリ使用量を表示する形式で測定します:
$ cat xtime#!/bin/sh/usr/bin/time -f '%Uu %Ss %er %MkB %C' "$@"$$ make havlak1ccg++ -O3 -o havlak1cc havlak1.cc$ ./xtime ./havlak1cc# of loops: 76002 (total 3800100)loop-0, nest: 0, depth: 017.70u 0.05s 17.80r 715472kB ./havlak1cc$$ make havlak1go build havlak1.go$ ./xtime ./havlak1# of loops: 76000 (including 1 artificial root node)25.05u 0.11s 25.20r 1334032kB ./havlak1$
C++プログラムは17.80秒で実行され、700 MBのメモリを使用します。Goプログラムは25.20秒で実行され、1302 MBのメモリを使用します。(これらの測定値は論文のものと一致させるのが難しいですが、この投稿の目的は go tool pprof の使用方法を探ることであり、論文の結果を再現することではありません。)
Goプログラムのチューニングを開始するには、プロファイリングを有効にする必要があります。コードが Goテストパッケージ のベンチマークサポートを使用している場合、gotestの標準 -cpuprofile および -memprofile フラグを使用できます。このようなスタンドアロンプログラムでは、runtime/pprof をインポートし、いくつかのコード行を追加する必要があります:
var cpuprofile = flag.String("cpuprofile", "", "write cpu profile to file")func main() {flag.Parse()if *cpuprofile != "" {f, err := os.Create(*cpuprofile)if err != nil {log.Fatal(err)}pprof.StartCPUProfile(f)defer pprof.StopCPUProfile()}...
新しいコードは cpuprofile という名前のフラグを定義し、Goフラグライブラリ を呼び出してコマンドラインフラグを解析し、cpuprofile フラグがコマンドラインで設定されている場合、CPUプロファイリングを開始 し、そのファイルにリダイレクトします。プロファイラは、プログラムが終了する前にファイルへの保留中の書き込みをフラッシュするために StopCPUProfile への最終呼び出しを必要とします。defer を使用して、main が戻るときにこれが発生することを確認します。
そのコードを追加した後、新しい -cpuprofile フラグでプログラムを実行し、go tool pprof を実行してプロファイルを解釈できます。
$ make havlak1.prof./havlak1 -cpuprofile=havlak1.prof# of loops: 76000 (including 1 artificial root node)$ go tool pprof havlak1 havlak1.profpprofへようこそ! ヘルプが必要な場合は、'help'と入力してください。(pprof)
go tool pprof プログラムは Googleの pprof C++プロファイラ のわずかなバリアントです。最も重要なコマンドは topN で、プロファイル内の上位 N サンプルを表示します:
(pprof) top10Total: 2525 samples298 11.8% 11.8% 345 13.7% runtime.mapaccess1_fast64268 10.6% 22.4% 2124 84.1% main.FindLoops251 9.9% 32.4% 451 17.9% scanblock178 7.0% 39.4% 351 13.9% hash_insert131 5.2% 44.6% 158 6.3% sweepspan119 4.7% 49.3% 350 13.9% main.DFS96 3.8% 53.1% 98 3.9% flushptrbuf95 3.8% 56.9% 95 3.8% runtime.aeshash6495 3.8% 60.6% 101 4.0% runtime.settype_flush88 3.5% 64.1% 988 39.1% runtime.mallocgc
CPUプロファイリングが有効になっていると、Goプログラムは1秒あたり約100回停止し、現在実行中のgoroutineのスタック上のプログラムカウンタからなるサンプルを記録します。プロファイルには2525サンプルがあり、したがって25秒以上実行されていました。go tool pprof 出力には、サンプルに現れた各関数の行があります。最初の2列は、関数が実行中であったサンプルの数(呼び出された関数が戻るのを待っているのではなく)、生のカウントと総サンプルのパーセンテージとして表示されます。runtime.mapaccess1_fast64 関数は298サンプル中、つまり11.8%の間実行されていました。top10 出力はこのサンプルカウントでソートされています。3列目はリスト中の合計を示します: 最初の3行はサンプルの32.4%を占めています。4列目と5列目は、関数が現れたサンプルの数(実行中または呼び出された関数が戻るのを待っている)を示します。main.FindLoops 関数は10.6%のサンプルで実行されていましたが、84.1%のサンプルでコールスタックにありました(それまたはそれが呼び出した関数が実行中でした)。
4列目と5列目でソートするには、-cum(累積用)フラグを使用します:
(pprof) top5 -cumTotal: 2525 samples0 0.0% 0.0% 2144 84.9% gosched00 0.0% 0.0% 2144 84.9% main.main0 0.0% 0.0% 2144 84.9% runtime.main0 0.0% 0.0% 2124 84.1% main.FindHavlakLoops268 10.6% 10.6% 2124 84.1% main.FindLoops(pprof) top5 -cum
実際、main.FindLoops と main.main の合計は100%であるべきですが、各スタックサンプルには下部100スタックフレームのみが含まれています。サンプルの約4分の1の間、再帰的な main.DFS 関数は main.main よりも100フレーム以上深くなっていたため、完全なトレースが切り捨てられました。
スタックトレースサンプルには、テキストリストでは表示できない関数呼び出し関係に関するより興味深いデータが含まれています。web コマンドは、プロファイルデータのグラフをSVG形式で書き込み、ウェブブラウザで開きます。(gv コマンドもあり、PostScriptを書き込み、Ghostviewで開きます。どちらのコマンドでも、graphviz がインストールされている必要があります。)
(pprof) web
完全なグラフ の小さな断片は次のようになります:
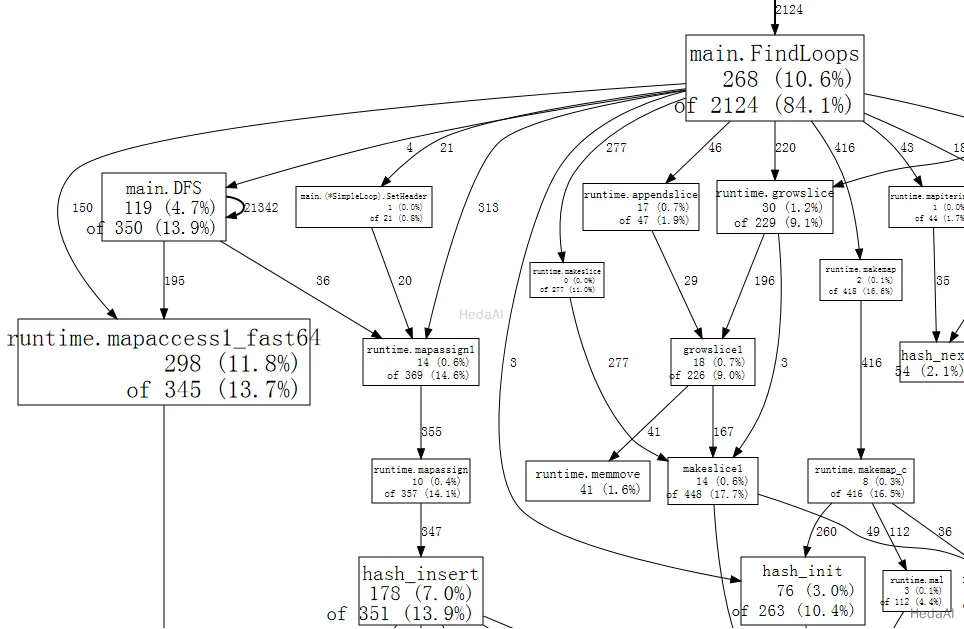
グラフ内の各ボックスは単一の関数に対応し、ボックスのサイズはその関数が実行されていたサンプルの数に応じて決まります。ボックスXからボックスYへのエッジは、XがYを呼び出すことを示します; エッジ上の数は、その呼び出しがサンプルに現れる回数です。サンプル内で呼び出しが複数回現れる場合、再帰的な関数呼び出しのように、各出現はエッジの重みにカウントされます。これが、main.DFS から自身への自己エッジの21342を説明します。
一目で見ると、プログラムはGoの map 値の使用に対応するハッシュ操作に多くの時間を費やしていることがわかります。web に特定の関数(例えば runtime.mapaccess1_fast64)を含むサンプルのみを使用するように指示できます。これにより、グラフからいくつかのノイズが除去されます:
(pprof) web mapaccess1
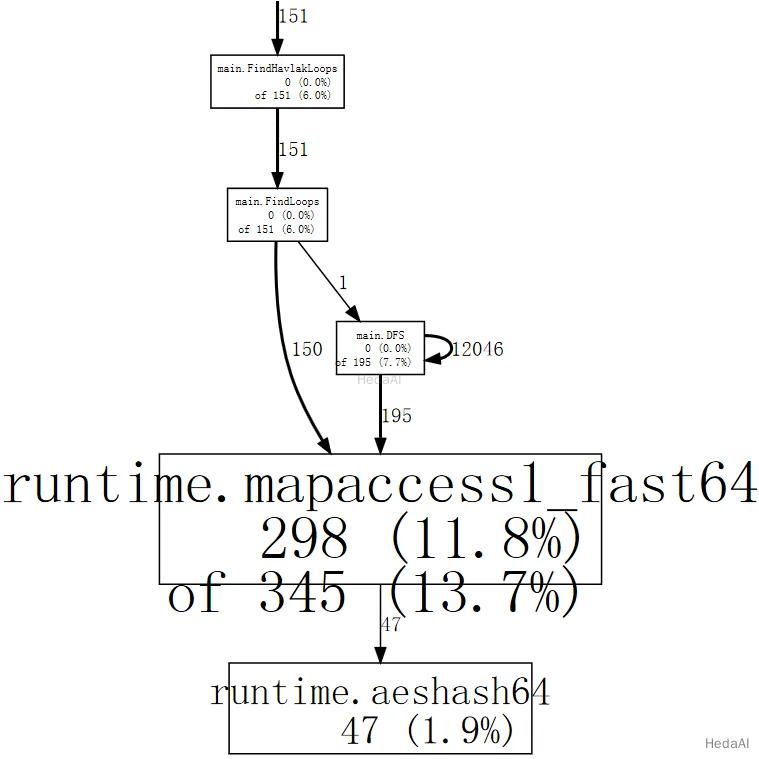
目を細めると、runtime.mapaccess1_fast64 への呼び出しが main.FindLoops と main.DFS によって行われていることがわかります。
全体像がわかったので、特定の関数にズームインする時が来ました。まず main.DFS を見てみましょう。短い関数だからです:
(pprof) list DFSTotal: 2525 samplesROUTINE ====================== main.DFS in /home/rsc/g/benchgraffiti/havlak/havlak1.go119 697 Total samples (flat / cumulative)3 3 240: func DFS(currentNode *BasicBlock, nodes []*UnionFindNode, number map[*BasicBlock]int, last []int, current int) int {1 1 241: nodes[current].Init(currentNode, current)1 37 242: number[currentNode] = current. . 243:1 1 244: lastid := current89 89 245: for _, target := range currentNode.OutEdges {9 152 246: if number[target] == unvisited {7 354 247: lastid = DFS(target, nodes, number, last, lastid+1). . 248: }. . 249: }7 59 250: last[number[currentNode]] = lastid1 1 251: return lastid(pprof)
リストには DFS 関数のソースコードが表示されます(実際には、正規表現 DFS に一致するすべての関数のためのものです)。最初の3列は、その行を実行している間に取得されたサンプルの数、その行を実行している間またはその行から呼び出されたコードで取得されたサンプルの数、ファイル内の行番号です。関連するコマンド disasm は、ソースリストの代わりに関数の逆アセンブリを表示します; サンプルが十分にある場合、これによりどの命令が高コストであるかを確認できます。weblist コマンドは、2つのモードを混合します: クリックすると逆アセンブリが表示されるソースリスト を表示します。
すでにハッシュランタイム関数によって実装されたマップのルックアップに時間がかかっていることがわかっているので、私たちは2列目に最も関心があります。再帰呼び出しに多くの時間が費やされていることがわかります DFS(行247)、再帰的トラバーサルから予想されるように。再帰を除外すると、242、246、250行の number マップへのアクセスに時間がかかっているようです。その特定のルックアップに対して、マップは最も効率的な選択肢ではありません。コンパイラと同様に、基本ブロック構造には一意のシーケンス番号が割り当てられています。map[*BasicBlock]int を使用する代わりに、ブロック番号でインデックス付けされた []int を使用できます。配列やスライスで十分な場合にマップを使用する理由はありません。
number をマップからスライスに変更するには、プログラム内の7行を編集する必要があり、実行時間をほぼ2倍に短縮しました:
$ make havlak2go build havlak2.go$ ./xtime ./havlak2# of loops: 76000 (including 1 artificial root node)16.55u 0.11s 16.69r 1321008kB ./havlak2$
プロファイラを再度実行して、main.DFS がもはや実行時間の重要な部分ではないことを確認できます:
$ make havlak2.prof./havlak2 -cpuprofile=havlak2.prof# of loops: 76000 (including 1 artificial root node)$ go tool pprof havlak2 havlak2.profpprofへようこそ! ヘルプが必要な場合は、'help'と入力してください。(pprof)(pprof) top5合計: 1652サンプル197 11.9% 11.9% 382 23.1% scanblock189 11.4% 23.4% 1549 93.8% main.FindLoops130 7.9% 31.2% 152 9.2% sweepspan104 6.3% 37.5% 896 54.2% runtime.mallocgc98 5.9% 43.5% 100 6.1% flushptrbuf(pprof)
エントリ main.DFS はもはやプロファイルに表示されず、プログラムの残りの実行時間も減少しました。現在、プログラムはメモリを割り当て、ガーベジコレクションを行うのにほとんどの時間を費やしています(runtime.mallocgc はメモリを割り当て、定期的なガーベジコレクションを実行するため、54.2%の時間を占めています)。ガーベジコレクタがこれほど多く実行されている理由を知るためには、メモリを割り当てているものを見つける必要があります。1つの方法は、プログラムにメモリプロファイリングを追加することです。-memprofile フラグが指定された場合、プログラムはループ探索の1回の反復後に停止し、メモリプロファイルを書き込み、終了します:
var memprofile = flag.String("memprofile", "", "write memory profile to this file")...FindHavlakLoops(cfgraph, lsgraph)if *memprofile != "" {f, err := os.Create(*memprofile)if err != nil {log.Fatal(err)}pprof.WriteHeapProfile(f)f.Close()return}
-memprofile フラグを使用してプログラムを呼び出します:
$ make havlak3.mprofgo build havlak3.go./havlak3 -memprofile=havlak3.mprof$
go tool pprof をまったく同じ方法で使用します。現在、私たちが調べているサンプルは、時計のティックではなくメモリ割り当てです。
$ go tool pprof havlak3 havlak3.mprofAdjusting heap profiles for 1-in-524288 sampling rateWelcome to pprof! For help, type 'help'.(pprof) top5Total: 82.4 MB56.3 68.4% 68.4% 56.3 68.4% main.FindLoops17.6 21.3% 89.7% 17.6 21.3% main.(*CFG).CreateNode8.0 9.7% 99.4% 25.6 31.0% main.NewBasicBlockEdge0.5 0.6% 100.0% 0.5 0.6% itab0.0 0.0% 100.0% 0.5 0.6% fmt.init(pprof)
コマンド go tool pprof は、FindLoops が使用中の約56.3 MBのうち、約56.3 MBを割り当てたことを報告します; CreateNode はさらに17.6 MBを占めます。オーバーヘッドを減らすために、メモリプロファイラは約半メガバイト割り当てられたブロックごとに約1つの情報のみを記録します(「524288サンプリングレートの1」)、したがってこれらは実際のカウントの近似値です。
メモリ割り当てを見つけるために、これらの関数をリストできます。
(pprof) list FindLoopsTotal: 82.4 MBROUTINE ====================== main.FindLoops in /home/rsc/g/benchgraffiti/havlak/havlak3.go56.3 56.3 Total MB (flat / cumulative)...1.9 1.9 268: nonBackPreds := make([]map[int]bool, size)5.8 5.8 269: backPreds := make([][]int, size). . 270:1.9 1.9 271: number := make([]int, size)1.9 1.9 272: header := make([]int, size, size)1.9 1.9 273: types := make([]int, size, size)1.9 1.9 274: last := make([]int, size, size)1.9 1.9 275: nodes := make([]*UnionFindNode, size, size). . 276:. . 277: for i := 0; i < size; i++ {9.5 9.5 278: nodes[i] = new(UnionFindNode). . 279: }.... . 286: for i, bb := range cfgraph.Blocks {. . 287: number[bb.Name] = unvisited29.5 29.5 288: nonBackPreds[i] = make(map[int]bool). . 289: }...
現在のボトルネックは、前回と同じであるようです: より単純なデータ構造が十分な場合にマップを使用すること。FindLoops は約29.5 MBのマップを割り当てています。
ちなみに、go tool pprof を --inuse_objects フラグで実行すると、サイズの代わりに割り当てカウントを報告します:
$ go tool pprof --inuse_objects havlak3 havlak3.mprofAdjusting heap profiles for 1-in-524288 sampling rateWelcome to pprof! For help, type 'help'.(pprof) list FindLoopsTotal: 1763108 objectsROUTINE ====================== main.FindLoops in /home/rsc/g/benchgraffiti/havlak/havlak3.go720903 720903 Total objects (flat / cumulative).... . 277: for i := 0; i < size; i++ {311296 311296 278: nodes[i] = new(UnionFindNode). . 279: }. . 280:. . 281: // Step a:. . 282: // - initialize all nodes as unvisited.. . 283: // - depth-first traversal and numbering.. . 284: // - unreached BB's are marked as dead.. . 285: //. . 286: for i, bb := range cfgraph.Blocks {. . 287: number[bb.Name] = unvisited409600 409600 288: nonBackPreds[i] = make(map[int]bool). . 289: }...(pprof)
約200,000のマップが29.5 MBを占めているため、初期のマップ割り当ては約150バイトかかるようです。これは、マップがキーと値のペアを保持するために使用される場合は合理的ですが、単純なセットの代わりにマップが使用される場合は合理的ではありません。
マップの代わりに、要素をリストするために単純なスライスを使用できます。マップが使用されているほとんどのケースでは、アルゴリズムが重複要素を挿入することは不可能です。残りの1つのケースでは、append 組み込み関数の単純なバリアントを書くことができます:
func appendUnique(a []int, x int) []int {for _, y := range a {if x == y {return a}}return append(a, x)}
この関数を書くことに加えて、Goプログラムをマップの代わりにスライスを使用するように変更するには、数行のコードを変更するだけで済みます。
$ make havlak4go build havlak4.go$ ./xtime ./havlak4# of loops: 76000 (including 1 artificial root node)11.84u 0.08s 11.94r 810416kB ./havlak4$
私たちは今、開始時よりも2.11倍速くなっています。再度CPUプロファイルを見てみましょう。
$ make havlak4.prof./havlak4 -cpuprofile=havlak4.prof# of loops: 76000 (including 1 artificial root node)$ go tool pprof havlak4 havlak4.profpprofへようこそ! ヘルプが必要な場合は、'help'と入力してください。(pprof) top10合計: 1173サンプル205 17.5% 17.5% 1083 92.3% main.FindLoops138 11.8% 29.2% 215 18.3% scanblock88 7.5% 36.7% 96 8.2% sweepspan76 6.5% 43.2% 597 50.9% runtime.mallocgc75 6.4% 49.6% 78 6.6% runtime.settype_flush74 6.3% 55.9% 75 6.4% flushptrbuf64 5.5% 61.4% 64 5.5% runtime.memmove63 5.4% 66.8% 524 44.7% runtime.growslice51 4.3% 71.1% 51 4.3% main.DFS50 4.3% 75.4% 146 12.4% runtime.MCache_Alloc(pprof)
現在、メモリ割り当てとそれに伴うガーベジコレクション(runtime.mallocgc)は、私たちの実行時間の50.9%を占めています。システムがガーベジコレクションを行っている理由を理解する別の方法は、コレクションを引き起こしている割り当てを見て、mallocgc で最も多くの時間を費やしているものを確認することです:
(pprof) web mallocgc
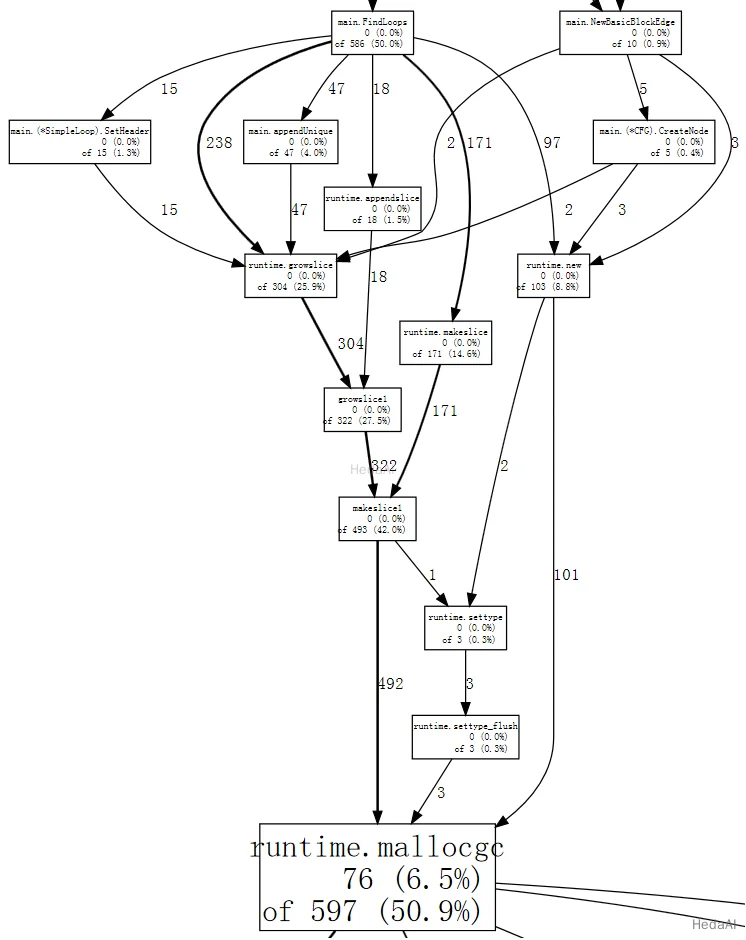
そのグラフで何が起こっているのかを判断するのは難しいですが、多くのノードが小さなサンプル数で大きなものを隠しています。go tool pprof に、サンプルの少なくとも10%を占めないノードを無視するように指示できます:
$ go tool pprof --nodefraction=0.1 havlak4 havlak4.profWelcome to pprof! For help, type 'help'.(pprof) web mallocgc
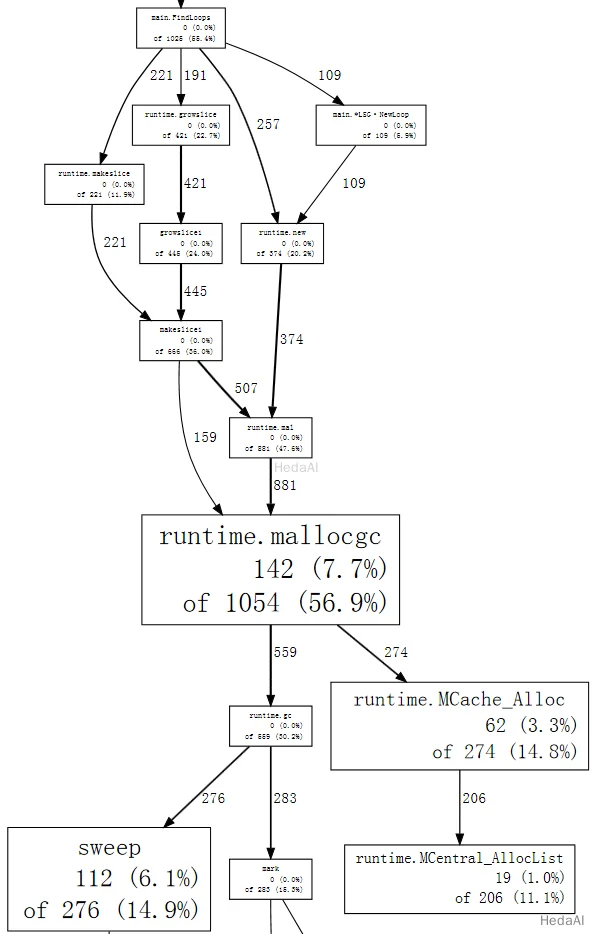
今、太い矢印を簡単に追うことができ、FindLoops がほとんどのガーベジコレクションを引き起こしていることがわかります。FindLoops をリストすると、その多くが最初にあることがわかります:
(pprof) list FindLoops.... . 270: func FindLoops(cfgraph *CFG, lsgraph *LSG) {. . 271: if cfgraph.Start == nil {. . 272: return. . 273: }. . 274:. . 275: size := cfgraph.NumNodes(). . 276:. 145 277: nonBackPreds := make([][]int, size). 9 278: backPreds := make([][]int, size). . 279:. 1 280: number := make([]int, size). 17 281: header := make([]int, size, size). . 282: types := make([]int, size, size). . 283: last := make([]int, size, size). . 284: nodes := make([]*UnionFindNode, size, size). . 285:. . 286: for i := 0; i < size; i++ {2 79 287: nodes[i] = new(UnionFindNode). . 288: }...(pprof)
FindLoops が呼び出されるたびに、いくつかの大きなブックキーピング構造が割り当てられます。ベンチマークが FindLoops を50回呼び出すため、これらはかなりの量のガーベジを追加し、ガーベジコレクタにとってかなりの作業になります。
ガーベジコレクションされた言語を持つことは、メモリ割り当ての問題を無視できることを意味しません。この場合、簡単な解決策は、各 FindLoops の呼び出しが可能な限り前の呼び出しのストレージを再利用するようにキャッシュを導入することです。(実際、Hundtの論文では、Javaプログラムが合理的なパフォーマンスを得るためにこの変更が必要だったと説明していますが、他のガーベジコレクションされた実装では同じ変更を行いませんでした。)
グローバル cache 構造体を追加します:
var cache struct {size intnonBackPreds [][]intbackPreds [][]intnumber []intheader []inttypes []intlast []intnodes []*UnionFindNode}
そして FindLoops が割り当ての代わりにそれを参照するようにします:
if cache.size < size {cache.size = sizecache.nonBackPreds = make([][]int, size)cache.backPreds = make([][]int, size)cache.number = make([]int, size)cache.header = make([]int, size)cache.types = make([]int, size)cache.last = make([]int, size)cache.nodes = make([]*UnionFindNode, size)for i := range cache.nodes {cache.nodes[i] = new(UnionFindNode)}}nonBackPreds := cache.nonBackPreds[:size]for i := range nonBackPreds {nonBackPreds[i] = nonBackPreds[i][:0]}backPreds := cache.backPreds[:size]for i := range nonBackPreds {backPreds[i] = backPreds[i][:0]}number := cache.number[:size]header := cache.header[:size]types := cache.types[:size]last := cache.last[:size]nodes := cache.nodes[:size]
このようなグローバル変数は、もちろん悪いエンジニアリングプラクティスです: それは、FindLoops への同時呼び出しがもはや安全でないことを意味します。今のところ、私たちはプログラムのパフォーマンスにとって重要なことを理解するために最小限の変更を行っています; この変更は簡単で、Java実装のコードを反映しています。最終版のGoプログラムは、このメモリを追跡するために別の LoopFinder インスタンスを使用し、同時使用の可能性を復元します。
$ make havlak5go build havlak5.go$ ./xtime ./havlak5# of loops: 76000 (including 1 artificial root node)8.03u 0.06s 8.11r 770352kB ./havlak5$
プログラムをクリーンアップして速くするためにできることはまだありますが、そのすべてはすでに示したプロファイリング技術を必要としません。内部ループで使用される作業リストは、反復間および FindLoops への呼び出し間で再利用できます。また、そのパス中に生成された別の「ノードプール」と組み合わせることができます。同様に、ループグラフストレージは、再割り当てするのではなく、各反復で再利用できます。これらのパフォーマンス変更に加えて、最終版 は、イディオマティックなGoスタイルを使用して、データ構造とメソッドを使用して書かれています。スタイルの変更は実行時間にわずかな影響を与えます: アルゴリズムと制約は変更されていません。
最終版は2.29秒で実行され、351 MBのメモリを使用します:
$ make havlak6go build havlak6.go$ ./xtime ./havlak6# of loops: 76000 (including 1 artificial root node)2.26u 0.02s 2.29r 360224kB ./havlak6$
それは、私たちが始めたプログラムよりも11倍速いです。生成されたループグラフの再利用を無効にしても、キャッシュされたメモリがループ探索のブックキーピングだけである場合でも、プログラムは元のものよりも6.7倍速く、1.5倍少ないメモリを使用します。
$ ./xtime ./havlak6 -reuseloopgraph=false# of loops: 76000 (including 1 artificial root node)3.69u 0.06s 3.76r 797120kB ./havlak6 -reuseloopgraph=false$
もちろん、set のような非効率的なデータ構造を使用している元のC++プログラムとこのGoプログラムを比較するのはもはや公平ではありません。サニティチェックとして、最終Goプログラムを同等のC++コードに翻訳しました。その実行時間はGoプログラムのものと似ています:
$ make havlak6ccg++ -O3 -o havlak6cc havlak6.cc$ ./xtime ./havlak6cc# of loops: 76000 (including 1 artificial root node)1.99u 0.19s 2.19r 387936kB ./havlak6cc
GoプログラムはC++プログラムとほぼ同じ速さで実行されます。C++プログラムは明示的なキャッシュの代わりに自動削除と割り当てを使用しているため、C++プログラムは少し短く、書きやすいですが、劇的ではありません:
$ wc havlak6.cc; wc havlak6.go401 1220 9040 havlak6.cc461 1441 9467 havlak6.go$
(havlak6.cc と havlak6.go を参照)
ベンチマークは、測定するプログラムと同じくらい良いです。私たちは go tool pprof を使用して非効率的なGoプログラムを研究し、その後、パフォーマンスを桁違いに改善し、メモリ使用量を3.7倍削減しました。同等に最適化されたC++プログラムとの比較は、プログラマが内部ループによって生成されるガーベジの量に注意すれば、GoがC++と競争できることを示しています。
プログラムのソース、Linux x86-64バイナリ、およびこの投稿を書くために使用されたプロファイルは、GitHubのbenchgraffitiプロジェクト で入手できます。
上記のように、go test にはすでにこれらのプロファイリングフラグが含まれています: ベンチマーク関数 を定義すれば、すべてが整います。プロファイリングデータへの標準HTTPインターフェースもあります。HTTPサーバーでは、
import _ "net/http/pprof"
を追加すると、/debug/pprof/ の下にいくつかのURLのハンドラがインストールされます。次に、go tool pprof を単一の引数—サーバーのプロファイリングデータのURLで実行すると、ライブプロファイルをダウンロードして調べます。
go tool pprof http://localhost:6060/debug/pprof/profile # 30-second CPU profilego tool pprof http://localhost:6060/debug/pprof/heap # heap profilego tool pprof http://localhost:6060/debug/pprof/block # goroutine blocking profile
ゴルーチンのブロッキングプロファイルは、今後の投稿で説明されます。お楽しみに。

{kind=link}